
Nous avons testé une variété de configurations, de tailles d’objets et de comptes de travailleurs clients afin de maximiser le débit d’un cluster Ceph à sept nœuds pour les charges de travail d’objets de petite et de grande taille. Comme détaillé dans le premier article, le cluster Ceph a été construit à l’aide d’un seul OSD (périphérique de stockage d’objets) configuré par disque dur, avec un total de 112 OSD par cluster Ceph. Dans cet article, nous allons comprendre les performances de pointe pour différentes tailles d’objets et charges de travail.
Remarque: Les termes « lire » et HTTP GET sont utilisés de manière interchangeable tout au long de cet article, tout comme les termes HTTP PUT et « écrire. »
Charge de travail de gros objets
Les charges de travail d’entrées/sorties séquentielles (E/S) de gros objets sont l’un des cas d’utilisation les plus courants pour le stockage d’objets Ceph. Ces charges de travail à haut débit comprennent l’analyse de Big Data, les systèmes de sauvegarde et d’archivage, le stockage d’images et la diffusion audio et vidéo en continu. Pour ces types de charges de travail, le débit (Mo/s ou Go/s) est la mesure clé qui définit les performances de stockage.
Comme indiqué dans le graphique 1, la charge de travail HTTP GET et HTTP PUT à 100% de gros objets présentait une évolutivité sous-linéaire lors de l’incrémentation du nombre d’hôtes RGW. En tant que tels, nous avons mesuré une bande passante agrégée d’environ 5,5 Gbit / s pour les charges de travail HTTP GET et HTTP PUT et, fait intéressant, nous n’avons pas remarqué de saturation des ressources dans les nœuds de cluster Ceph.
