
Funktionalität
Nachfolgend finden Sie eine Auflistung der Kernfunktionalitäten von MDF:
-
Chemische Struktursuche: Full, Sub, SMARTS, Similarity, Formula
-
Chemische Struktursuchen können mit Eigenschaftssuchen kombiniert werden
-
Chemische Struktursuchen werden ausgelagert und zwischengespeichert
-
Unterstützung für Mehrkomponentenverbindungen (Mischungen)
-
3 durchsuchbare Entitäten für chemische Strukturen: ChemicalCompound, Containable und ChemicalCompoundContainer
-
Import und Export von SD-Dateien für über 3 Entitäten
-
Transaktionaler Datenbankzugriff
-
Optionale Sicherheit (Autorisierung)
Mit dem Design und der Funktionalität von MDF ist es möglich, viele verschiedene Arten von Systemen wie Registrierungssysteme, Inventarsysteme oder nur eine einfache zusammengesetzte Datenbank zu erstellen. Während Sie auch Ihr eigenes ELN erstellen können, gibt es auch das kostenlose Indigo ELN. Diese ELN wurde von GGA Software Services erstellt und wird bei Pfizer verwendet.
Im Gegensatz zu MolDB5R und MyMolDB ist MDF keine voll funktionsfähige eigenständige Webanwendung mit chemischer Struktursuche. Wie der Name schon sagt, handelt es sich um ein Framework zur Vereinfachung der Erstellung einer solchen Anwendung. MDF kann auch verwendet werden, um lokale oder Client-Server-Desktop-Anwendungen zu erstellen. MDF richtet sich an Softwareentwickler und ist nicht für die Verwendung durch Wissenschaftler selbst gedacht. MDF-Funktionen sind jedoch sehr robust. Die Suche nach chemischen Strukturen erfolgt in der Datenbank und nicht im Anwendungscode. Daher können Sie gleichzeitig nach chemischer Struktur und anderen Eigenschaften suchen, die Ergebnisse können nach mehreren Eigenschaften sortiert und ausgelagert werden (SQL-OFFSET- und LIMIT-Klauseln). Beachten Sie, dass bei der chemischen Struktursuche im Anwendungscode für jede Abfrage mindestens zwei Fahrten zur Datenbank erforderlich sind, nämlich die Struktursuche und anschließend das Filtern nach anderen Eigenschaften, Sortieren und / oder Einschränken. Beides muss in derselben Transaktion geschehen. Es wurde nicht festgestellt, ob MolDB5R und MyMolDB dies tatsächlich in derselben Transaktion tun.
In MDF können die chemischen Verbindungen mit einem containable assoziiert werden, was in Registrierungssystemen eine Charge oder in einem Inventarsystem eine Menge wäre. Eine bestimmte physikalisch verfügbare Probe in einer strichcodierten Flasche kann dann einem Behälter zugeordnet werden. Diese Behälter können auch nach chemischer Struktur durchsucht werden. Dies ist die Grundlage für die Erstellung eines Inventarsystems. Entwickler können jeder Entität so viele zusätzliche Eigenschaften hinzufügen, wie sie möchten, und alle sind zusammen mit der chemischen Struktur durchsuchbar.
Der gesamte Datenzugriff in MDF erfolgt transaktional, um Dateninkonsistenzen zu vermeiden. MDF kann für die Verwendung eines Datenbankverbindungspools konfiguriert werden. Wenn Sie ein RDBMS abfragen, dauert das Erstellen einer Verbindung oft länger als die Abfrage selbst, und wenn Sie bereits offene Verbindungen haben, können die Antwortzeiten verkürzt werden.
Für die Ähnlichkeitssuche wurden die von der Bingo-Patrone bereitgestellten Algorithmen Tanimoto, Tversky und Euklidische Metrik für Unterstrukturen.
MDF kann mit Spring Security verwendet werden. Sicherheit ist optional. MDF bietet Sicherheit auf Methodenebene (Autorisierung). Es bietet keine Authentifizierungsfunktionen.
Handhabung von Mischungen
MDF unterstützt mehrkomponentige chemische Verbindungen. Die Suche nach Unterstruktur gibt alle Verbindungen zurück, die mindestens eine Komponente (chemische Struktur) haben, die der Abfragestruktur entspricht. Dies ist wichtig, da Reaktionsprodukte, die in ein chemisches Registrierungssystem eingegeben werden können, fast immer Gemische sind, es sei denn, es wird eine umfassende Reinigung durchgeführt.
