
Fonctionnalité
Voici une liste des fonctionnalités de base de MDF:
-
Recherche de structures chimiques: Les recherches de structure chimique peuvent être combinées avec des recherches de propriétés
-
Les recherches de structure chimique sont paginées et mises en cache
-
Prise en charge des composés multi-composants (mélanges)
-
3 entités interrogeables sur la structure chimique: ChimicalCompound, Containable et ChemicalCompoundContainer
-
Importation et exportation de fichiers SD pour les 3 entités ci-dessus
-
Accès à la base de données transactionnelle
-
Sécurité optionnelle (autorisation)
Avec la conception et la fonctionnalité de MDF, il est possible de construire de nombreux types de systèmes différents tels que des systèmes d’enregistrement, des systèmes d’inventaire ou simplement une simple base de données composée. Bien que vous puissiez également créer votre propre ELN, il existe également l’ELN Indigo gratuit. Cet ELN a été créé par GGA Software Services et est utilisé chez Pfizer.
Contrairement à MolDB5R et à MyMolDB, MDF n’est pas une application Web autonome entièrement fonctionnelle avec recherche de structure chimique. Comme son nom l’indique, c’est un framework pour simplifier la création d’une telle application. MDF peut également être utilisé pour créer des applications de bureau locales ou client-serveur. MDF s’adresse aux développeurs de logiciels et n’est pas destiné à être utilisé par les scientifiques eux-mêmes. Cependant, les caractéristiques du MDF sont très robustes. La recherche de structure chimique se fait dans la base de données et non dans le code de l’application. Par conséquent, vous pouvez rechercher par structure chimique et d’autres propriétés en même temps, les résultats peuvent être triés par plusieurs propriétés et peuvent être paginés (clauses SQL OFFSET et LIMIT). Notez que si vous effectuez la recherche de structure chimique dans le code de l’application, toute requête nécessitera au moins deux accès à la base de données, à savoir la recherche de structure et ensuite le filtrage par d’autres propriétés, le tri et / ou la limitation. Les deux doivent se produire dans la même transaction. Il n’a pas été déterminé si MolDB5R et MyMolDB le font réellement dans la même transaction.
Dans le MDF, les composés chimiques peuvent être associés à un contenant, qui dans les systèmes d’enregistrement serait un lot ou dans un système d’inventaire beaucoup. Un échantillon spécifique physiquement disponible dans une bouteille à code à barres peut alors être associé à un récipient. Ces conteneurs peuvent également être recherchés par structure chimique. C’est la base de la création d’un système d’inventaire. Les développeurs peuvent ajouter autant de propriétés supplémentaires qu’ils le souhaitent à chacune des entités et toutes sont consultables avec la structure chimique.
Tous les accès aux données dans MDF sont transactionnels pour éviter les incohérences de données. MDF peut être configuré pour utiliser un pool de connexions de base de données. Lors de l’interrogation d’un SGBDR, la création d’une connexion prend souvent plus de temps que la requête elle-même et, par conséquent, si vous avez déjà des connexions ouvertes, les temps de réponse peuvent être réduits.
Pour la recherche de similarité, MDF a exposé les algorithmes fournis par la cartouche de Bingo qui sont les métriques Tanimoto, Tversky et Euclidienne pour les sous-structures.
Le MDF est prêt à être utilisé avec la sécurité du ressort. La sécurité est facultative. MDF offre une sécurité au niveau de la méthode (autorisation). Il n’offre aucune fonctionnalité d’authentification.
Manipulation des mélanges
Le MDF prend en charge les composés chimiques à plusieurs composants. La recherche par sous-structure renverra tous les composés dont au moins un composant (structure chimique) correspond à la structure de la requête. Ceci est important car les produits de réaction qui peuvent être entrés dans un système d’enregistrement chimique sont presque toujours des mélanges à moins d’une purification approfondie.
Si une entrée dans un fichier SD importé se compose de plusieurs structures déconnectées, on suppose que cette entrée est un mélange et que chaque structure est stockée en tant que structure chimique distincte.
Normalisation de la structure
Par défaut, le MDF stocke les structures chimiques telles qu’elles sont soumises. Le MDF ne fait aucune normalisation / normalisation des structures chimiques. Il appartient au développeur utilisant le MDF de s’assurer que les structures chimiques sont correctement normalisées avant de les enregistrer dans la base de données. Il est actuellement suggéré que les développeurs implémentent une telle fonctionnalité en remplaçant la méthode preSave() de ChemicalCompoundServiceImpl. Cette méthode est appelée avant qu’un composé chimique ne soit créé ou mis à jour. Dans cette méthode, le composé chimique et toutes les structures chimiques qui le composent peuvent être manipulés librement à volonté. Notez que chaque composé enregistré sera traité par cette méthode.