Ce cluster peut générer plus si nous pouvons lui diriger plus de charge. Nous avons donc identifié deux façons de le faire. 1) Ajoutez plus de nœuds clients 2) Ajoutez plus de nœuds RGW. Nous ne pouvions pas opter pour l’option 1 car nous étions limités par les nœuds clients physiques disponibles dans ce laboratoire. Nous avons donc opté pour l’option 2 et avons effectué une autre série de tests mais cette fois avec 14 RGWs.
Comme le montre le graphique 2, par rapport au test 7 RGW, le test 14 RGW a donné des performances d’écriture 14% plus élevées, dépassant ~ 6,3 Gbps, de même, la charge de travail HTTP GET a montré des performances de lecture 16% plus élevées, dépassant ~ 6,5GBps. Il s’agissait du débit agrégé maximal observé sur ce cluster, après quoi la saturation des supports (HDD) a été remarquée, comme illustré à la figure 1. Sur la base des résultats, nous pensons que si nous avions ajouté plus de nœuds OSD Ceph à ce cluster, les performances auraient pu être encore plus étendues, jusqu’à ce qu’elles soient limitées par la saturation des ressources.
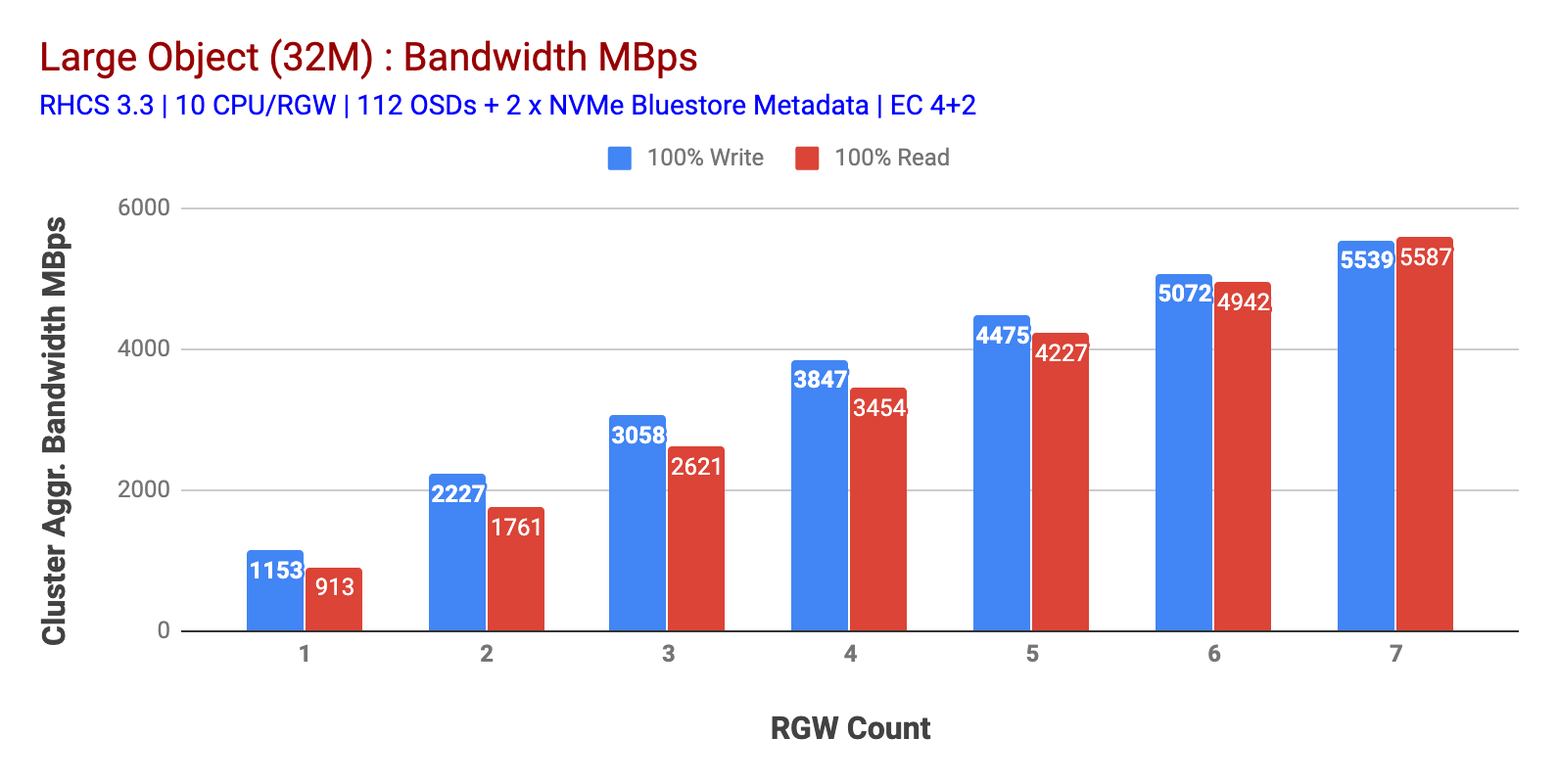
Graphique 1: Test de Gros Objets
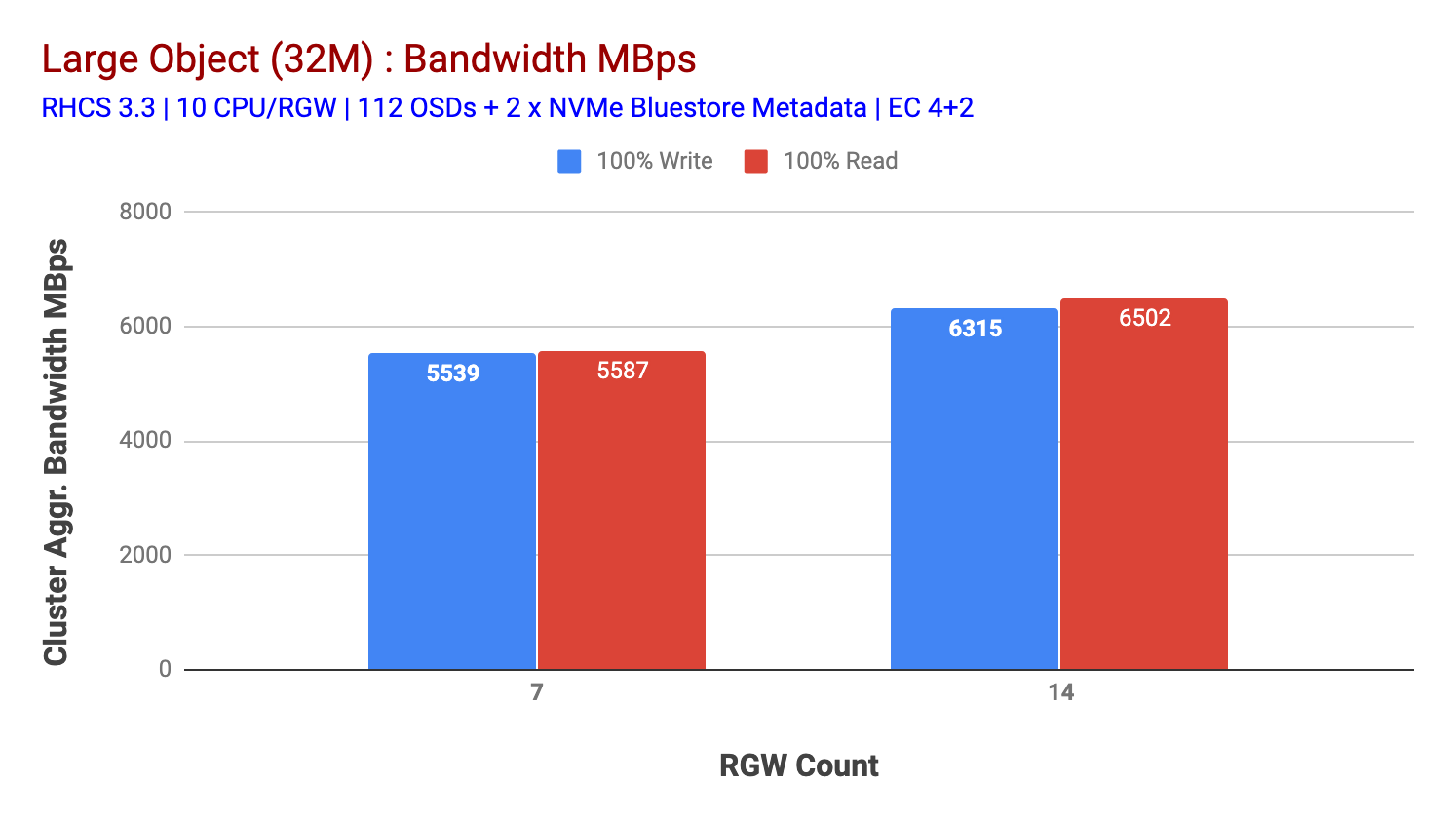
Graphique 2: Test de Gros Objets avec 14 RGWs
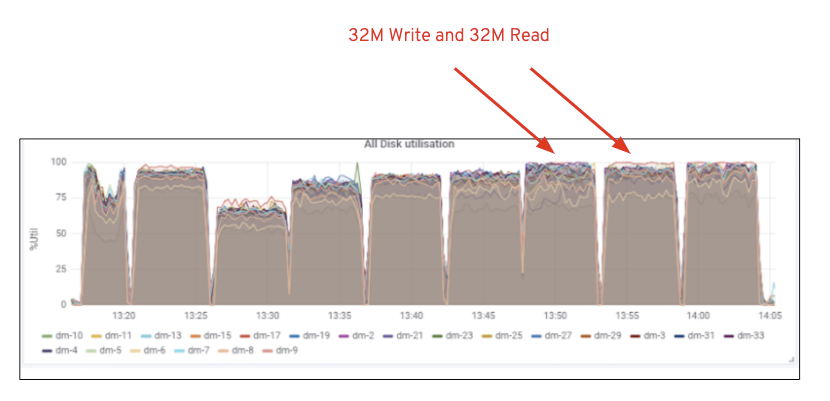
Figure 1: Utilisation des supports Ceph OSD (HDD)
Charge de travail de petits objets
Comme indiqué dans le graphique 3 les charges de travail HTTP GET et HTTP PUT à 100% de petits objets présentaient une évolutivité sous-linéaire lors de l’incrémentation du nombre d’hôtes RGW. En tant que tels, nous avons mesuré un débit Ops de ~ 6,2 K pour HTTP AVEC une latence d’écriture d’application de 9 ms et des Ops de ~ 3,2 K pour les charges de travail HTTP GET avec 7 instances RGW.