Wenn ein Eintrag in einer importierten SD-Datei aus mehreren getrennten Strukturen besteht, wird angenommen, dass dieser Eintrag eine Mischung ist und jede Struktur als separate chemische Struktur gespeichert ist.
Strukturnormalisierung
Standardmäßig speichert MDF die chemischen Strukturen so, wie sie übermittelt werden. MDF führt keine Standardisierung / Normalisierung chemischer Strukturen durch. Es ist Sache des Entwicklers, der MDF verwendet, um sicherzustellen, dass chemische Strukturen korrekt normalisiert werden, bevor sie in der Datenbank gespeichert werden. Es wird derzeit vorgeschlagen, dass Entwickler eine solche Funktion implementieren, indem sie die preSave () -Methode von ChemicalCompoundServiceImpl überschreiben. Diese Methode wird aufgerufen, bevor eine chemische Verbindung erstellt oder aktualisiert wird. Innerhalb dieser Methode kann die chemische Verbindung und alle chemischen Strukturen, aus denen sie besteht, beliebig manipuliert werden. Beachten Sie, dass jede gespeicherte Verbindung mit dieser Methode verarbeitet wird.
Salze, Solvate und Lösungen
Die aktuelle Version 1.0.1 hat keine spezielle Handhabung für Salze, Solvate oder Lösungen. MDF speichert separate Komponenten in einer chemischen Strukturdatei als separate chemische Struktur. Speichern Sie daher ein Salz wie 1 = CC = CC = C1 . wird als Mischung der beiden Ionen ohne Prozentsätze dargestellt. Eine genaue Struktursuche für beide Ionen würde dieses Salz zurückgeben. Wenn das Salz eine Ladung größer als 1 hat und mehrere Ionen damit verbunden sind, wie 1 = CC = C = C1.. das Salz wird als Mischung von 1 = CC = C = C1 und ohne festgelegte Prozentsätze gelagert. Wenn es sich bei der chemischen Struktur um ein einzelnes Ion handelt, wird es wie jede andere chemische Struktur gespeichert und durchsucht. Wenn dieses Verhalten in einem bestimmten Fall ungeeignet ist, können Entwickler die Salt- und Solvat-Handling-Funktionalität in der preSave () -Methode implementieren.
Einige kommerzielle Systeme scheinen auch keine Möglichkeit zu haben, Lösungen zu handhaben. Es wird empfohlen, die Verbindung so zu erstellen, als wäre sie rein, und die Lösungsinformationen als separate Felder auf der Verbindungsebene hinzuzufügen.
Beispiel-Webanwendung
Es wurde eine einfache Webanwendung mit MDF erstellt. Die Webanwendung verwendet Spring MVC. Die Anwendung nutzt die Sicherheitsintegration nicht und verwendet nicht die Entitäten Containable und ChemicalCompoundContainer. Es werden nur chemische Verbindungen verwendet. Die Anwendung ist eine Compound-Datenbank für Mehrkomponentenverbindungen. Es verfügt über eine Seite zum Importieren der chemischen Strukturen in einer SD-Datei in die Compound-Datenbank. Die Datenbank kann nach Unterstruktur und Eigenschaften durchsucht werden. Es verwendet JSME zum Zeichnen der chemischen Strukturen (Abbildung 3). Die Suchergebnisseite zeigt die Suchtreffer tabellarisch und paginiert an. Wenn eine Unterstruktursuche durchgeführt wird, wird die Unterstruktur in den Suchergebnissen hervorgehoben (Abbildung 4). Die Treffer einer Suche können als SD-Datei exportiert werden. Die Suchergebnisse enthalten einen Link zu einer einzelnen zusammengesetzten Ansicht. Die Eigenschaften der Verbindung können bearbeitet werden und Zusammensetzungen können hinzugefügt, bearbeitet und gelöscht werden (Abbildungen 5, 6). Beim Bearbeiten einer Verbindung oder einer Komposition behandelt die Anwendung gleichzeitige Änderungen transparent und es wird ein Dialogfeld zur Konfliktlösung angezeigt, in dem der Benutzer auswählen kann, welche Werte für jede Eigenschaft verwendet werden sollen, und diese neue Version dann speichern kann.
