
Vi har testat en mängd olika konfigurationer, objektstorlekar och klientarbetare räknas för att maximera genomströmningen av en sju nod Ceph kluster för små och stora objekt arbetsbelastningar. Som beskrivs i det första inlägget byggdes Ceph-klustret med en enda OSD (Object Storage Device) konfigurerad per hårddisk, med totalt 112 OSD per Ceph-kluster. I det här inlägget kommer vi att förstå topplinjen för olika objektstorlekar och arbetsbelastningar.
notera: Termerna ” läs ”och HTTP GET används omväxlande i hela detta inlägg, liksom termerna HTTP PUT och” write.”
arbetsbelastning för stora objekt
arbetsbelastningar för stora objekt Sekventiell ingång/utgång (I / O) är ett av de vanligaste användningsfallen för Ceph-objektlagring. Dessa arbetsbelastningar med hög kapacitet inkluderar big data-analys, säkerhetskopiering och arkivsystem, bildlagring och strömmande ljud och video. För dessa typer av arbetsbelastningar är genomströmning (MB/s eller GB/s) det viktigaste måttet som definierar lagringsprestanda.
som visas i diagram 1 Large-object 100% HTTP GET och HTTP PUT arbetsbelastning uppvisade sublinjär skalbarhet när man ökar antalet RGW-värdar. Som sådan mätte vi ~ 5.5 GBps aggregerad bandbredd för HTTP GET och HTTP PUT arbetsbelastningar och intressant märkte vi inte resursmättnad i Ceph-klusternoder.
