
Wir haben eine Vielzahl von Konfigurationen, Objektgrößen und Client-Worker-Zählungen getestet, um den Durchsatz eines Ceph-Clusters mit sieben Knoten für kleine und große Objekt-Workloads zu maximieren. Wie im ersten Beitrag beschrieben, wurde der Ceph-Cluster mit einem einzigen OSD (Object Storage Device) erstellt, das pro Festplatte konfiguriert wurde und insgesamt 112 OSDs pro Ceph-Cluster enthält. In diesem Beitrag werden wir die Top-Line-Leistung für verschiedene Objektgrößen und Workloads verstehen.
Hinweis: Die Begriffe „read“ und HTTP GET werden in diesem Beitrag synonym verwendet, ebenso wie die Begriffe HTTP PUT und „write“.“
Large-Object Workload
Sequenzielle Eingabe/Ausgabe (I/O)-Workloads mit großen Objekten sind einer der häufigsten Anwendungsfälle für Ceph Object Storage. Zu diesen Hochdurchsatz-Workloads gehören Big Data-Analysen, Sicherungs- und Archivierungssysteme, Bildspeicher sowie Streaming von Audio und Video. Für diese Arten von Workloads ist der Durchsatz (MB / s oder GB / s) die Schlüsselmetrik, die die Speicherleistung definiert.
Wie in Tabelle 1 gezeigt, zeigte die 100% ige HTTP-GET- und HTTP-PUT-Arbeitslast für große Objekte eine sublineare Skalierbarkeit, wenn die Anzahl der RGW-Hosts erhöht wurde. Daher haben wir die aggregierte Bandbreite von ~ 5,5 Gbit / s für HTTP-GET- und HTTP-PUT-Workloads gemessen und interessanterweise keine Ressourcensättigung in Ceph-Clusterknoten festgestellt.
Dieser Cluster kann mehr produzieren, wenn wir mehr Last darauf richten können. Also haben wir zwei Möglichkeiten identifiziert, dies zu tun. 1) Fügen Sie mehr Client-Knoten hinzu 2) Fügen Sie mehr RGW-Knoten hinzu. Wir konnten uns nicht für Option 1 entscheiden, da wir durch die in diesem Labor verfügbaren physischen Client-Knoten eingeschränkt waren. Also haben wir uns für Option 2 entschieden und eine weitere Testrunde durchgeführt, diesmal jedoch mit 14 RGWs.
Wie in Tabelle 2 gezeigt, ergab der 14-RGW-Test im Vergleich zum 7-RGW-Test eine um 14% höhere Schreibleistung mit ~ 6,3 Gbit / s. In ähnlicher Weise zeigte der HTTP-GET-Workload eine um 16% höhere Leseleistung mit ~ 6,5 Gbit / s. Dies war der maximale aggregierte Durchsatz, der auf diesem Cluster beobachtet wurde, nach dem eine Mediensättigung (HDD) festgestellt wurde, wie in Abbildung 1 dargestellt. Basierend auf den Ergebnissen glauben wir, dass wir diesem Cluster mehr Ceph OSD-Knoten hinzugefügt haben, Die Leistung hätte noch weiter skaliert werden können, bis die Ressourcensättigung begrenzt war.