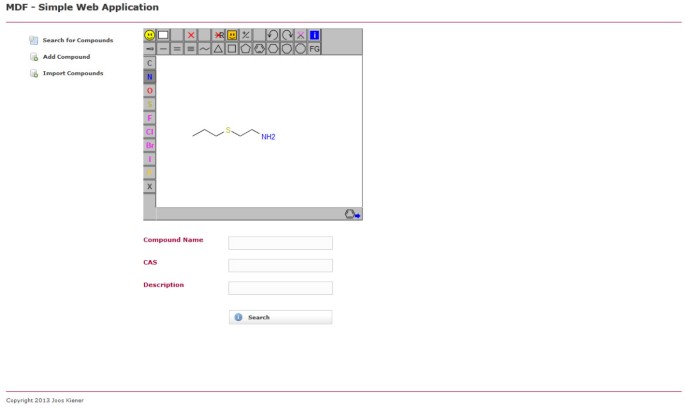
Suchseite der Beispiel-Webanwendung mit MDF. Ein Benutzer kann die Verbindungsdatenbank nach chemischer Unterstruktur und / oder Eigenschaften wie Verbindungsname oder CAS-Nummer durchsuchen.

Ergebnisseite einer Substruktursuche. Die Ergebnisse werden in einer Auslagerungstabelle angezeigt, die vom jQuery-Plugin datatables generiert wird. Die chemischen Strukturbilder haben die passende Unterstruktur rot hervorgehoben. Wenn Sie in das Bild der chemischen Struktur klicken, wird das LÄCHELN dafür angezeigt.
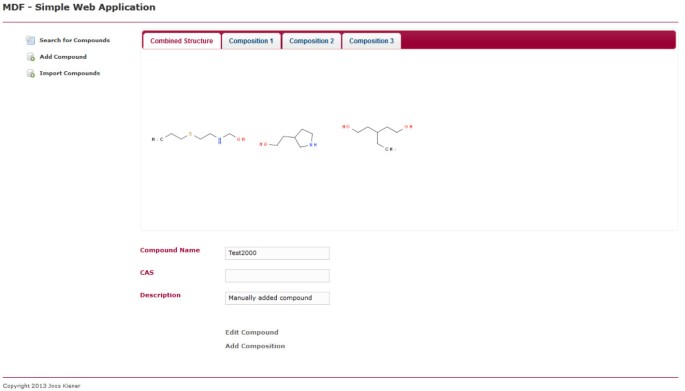
Einzelne zusammengesetzte Ansicht. Diese Webseite zeigt eine einzelne Verbindung an. Die Verbindung kann bearbeitet oder gelöscht werden, indem Sie auf den entsprechenden Link innerhalb der Seite klicken. Es gibt eine Registerkarte, die alle enthaltenen chemischen Strukturen anzeigt, und eine Registerkarte für jede einzelne Zusammensetzung, aus der die Verbindung besteht.
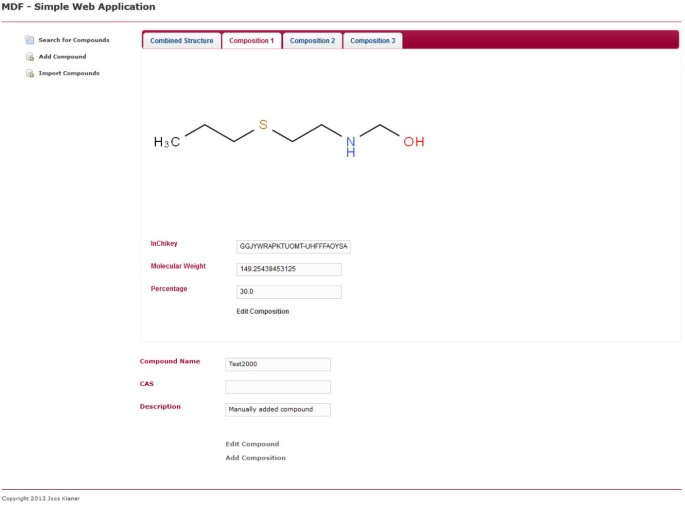
Einzelne Komposition. Zeigt dieselbe Seite wie Abbildung 5, aber anstelle der Registerkarte Kombinierte Struktur wird die Registerkarte der ersten Komposition ausgewählt. Die Komposition kann durch Klicken auf den entsprechenden Link innerhalb der Seite bearbeitet werden.