detta kluster kan churn ut mer om vi kan rikta mer belastning till det. Så vi identifierade två sätt att göra det. 1) Lägg till fler klientnoder 2) Lägg till fler RGW-noder. Vi kunde inte gå med alternativ 1 eftersom vi var begränsade av de fysiska klientnoder som finns tillgängliga i detta laboratorium. Så vi valde alternativ 2 och körde ytterligare en testrunda men den här gången med 14 RGWs.
som visas i diagram 2, jämfört med 7 RGW-testet, gav 14 RGW-test en 14% högre skrivprestanda, toppade vid ~6.3 GBps, på samma sätt visade HTTP GET-arbetsbelastningen 16% högre läsprestanda, toppade ~6.5 GBps. Detta var den maximala aggregerade genomströmningen som observerades på detta kluster, varefter media (HDD) mättnad märktes som avbildad i Figur 1. Baserat på resultaten tror vi att vi har lagt till fler Ceph OSD-noder i detta kluster, prestandan kunde ha skalats ytterligare tills den begränsades av resursmättnad.
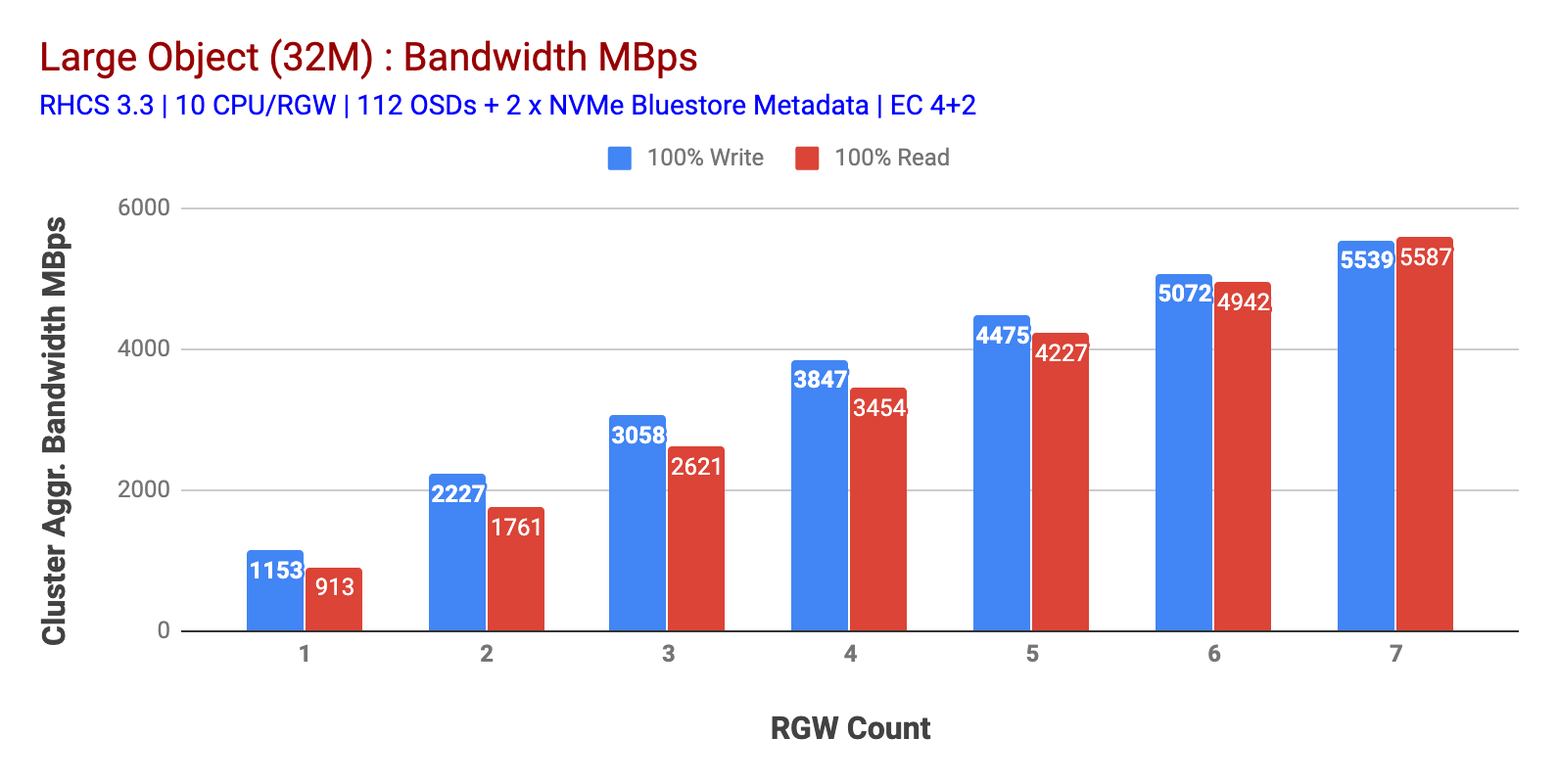
Diagram 1: stort Objekttest
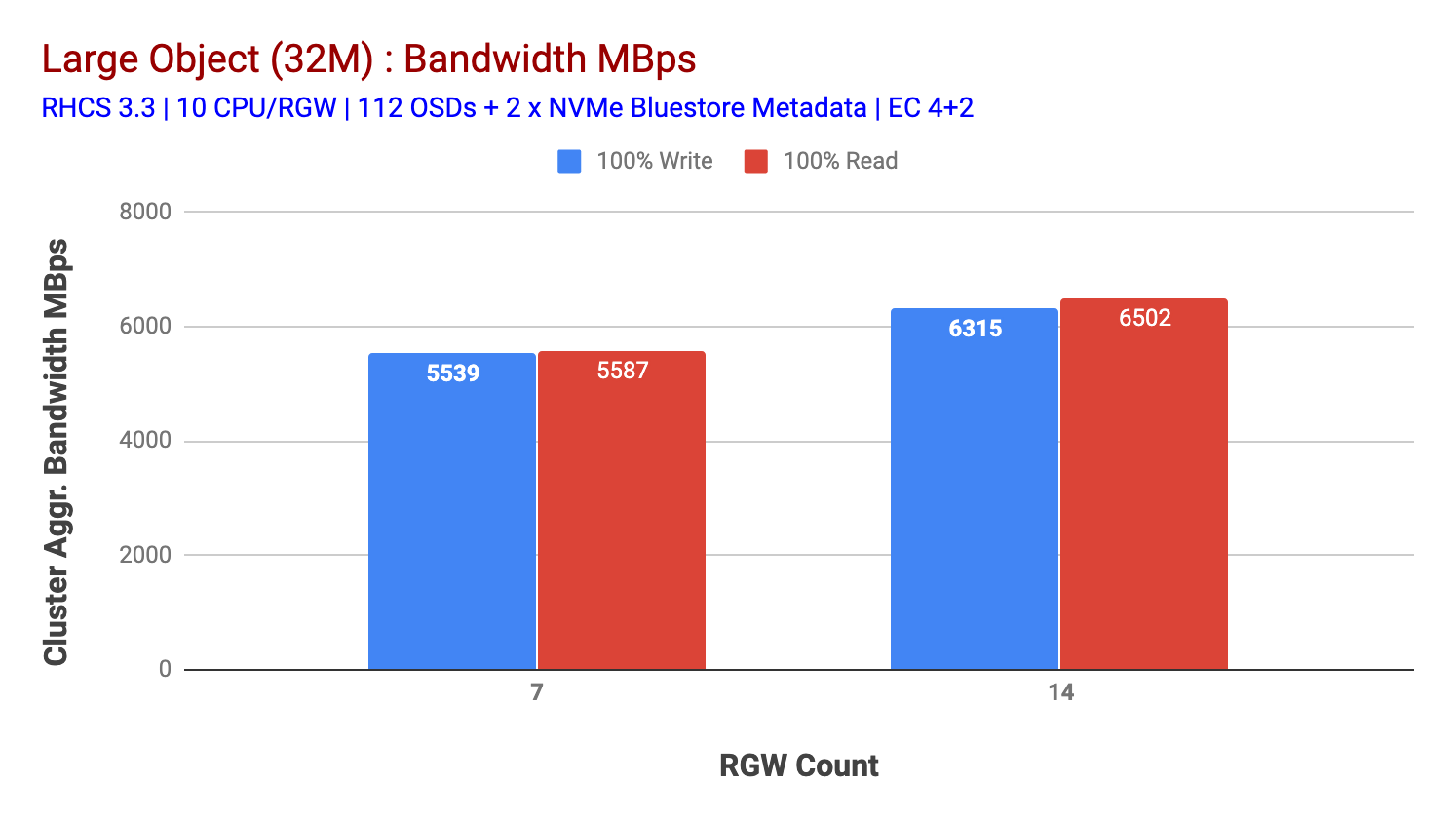
Diagram 2: stort Objekttest med 14 rgws
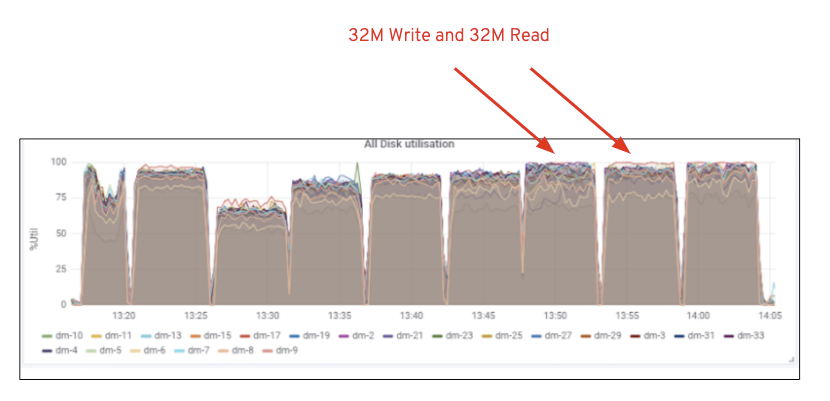
figur 1: Ceph OSD (HDD) mediautnyttjande
liten Objektbelastning
som visas i diagram 3 litet objekt 100% HTTP GET och HTTP PUT arbetsbelastningar uppvisade sublinjär skalbarhet vid ökning av antalet RGW-värdar. Som sådan mätte vi ~6.2 K Ops genomströmning för HTTP sätta på 9MS ansökan skriv latens och ~3.2 K Ops för HTTP få arbetsbelastningar med 7 RGW instanser.