Jusqu’à 7 instances RGW, nous n’avons pas remarqué de saturation des ressources, nous avons donc doublé les instances RGW en les mettant à 14 et observé des performances dégradées pour la charge de travail HTTP PUT qui est attribuée à la saturation des médias, tandis que les performances HTTP GET sont augmentées et plafonnées à ~ 4,5 K Ops. En tant que tel, les performances d’écriture auraient pu être plus élevées si nous avions ajouté plus de nœuds OSD Ceph. En ce qui concerne les performances de lecture, nous pensons que l’ajout de nœuds clients aurait dû l’améliorer, mais nous n’avions plus de nœuds physiques en laboratoire pour tester cette hypothèse.
Une autre observation intéressante du graphique 3 est la réduction du temps de réponse moyen pour les charges de travail HTTP PUT qui mesuraient 9 ms tandis que HTTP GET affichait 17 ms de latence moyenne mesurée à partir de la charge de travail génératrice de l’application. Nous pensons que l’une des raisons de la latence d’application à un chiffre pour la charge de travail d’écriture est la combinaison de l’amélioration des performances provenant du backend OSD BlueStore ainsi que de la haute performance Intel Optane NVMe utilisée pour sauvegarder le périphérique de métadonnées BlueStore. Il convient de noter que la latence moyenne en écriture à un chiffre à partir d’un système de stockage d’objets n’est pas triviale. Comme illustré dans le graphique 3, le stockage d’objets Ceph lorsqu’il est déployé avec le backend OSD BlueStore et Intel Optane pour les métadonnées peut atteindre le débit d’écriture à un temps de réponse inférieur.