Leistung
MDF hat ein Hauptleistungsproblem beim Umgang mit Gemischen. Wenn eine Anwendung Mischungen verwendet, dh Verbindungen mit mehreren Komponenten, gibt eine chemische Strukturabfrage eine Zeile für jede Komponente in einer Verbindung zurück, die der Abfrage entspricht. Dies ist unerwünscht, da die Endbenutzer jede Verbindung, die der Abfrage entspricht, nur einmal sehen möchten. Die Lösung für das Problem besteht darin, eine eindeutige Abfrage zu verwenden, und hier tritt das Leistungsproblem auf. Wenn Sie eine eindeutige Abfrage ausführen, muss die gesamte Datenbank unabhängig von der limit-Klausel durchsucht werden, was die Ausführungszeit erheblich verlängert. Beachten Sie, dass das Sortieren den gleichen Effekt hat. Das Sortieren kann also auch eine enorme Leistungseinbuße haben, und beim Paging sollten Sie immer sortieren, um ein vorhersehbares Ergebnis zu erzielen. Um dies noch schlimmer zu machen, hat Cartridge for PostgreSQL noch keine ordnungsgemäße Implementierung für die Kostenschätzung und die Kosten für die Verwendung des chemischen Strukturindex sind hartcodiert und unterschätzt. Dies führt den PostgreSQL-Abfrageplaner dazu, immer einen vollständigen Indexscan für den Suchindex zu verwenden, selbst wenn die Abfrage eine zusätzliche where-Klausel enthält, die die Anzahl der Ergebnisse stark einschränkt. In diesen Fällen wäre es beispielsweise schneller, den Index für die CAS-Nummer zu verwenden und die Bingo Matchsub-Funktion zum Filtern zu verwenden. Die Funktion matchsub führt eine Unterstrukturübereinstimmung ohne Index durch. Dies ist natürlich langsamer als bei einem Index, aber wenn es nur für eine kleine Anzahl von Strukturen durchgeführt werden muss, ist es viel schneller als der vollständige Indexscan. Um das Kostenschätzungsproblem zu beheben, führt MDF einige interne Berechnungen durch, um explizit zu entscheiden, ob der Strukturindex oder die Matchsub-Funktion verwendet wird. Dies kann die Leistung um eine Größenordnung verbessern. Beachten Sie, dass der Lieferant der Bingo-Patrone dieses Problem kennt und der Zeitplan für die Behebung Ende 2013 war. Das Hauptproblem unterschiedlicher Abfragen und Sortierungen hängt jedoch mit der Funktionsweise relationaler Datenbanken zusammen und kann nur mit einem besseren Suchindex für Unterstrukturen oder besserer Hardware gelöst werden. MDF bietet auch eine Einstellung zum Deaktivieren eindeutiger Abfragen für anwendungsweite Einkomponenten-Verbunddatenbanken.
Zum Benchmark wurde die zuvor skizzierte Webanwendung verwendet. Die Datenbank enthält 525573 einzigartige Verbindungen. Die Verbindungen sind aus der Zink-Teilmenge 13 bei Referenz-pH 7 die SD-Dateien 13_p0.0.sdf, 13_p0.1.sdf, 13_p0.10.sdf und 13_p0.11.sdf. Die Strukturen werden in der Datenbank als SMILES gespeichert. Der Import jeder der SD-Dateien, die ungefähr 131’000 chemische Strukturen enthalten, dauerte 12 Minuten, wobei der Suchindex für chemische Strukturen deaktiviert war. Der Wiederaufbau des Indexes nach dem Import aller SD-Dateien dauerte 22 Minuten auf einem Laptop mit 4 GB RAM, Core i5-3220M CPU und einer 512 GB Samsung 830 SSD. Das entspricht 1 h 10 min, um eine vollständig indizierte Datenbank mit einer halben Million Verbindungen einzurichten. Als zusätzliche Referenz wurde der gleiche Import auf einem Desktop-PC mit 12 GB RAM, i7-875K @ 3.4 GHz und der Datenbank auf einem Western Digital Green Drive (5400 RPM) durchgeführt. Hier dauerte der Import 8 Minuten und die Schlussfolgerung ist, dass der Import eher CPU-begrenzt als durch die Speichergeschwindigkeit begrenzt ist. Die Indexgenerierung dauerte ungefähr 22 Minuten auf dem Laptop und 20 Minuten auf dem Desktop. Die Schlussfolgerung hier ist, dass es mehr durch CPU begrenzt ist, aber auch die Laufwerksgeschwindigkeit zählt. Die Import- und Indexgenerierungsleistung beim Speichern der Strukturen als Moldateien wurde nicht verglichen.
Die Suchleistung der Unterstruktur wurde mit verschiedenen Konfigurationseinstellungen verglichen. Die Substruktursuche wird von einer PostgreSQL-Cartridge durchgeführt, und dieser Benchmark spiegelt daher seine Leistung sowie den durch MDF verursachten Overhead wider. Mit Ausnahme von c1ccccc1 zeichnete der Autor chemische Strukturen ohne spezifische Bedeutung und testete die Suchgeschwindigkeit. Die Suchgeschwindigkeit wurde durch Logbacks Implementierung von org bestimmt.in: slf4j.profiler.Profiler.