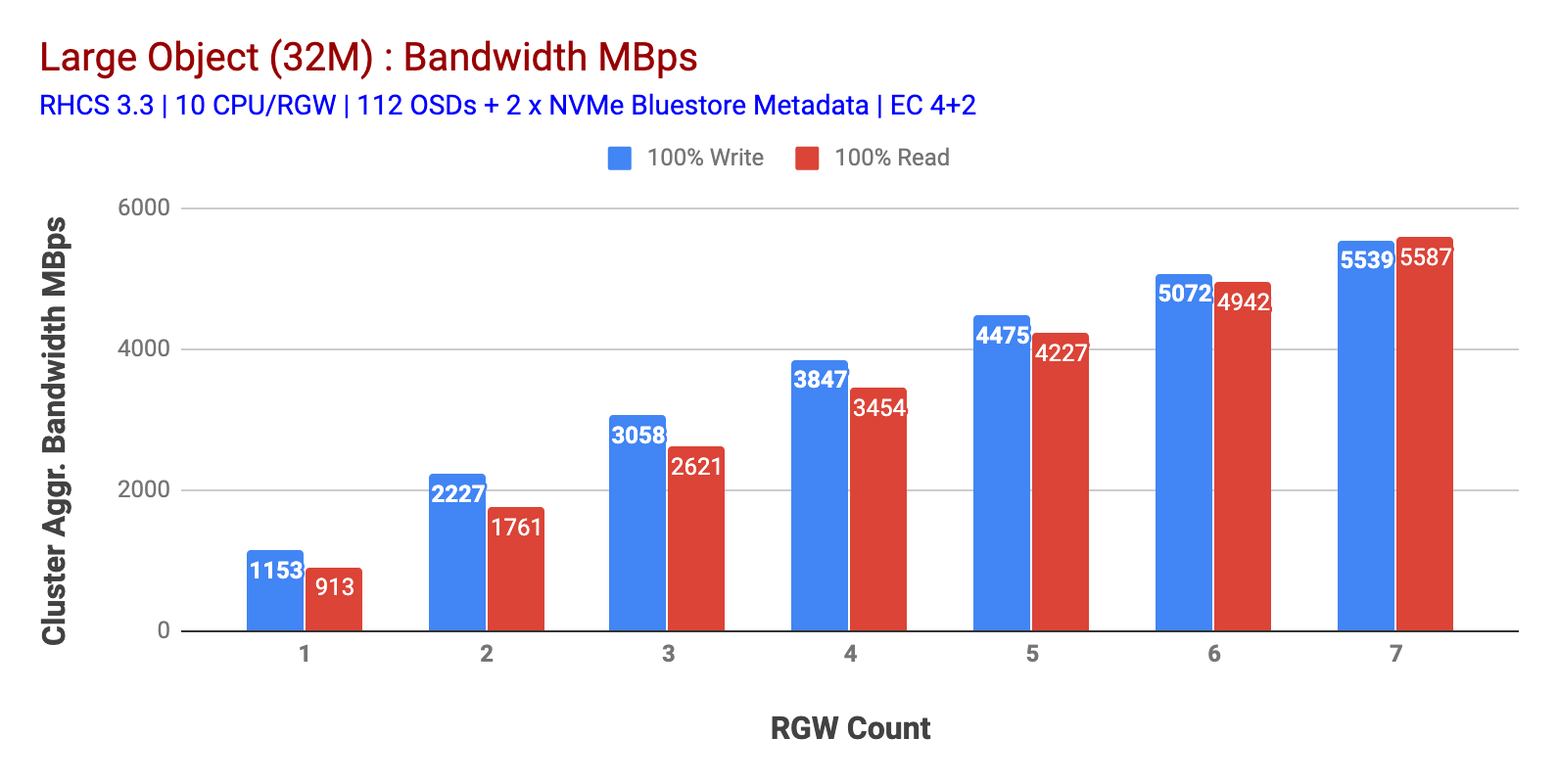
Diagramm 1: Große Objekt test
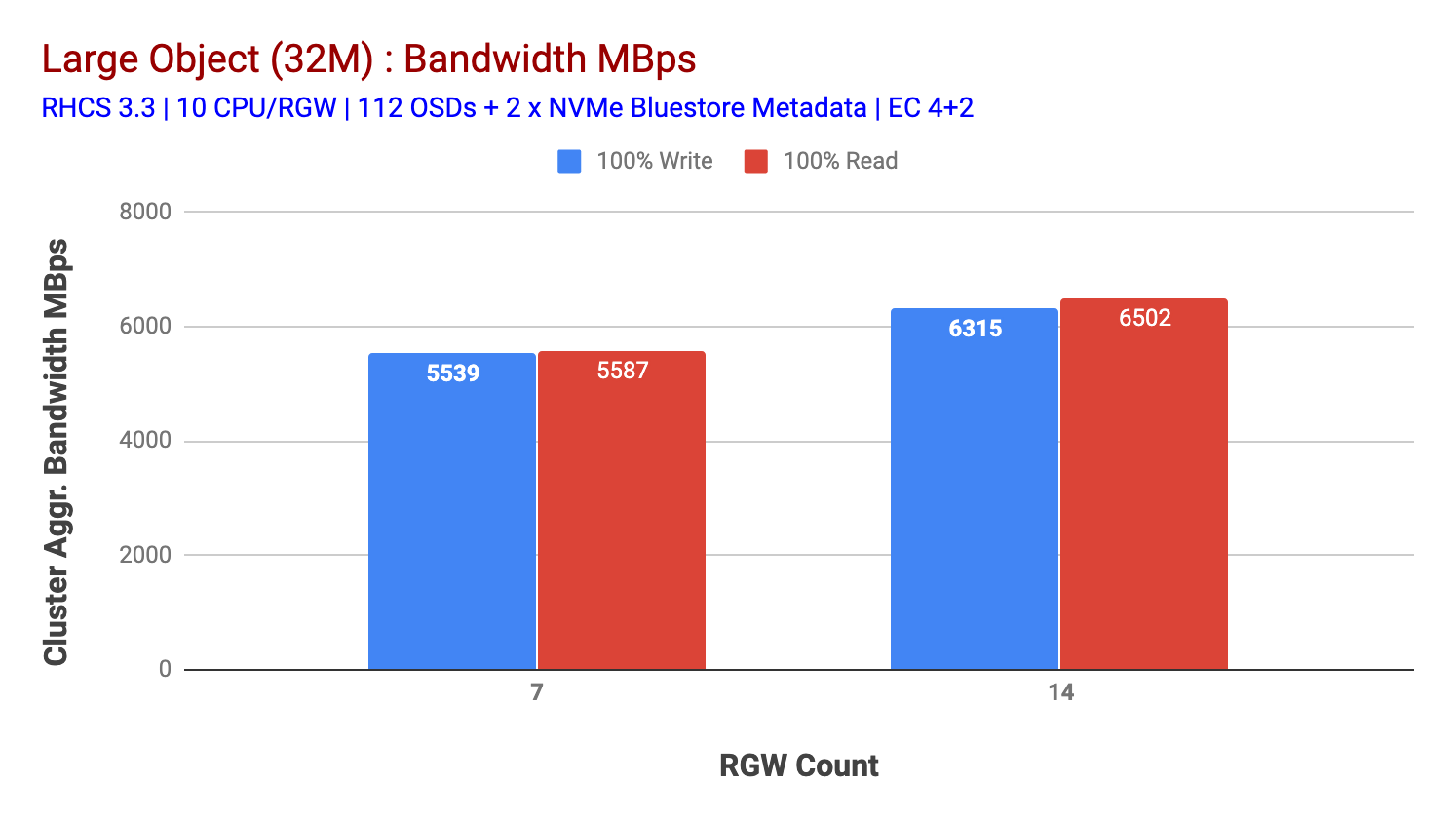
Diagramm 2: Große Objekt test mit 14 RGWs
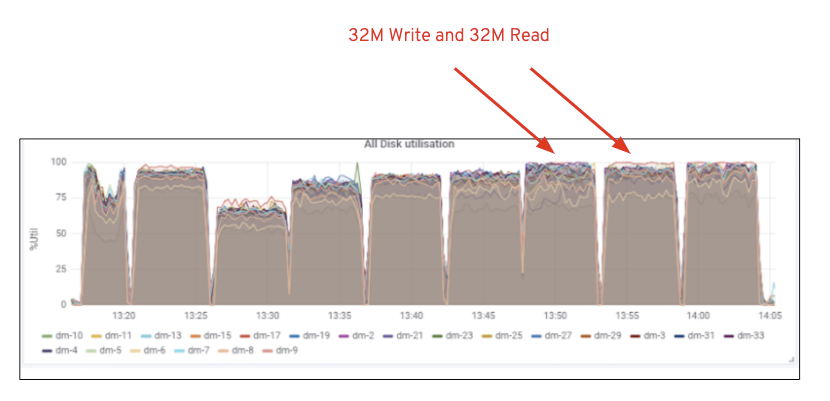
Abbildung 1: Ceph OSD (HDD) Mediennutzung
Small Object Workload
Wie in Tabelle 3 gezeigt, zeigten Small object 100% HTTP GET- und HTTP PUT-Workloads eine sublineare Skalierbarkeit, wenn die Anzahl der RGW-Hosts erhöht wurde. Als solches haben wir ~ 6,2 K Ops-Durchsatz für HTTP-PUT bei 9 ms Anwendungsschreiblatenz und ~ 3,2 K Ops für HTTP-GET-Workloads mit 7 RGW-Instanzen gemessen.