fram till 7 RGW-instanser märkte vi inte resursmättnad, så vi fördubblades ner på RGW-instanser genom att skala dem till 14 och observerade försämrad prestanda för HTTP-arbetsbelastning som tillskrivs mediemättnad, medan HTTP får prestanda uppskalad och toppad vid ~4.5 K Ops. Som sådan kunde skrivprestanda ha skalat högre, om vi hade lagt till fler Ceph OSD-noder. När det gäller läsprestanda tror vi att lägga till fler klientnoder borde ha förbättrat det, men vi hade inga fler fysiska noder i labbet för att testa denna hypotes.
en annan intressant observation från Diagram 3 är den reducerade genomsnittliga svarstiden för HTTP-arbetsbelastningar som mättes vid 9 ms medan HTTP GET visade 17 ms Genomsnittlig latens mätt från applikationsgenererande arbetsbelastning. Vi tror att en av anledningarna till ensiffrig applikations latens för skriv arbetsbelastning är kombinationen av prestandaförbättring kommer från BlueStore OSD backend samt högpresterande Intel Optane NVMe används för att backa BlueStore metadata enhet. Det är värt att notera att uppnå ensiffrig skriv Genomsnittlig latens från ett Objektlagringssystem är icke-trivialt. Som avbildat i diagram 3 kan Ceph-objektlagring när den distribueras med BlueStore OSD backend och Intel Optane för metadata uppnå skrivgenomströmningen vid lägre svarstid.