Der erste Benchmark ist eine Referenz. Dieser Benchmark verwendete die Option, alle eindeutigen Abfragen zu deaktivieren, und es wurde keine Sortierung durchgeführt. MDF führt beim ersten Auftreten einer chemischen Struktursuche eine Zählung der gesamten Treffer durch, und die Zählung wird zwischengespeichert, wodurch die erste Seite langsamer geladen wird als die nachfolgenden Seiten. Jede Seite enthält 4 Datensätze. Die Ergebnisse sind in Tabelle 2 aufsteigend nach Anzahl der Treffer geordnet.
Der Benchmark wurde wiederholt, diesmal jedoch mit aktivierten eindeutigen Abfragen. Die Ladezeit der ersten Seite wird verdoppelt, da die count-Abfrage ausgeführt wird, und dann wird die eigentliche Abfrage ausgeführt, die aufgrund der distinct-Klausel ungefähr die gleiche Zeit in Anspruch nimmt wie die count-Abfrage. Die zweite Seite benötigt dann aus dem gleichen Grund immer die Hälfte der Ladezeit im Vergleich zur ersten Seite (Tabelle 3). Die Anzahl der Treffer ist identisch mit der in Tabelle 2, da alle Verbindungen in der Datenbank nur aus einer Komponente bestehen.
Die Ergebnisse zeigen, dass Bingo keine Optimierungen für eine gängige Substrukturabfrage wie einen Benzolring durchführt und daher die Suche nach c1ccccc1 in einer Datenbank, in der fast alle Moleküle diese Funktion haben, sehr langsam ist. Um die Suchgeschwindigkeit in einem solchen Szenario zu verbessern, wird empfohlen, nach zusätzlichen Eigenschaften zu filtern. Daher wurde der Benchmark mit einem zusätzlichen Filter des zusammengesetzten Namens beginnend mit „ZINC34“ wiederholt.
Tabelle 4 zeigt den Nutzen der MDF-Optimierung als Workaround des Problems der Kostenschätzung in der PostgreSQL-Cartridge. Ohne diese Optimierung hätte der Benchmark die gleiche Leistung wie in Tabelle 3 gezeigt.
MDF verwendet auch die Bingo-Ähnlichkeitssuchfunktion. Seine Leistung wurde getestet, indem nach Verbindungen mit einem Ähnlichkeitswert von 0,9 unter Verwendung des Tanimoto-Ähnlichkeitsmaßes, auch bekannt als Jaccard-Index, gesucht wurde . Die Ergebnisse sind in Tabelle 5 dargestellt.
Outlook
Zur Generierung der chemischen Strukturdarstellungen wird das Indigo Toolkit verwendet. Das Toolkit kann so konfiguriert werden, dass die Strukturen auf viele Arten erzeugt werden, einschließlich der Färbung von Heteroatomen, Bindungslänge und -breite und vielem mehr. Derzeit ist dies fest codiert und kann vom Benutzer nicht angepasst werden. Ein nächster Schritt wäre, diese Konfigurationsoptionen verfügbar zu machen, damit sie über eine Java-Eigenschaftendatei festgelegt werden können. Auch der Umgang mit Salzen und Solvaten muss implementiert werden, um MDF in Bereichen nutzbar zu machen, in denen solche Verbindungen wichtig sind.
Um MDF nutzen zu können, müssen Sie in Java programmieren können und Grundkenntnisse über Spring Framework und dessen Konfiguration benötigen. Dies begrenzt die Zielgruppe. Daher besteht der nächste Schritt darin, zusätzliche Tools zu erstellen, um die Verwendung von MDF zu erleichtern, z. B. die automatische Generierung von Entitätsklassen und deren Repositorys und Diensten. Diese Werkzeuge müssten konfigurierbar sein, damit ein Benutzer die gewünschten Eigenschaften für jede der Entitäten und die gewünschten Suchmethoden definieren kann. Eine Option wäre ein Maven-Plugin. Maven-Plugins können Code wie die Metamodel-Erstellung des QueryDSL-Maven-Plugins generieren. Eine andere Option wären Anmerkungen, die beim Kompilieren Code generieren, wie dies bei Project Lombok der Fall ist.Der letzte Schritt wäre, eine Webanwendungsplattform zu erstellen, mit der Administratoren neue Webanwendungen mit chemischer Struktursuchfunktion erstellen können, indem sie einfach die gewünschten Eigenschaften für die Entitäten in ein Webformular eingeben und auf eine Schaltfläche klicken. Es ist offensichtlich, dass dies einen erheblichen Entwicklungsaufwand erfordern würde.