Bis zu 7 RGW-Instanzen bemerkten wir keine Ressourcensättigung, also verdoppelten wir die RGW-Instanzen, indem wir diese auf 14 skalierten, und beobachteten eine verschlechterte Leistung für HTTP PUT Workload, die der Mediensättigung zugeschrieben wird, während HTTP GET Leistung skaliert und bei ~ 4.5K Ops gekrönt. Daher hätte die Schreibleistung höher skaliert werden können, wenn wir mehr Ceph OSD-Knoten hinzugefügt hätten. Was die Leseleistung betrifft, glauben wir, dass das Hinzufügen von mehr Client-Knoten die Leistung hätte verbessern sollen, aber wir hatten keine physischen Knoten mehr im Labor, um diese Hypothese zu testen.Eine weitere interessante Beobachtung aus Diagramm 3 ist die reduzierte durchschnittliche Antwortzeit für HTTP-PUT-Workloads, die bei 9 ms gemessen wurde, während HTTP-GET eine durchschnittliche Latenz von 17 ms zeigte, gemessen an der Workload der Anwendung. Wir glauben, dass einer der Gründe für die einstellige Anwendungslatenz für die Schreibarbeitslast die Kombination der Leistungsverbesserung durch das BlueStore-OSD-Backend sowie das leistungsstarke Intel Optane NVMe ist, das zum Sichern von BlueStore-Metadaten-Geräten verwendet wird. Es ist erwähnenswert, dass das Erreichen einer einstelligen durchschnittlichen Schreiblatenz von einem Objektspeichersystem nicht trivial ist. Wie in Tabelle 3 dargestellt, kann Ceph Object Storage, wenn es mit BlueStore OSD Backend und Intel Optane für Metadaten bereitgestellt wird, den Schreibdurchsatz bei geringerer Antwortzeit erreichen.
