
am testat o varietate de configurații, dimensiuni de obiecte și numărătoare de lucrători clienți pentru a maximiza debitul unui cluster Ceph cu șapte noduri pentru sarcini de lucru mici și mari. După cum este detaliat în primul post, Clusterul Ceph a fost construit folosind un singur OSD (Object Storage Device) configurat pe HDD, având un total de 112 OSD-uri pe clusterul Ceph. În această postare, vom înțelege performanța de top pentru diferite dimensiuni de obiecte și sarcini de lucru.
notă: Termenii ” citit „și HTTP GET sunt folosiți interschimbabil în această postare, la fel ca și termenii HTTP PUT și” scrie.”
volumul de lucru cu obiecte mari
sarcinile de lucru secvențiale cu obiecte mari de intrare/ieșire (I / O) sunt unul dintre cele mai frecvente cazuri de utilizare pentru stocarea obiectelor Ceph. Aceste sarcini de lucru cu randament ridicat includ analize de date mari, sisteme de backup și arhivare, stocare de imagini și streaming audio și video. Pentru aceste tipuri de sarcini de lucru tranzitată (MB/s sau GB/s) este metrica cheie care definește performanța de stocare.
așa cum se arată în graficul 1 Obiect mare 100% HTTP GET și HTTP pune volumul de muncă expuse scalabilitate sub-lineară atunci când incrementarea numărului de gazde RGW. Ca atare, am măsurat ~ 5.5 Gbps lățime de bandă agregată pentru HTTP GET și HTTP PUT sarcini de lucru și interesant nu am observat saturația resurselor în nodurile clusterului Ceph.