Sels, solvates et solutions
MDF la version actuelle 1.0.1 n’a pas de traitement spécial pour les sels, solvates ou solutions. MDF stockera des composants séparés dans un fichier de structure chimique en tant que structure chimique distincte. Par conséquent, enregistrer un sel comme 1 = CC = CC = C1. sera représenté comme un mélange des deux ions sans aucun pourcentage fixé. Une recherche de structure exacte pour l’un ou l’autre ion renverrait ce sel. Si le sel a une charge supérieure à 1 et que plusieurs ions lui sont associés comme 1 = CC = C = C1.. le sel sera stocké sous forme de mélange de 1 = CC = C = C1 et sans aucun pourcentage fixé. Si la structure chimique est un seul ion, elle sera stockée et consultable comme toute autre structure chimique. Si ce comportement ne convient pas dans un cas spécifique, les développeurs peuvent implémenter la fonctionnalité de gestion du sel et du solvate dans la méthode preSave().
Certains systèmes commerciaux semblent également n’avoir aucun moyen de gérer les solutions. Il est recommandé de créer le composé comme s’il était pur et d’ajouter les informations sur la solution sous forme de champs séparés au niveau du composé.
Exemple d’application web
Une application web simple utilisant MDF a été créée. L’application Web utilise Spring MVC. L’application n’utilise pas l’intégration de sécurité et n’utilise pas les entités Containable et ChemicalCompoundContainer. Il n’utilise que des produits chimiquesentité composée. L’application est une base de données de composés pour les composés multi-composants. Il a une page pour importer les structures chimiques dans un fichier SD dans la base de données des composés. La base de données peut être recherchée par sous-structure et propriétés. Il utilise JSME pour dessiner les structures chimiques (Figure 3). La page des résultats de recherche affiche les résultats de recherche sous forme de tableau et de pagination. Lorsqu’une recherche de sous-structure est effectuée, la sous-structure sera mise en surbrillance dans les résultats de la recherche (figure 4). Les résultats d’une recherche peuvent être exportés sous forme de fichier SD. Les résultats de la recherche contiennent un lien vers une vue composée unique. Les propriétés du composé peuvent être éditées et des compositions peuvent être ajoutées, éditées et supprimées (Figures 5, 6). Lors de l’édition d’un composé ou d’une composition, l’application traite les modifications simultanées de manière transparente et une boîte de dialogue de résolution des conflits s’affiche sur laquelle l’utilisateur peut sélectionner les valeurs à utiliser pour chaque propriété, puis enregistrer cette nouvelle version.
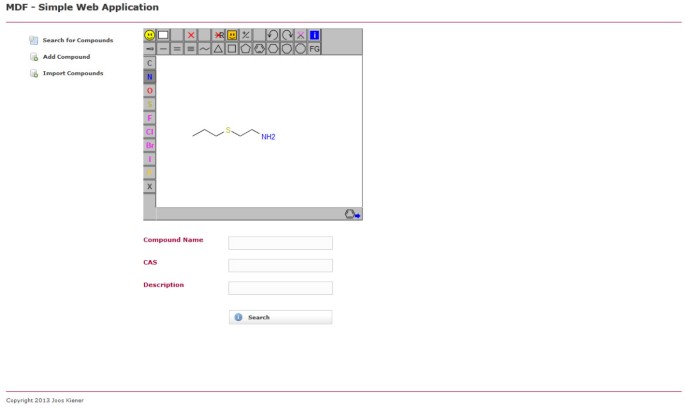
Page de recherche de l’exemple d’application web utilisant MDF. Un utilisateur peut rechercher la base de données de composés par sous-structure chimique et / ou propriétés telles que le nom du composé ou le numéro CAS.