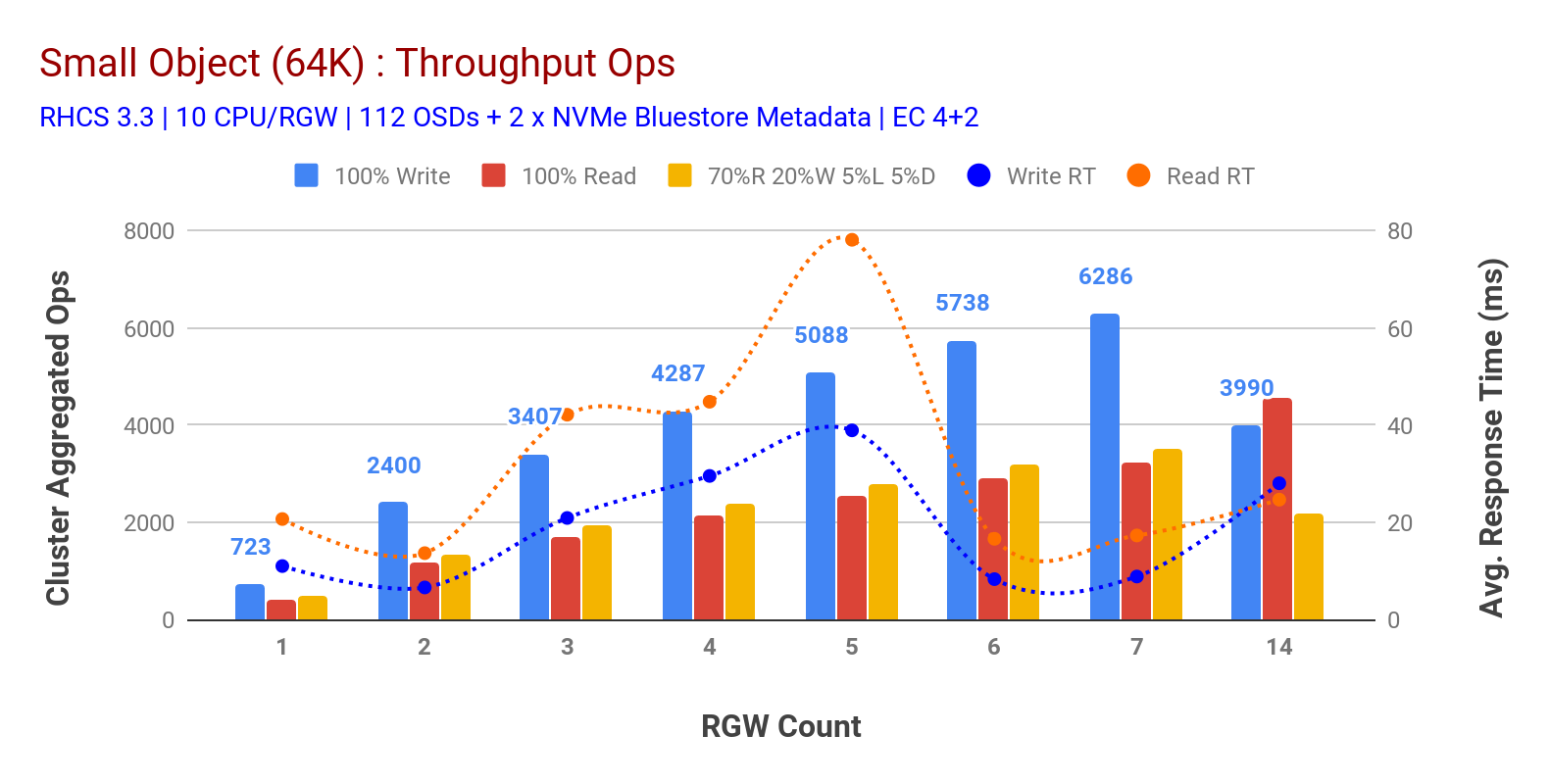
Graphique 3:Test de petits objets
Résumé et suivant
Le cluster de taille fixe utilisé dans ce test a fourni une large bande passante d’objets de ~ 6,3 Gbps et ~ 6,5GBps pour les charges de travail en écriture et en lecture respectivement. Le même cluster pour la petite taille d’objet a fourni ~6,5 K Ops et ~ 4,5K Ops pour la charge de travail en écriture et en lecture, respectivement.
Les résultats ont également montré que BlueStore OSD en combinaison avec Intel Optane NVMe a fourni une latence moyenne d’application à un chiffre, ce qui n’est pas trivial pour les systèmes de stockage d’objets. Dans le prochain article, nous explorerons les performances associées au partage dynamique de godets et comment le godet de pré-partage peut aider aux performances déterministes.