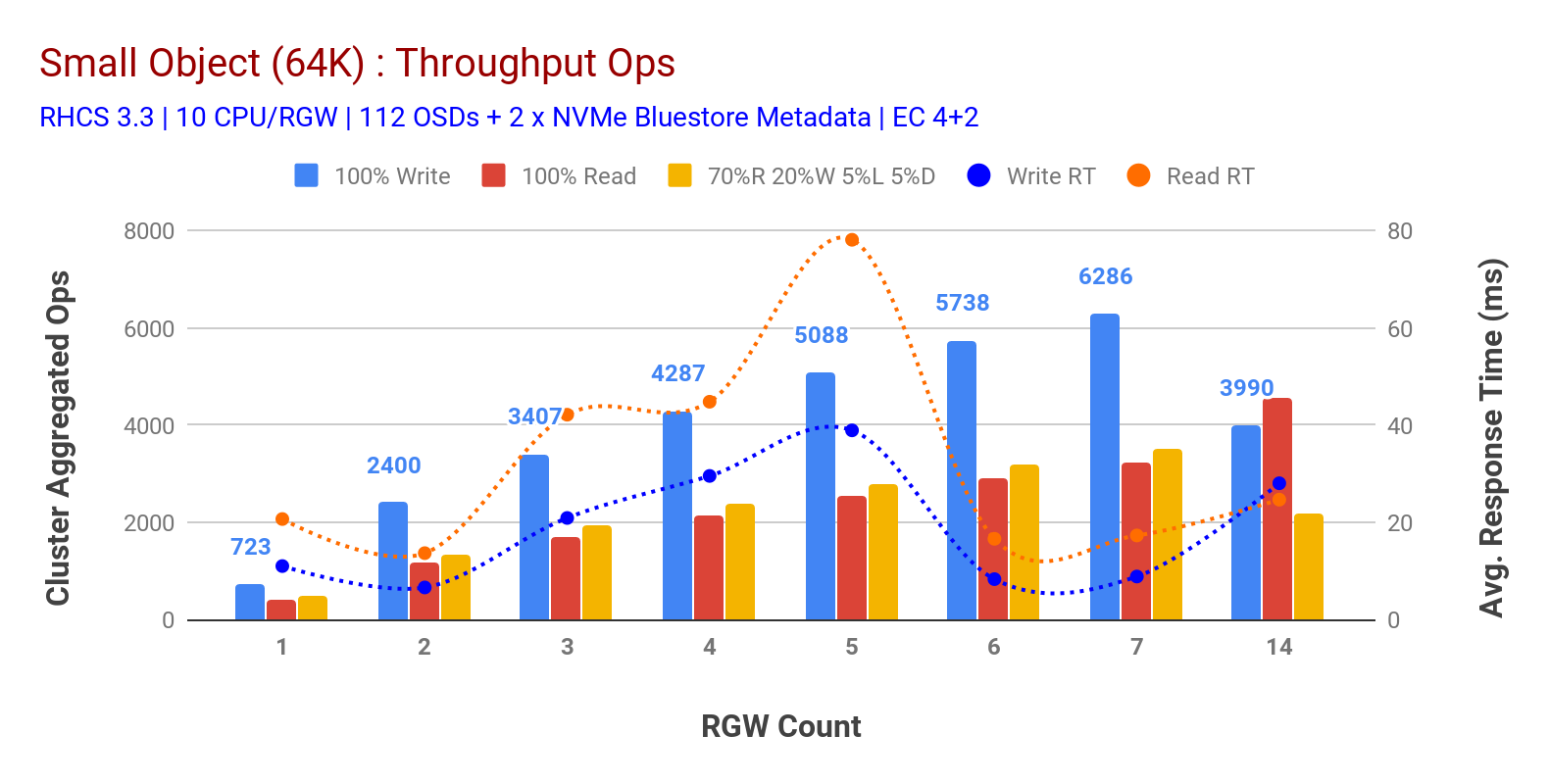
Diagram 3: litet Objekttest
sammanfattning och upp nästa
det fasta klustret som används i denna testning har levererat ~6,3 GBps och ~6,5 GBps stor objektbandbredd för skriv-och läsarbetsbelastningar respektive. Samma kluster för små objekt storlek har levererat ~6.5 K Ops och ~4.5 K Ops för skriva och läsa arbetsbelastning, respektive.
resultaten har också visat att BlueStore OSD i kombination med Intel Optane NVMe har levererat ensiffrig Genomsnittlig applikationsfördröjning, vilket är icke-trivialt för objektlagringssystem. I nästa inlägg kommer vi att undersöka prestanda i samband med bucket dynamic sharding och hur pre-sharding bucket kan hjälpa till med deterministisk prestanda.