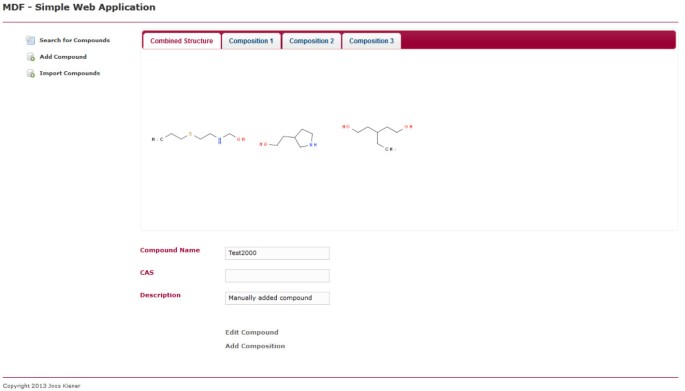
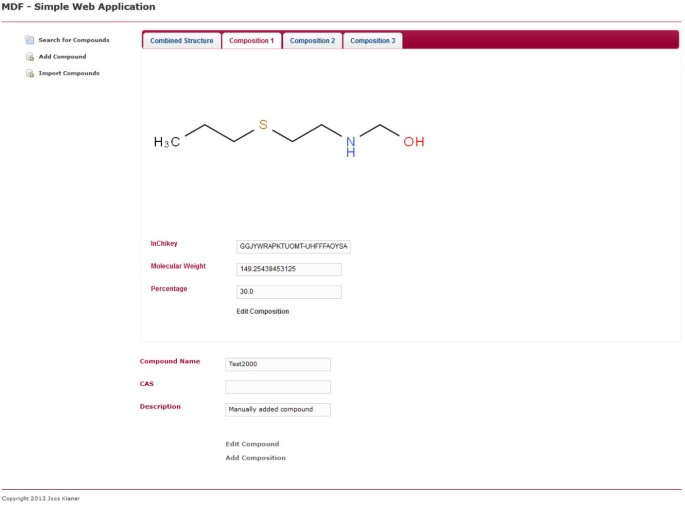
Composition unique. Affiche la même page que la figure 5, mais au lieu de l’onglet Structure combinée, l’onglet de la première composition est sélectionné. La composition peut être éditée en cliquant sur le lien correspondant dans la page.
Performance
Le MDF présente un problème de performance principal lors de la manipulation de mélanges. Si une application utilise des mélanges, c’est-à-dire des composés avec plusieurs composants, une requête de structure chimique renverra une ligne pour chaque composant d’un composé correspondant à la requête. Ceci n’est pas souhaitable car les utilisateurs finaux souhaitent voir chaque composé correspondant à la requête une seule fois. La solution au problème consiste à utiliser une requête distincte et c’est là que le problème de performances se produit. Si vous effectuez une requête distincte, toute la base de données doit être recherchée indépendamment de la clause limit, ce qui augmente considérablement le temps d’exécution. Notez que le tri a le même effet. Le tri peut donc également entraîner une énorme pénalité de performance et lors de la pagination, vous devez toujours trier pour obtenir un résultat prévisible. Pour rendre cela encore pire, la cartouche de Bingo pour PostgreSQL n’a pas encore d’implémentation appropriée pour l’estimation des coûts et le coût d’utilisation de l’indice de structure chimique est codé en dur et sous-estimé. Cela induit en erreur le planeur de requêtes PostgreSQL pour qu’il utilise toujours une analyse complète de l’index sur l’index de recherche de structure même lorsque la requête contient une clause where supplémentaire qui limite considérablement la quantité de résultats. Dans ces cas, il serait, par exemple, plus rapide d’utiliser l’index pour le numéro CAS et d’utiliser la fonction Bingo matchsub pour le filtrage. La fonction matchsub effectue une correspondance de sous-structure sans index. C’est bien sûr plus lent qu’avec un index, mais si cela ne doit être fait que pour un petit nombre de structures, c’est beaucoup plus rapide que l’analyse complète de l’index. Pour résoudre le problème d’estimation des coûts, MDF effectue des calculs internes pour décider explicitement si l’index de structure ou la fonction matchsub est utilisée. Cela peut améliorer les performances d’un ordre de grandeur. Notez que le fournisseur de la cartouche de Bingo est au courant de ce problème et que le délai pour le correctif était fin 2013. Le problème principal des requêtes et du tri distincts est cependant inhérent au fonctionnement des bases de données relationnelles et ne peut être résolu qu’avec un meilleur index de recherche de sous-structure ou un meilleur matériel. MDF offre également un paramètre pour désactiver les requêtes distinctes à l’échelle de l’application pour les bases de données composées à un seul composant.
Pour comparer le MDF, l’application Web décrite précédemment a été utilisée. La base de données contient 525573 composés uniques. Les composés sont issus du sous-ensemble de Zinc 13 à pH de référence 7 les fichiers SD 13_p0.0.sdf, 13_p0.1.sdf, 13_p0.10.sdf et 13_p0.11.sdf. Les structures sont stockées dans la base de données sous forme de SOURIRES. L’importation de chacun des fichiers SD, qui contiennent environ 131’000 structures chimiques, a pris 12 minutes avec l’index de recherche de structures chimiques désactivé. La reconstruction de l’index après l’importation de tous les fichiers SD a pris 22 minutes sur un ordinateur portable avec 4 Go de RAM, un processeur Core i5-3220M et un SSD Samsung 830 de 512 Go. Cela totalise 1 h 10 min pour configurer une base de données entièrement indexée avec un demi-million de composés. Comme référence supplémentaire, la même importation a été effectuée sur un PC de bureau avec 12 Go de RAM, i7-875K @ 3,4 GHz et la base de données fonctionnant sur un lecteur Western Digital Green (5400 TR / min). Ici, l’importation a pris 8 minutes et la conclusion est que l’importation est limitée par le processeur plutôt que par la vitesse de stockage. La génération d’index a pris environ 22 min sur l’ordinateur portable et 20 min sur le bureau. La conclusion ici est qu’il est plus limité par le processeur, mais la vitesse du lecteur compte également. Les performances d’importation et de génération d’index lors du stockage des structures en tant que molfiles n’ont pas été comparées.