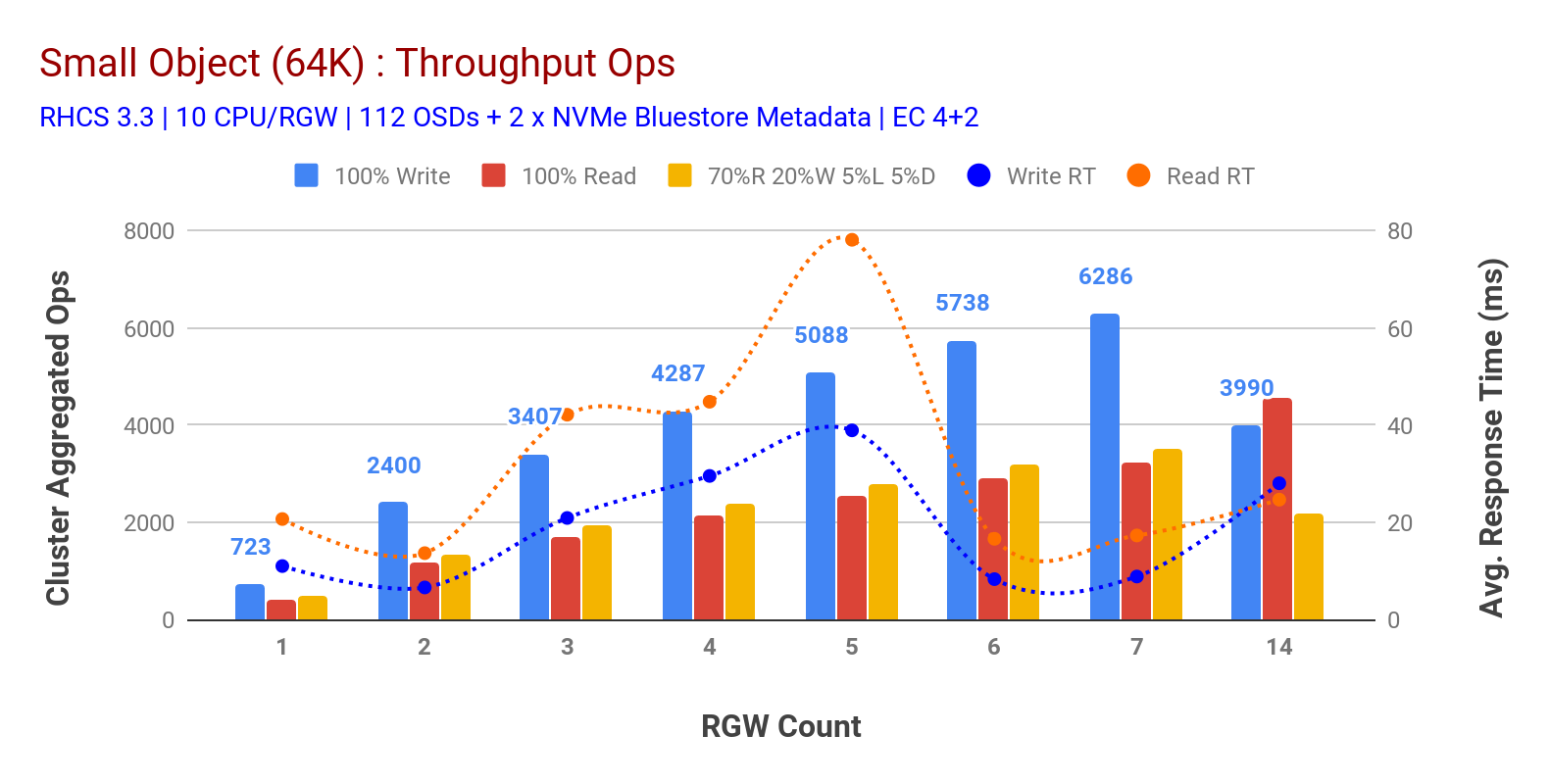
Diagramm 3: Small Object Test
Zusammenfassung und weiter oben
Der in diesem Test verwendete Cluster mit fester Größe hat eine große Objektbandbreite von ~ 6,3 Gbit / s bzw. ~ 6,5 Gbit / s für Schreib- und Lese-Workloads geliefert. Derselbe Cluster für kleine Objektgrößen hat ~ 6,5 K Ops bzw. ~ 4,5 K Ops für Schreib- und Lese-Workload geliefert.
Die Ergebnisse haben auch gezeigt, dass BlueStore OSD in Kombination mit Intel Optane NVMe eine einstellige durchschnittliche Anwendungslatenz geliefert hat, was für Objektspeichersysteme nicht trivial ist. Im nächsten Beitrag werden wir die Leistung untersuchen, die mit dem dynamischen Sharding von Buckets verbunden ist, und wie der Pre-Sharding-Bucket bei der deterministischen Leistung helfen kann.