Les performances de recherche de sous-structure ont été comparées avec différents paramètres de configuration. La recherche de sous-structures est effectuée par Bingo PostgreSQL cartridge et ce benchmark reflète donc ses performances plus les frais généraux causés par le MDF. À l’exception de c1ccccc1, l’auteur a dessiné des structures chimiques sans signification spécifique et testé la vitesse de recherche. La vitesse de recherche a été déterminée par la mise en œuvre des logbacks d’org.profileur slf4j.Profiler.
Le premier benchmark est une référence. Ce benchmark utilisait l’option pour désactiver toutes les requêtes distinctes et aucun tri n’a été effectué. MDF effectue un décompte des résultats totaux lors de la première occurrence d’une recherche de structure chimique et le décompte est mis en cache, ce qui ralentit le chargement de la première page par rapport aux pages suivantes. Chaque page contient 4 enregistrements. Les résultats sont présentés dans le tableau 2 par ordre croissant par nombre de résultats.
Le benchmark a été répété mais cette fois avec des requêtes distinctes activées. Le temps de chargement de la première page est doublé car la requête count est exécutée, puis la requête réelle est exécutée, ce qui prend à peu près le même temps que la requête count en raison de la clause distincte. La deuxième page prend alors toujours la moitié du temps de chargement par rapport à la première page pour la même raison (tableau 3). Le nombre d’accès est identique à celui du tableau 2 car tous les composés de la base de données ne sont constitués que d’un seul composant.
Les résultats montrent que Bingo n’optimise pas une requête de sous-structure commune comme un cycle benzénique et recherche donc c1ccccc1 dans une base de données dans laquelle presque toutes les molécules ont cette caractéristique est très lent. Pour améliorer la vitesse de recherche dans un tel scénario, il est recommandé de filtrer par des propriétés supplémentaires. Par conséquent, la référence a été répétée avec un filtre supplémentaire de nom composé commençant par « ZINC34 ».
Le tableau 4 montre les avantages de l’optimisation MDF comme solution de contournement du problème d’estimation des coûts dans la cartouche Bingo PostgreSQL. Sans cette optimisation, l’indice de référence aurait les mêmes performances que celles indiquées dans le tableau 3.
MDF utilise également la fonctionnalité de recherche de similarité des cartouches de bingo. Ses performances ont été testées en recherchant des composés avec un score de similitude de 0,9 à l’aide de la mesure de similarité de Tanimoto également connue sous le nom d’indice de Jaccard. Les résultats sont présentés dans le tableau 5.
Outlook
Pour générer les représentations de la structure chimique, la boîte à outils Indigo est utilisée. La boîte à outils peut être configurée pour générer les structures de nombreuses manières, y compris la coloration d’hétéroatomes, la longueur et la largeur de liaison et bien d’autres. Actuellement, cela est codé en dur et ne peut pas être ajusté par l’utilisateur. Une étape suivante consisterait à exposer ces options de configuration afin qu’elles puissent être définies via un fichier de propriétés Java. La manipulation des sels et des solvates doit également être mise en œuvre pour rendre le MDF utilisable dans les zones où de tels composés sont importants.
Pour utiliser MDF, vous devez pouvoir programmer en Java et vous aurez besoin de connaissances de base sur Spring framework et comment le configurer. Cela limite le public cible. Lorsque vous utilisez MDF, vous devez écrire du code de plaque de chaudière et l’étape suivante consisterait donc à créer des outils supplémentaires pour faciliter l’utilisation de MDF, tels que la génération automatique de classes d’entités et de leurs référentiels et services. Ces outils doivent être configurables afin qu’un utilisateur puisse définir les propriétés souhaitées pour chacune des entités et les méthodes de recherche souhaitées. Une option serait un plugin maven. Les plugins Maven peuvent générer du code comme la création de métamodèles effectuée par le plugin QueryDSL-maven. Une autre option serait des annotations qui génèrent du code lors de la compilation comme le fait Project Lombok.
La dernière étape consisterait à créer une plate-forme d’applications Web permettant aux administrateurs de créer de nouvelles applications Web avec une capacité de recherche de structures chimiques en entrant simplement les propriétés souhaitées pour les entités sur un formulaire Web et en cliquant sur un bouton. Il est évident que cela nécessiterait un effort de développement important.