acest cluster poate produce mai mult dacă putem direcționa mai multă sarcină către el. Așa că am identificat două moduri de a face acest lucru. 1) Adăugați mai multe noduri client 2) Adăugați mai multe noduri RGW. Nu am putut merge cu opțiunea 1, deoarece am fost limitați de nodurile fizice ale clientului disponibile în acest laborator. Așa că am optat pentru opțiunea 2 și am efectuat o altă rundă de teste, dar de data aceasta cu 14 RGWs.
așa cum se arată în graficul 2, comparativ cu testul 7 RGW, testul 14 RGW a dat o performanță de scriere cu 14% mai mare, topping la ~6,3 GBps, în mod similar, volumul de lucru HTTP GET a arătat o performanță de citire cu 16% mai mare, topping ~6,5 GBps. Acesta a fost debitul maxim agregat observat pe acest cluster după care s-a observat saturația mediilor (HDD) așa cum este descris în Figura 1. Pe baza rezultatelor, credem că am adăugat mai multe noduri Ceph OSD la acest cluster, performanța ar fi putut fi scalată și mai mult, până la limitarea saturației resurselor.
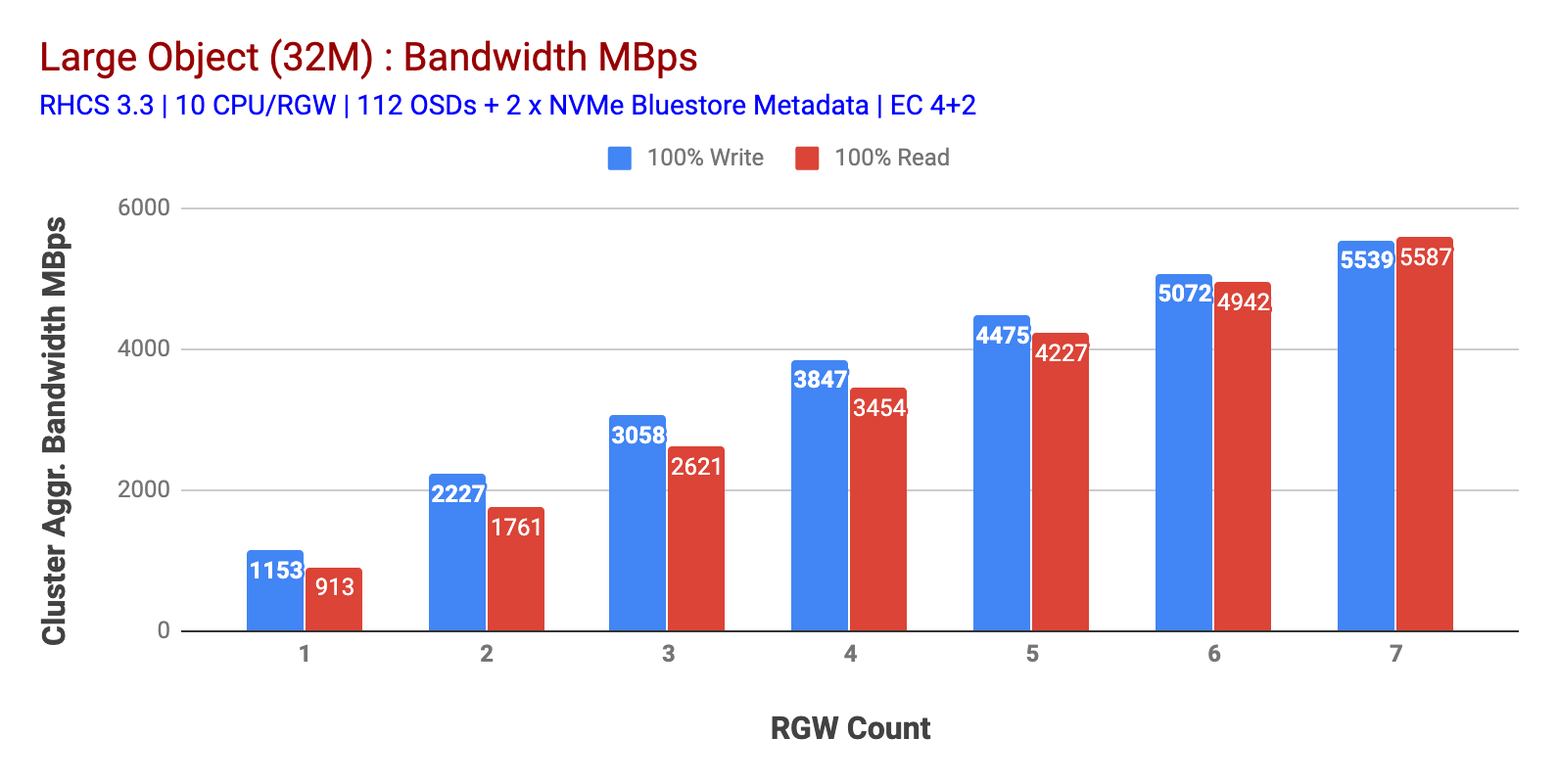
graficul 1: Test obiect mare
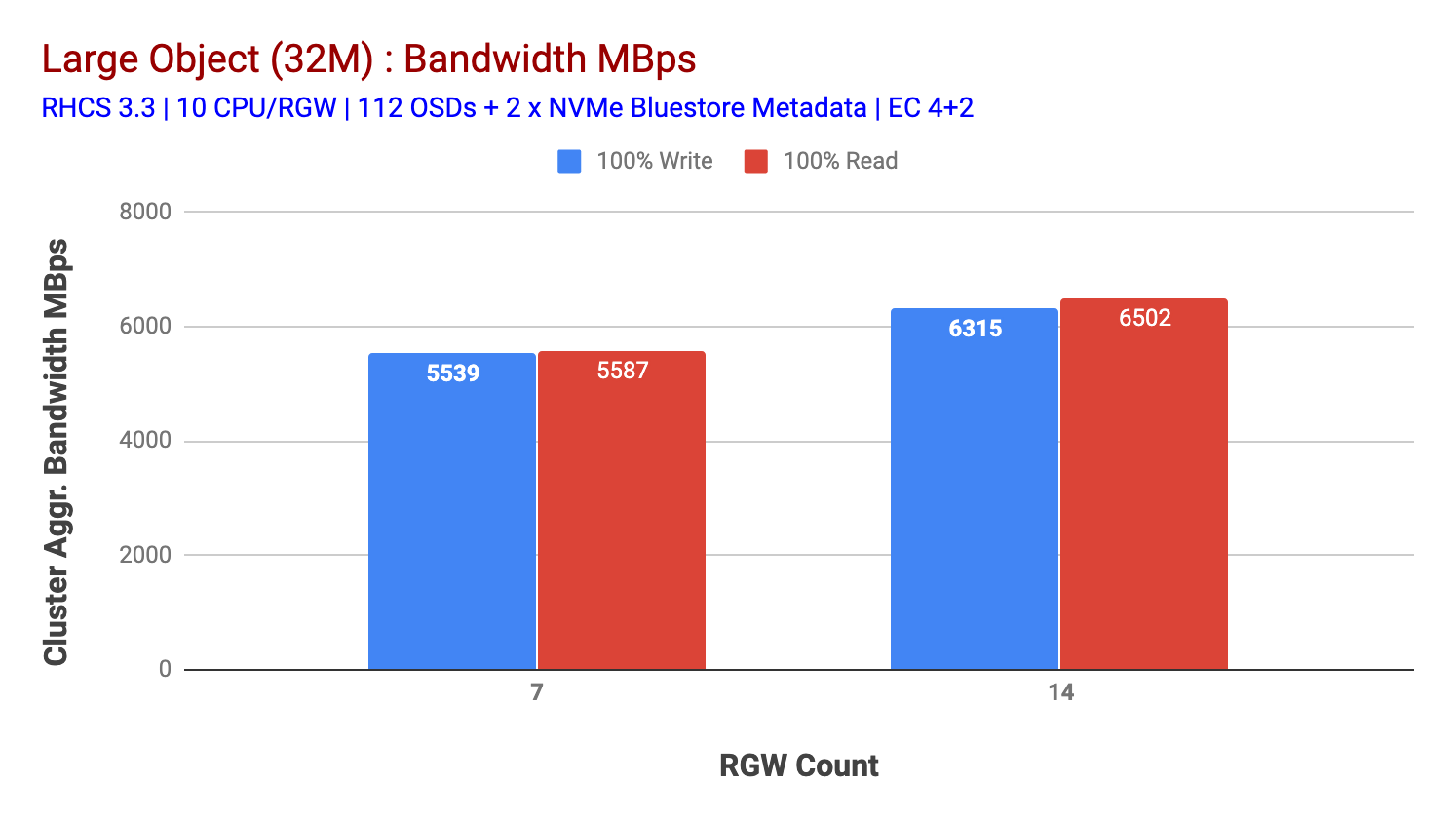
Graficul 2: test obiect mare cu 14 rgws
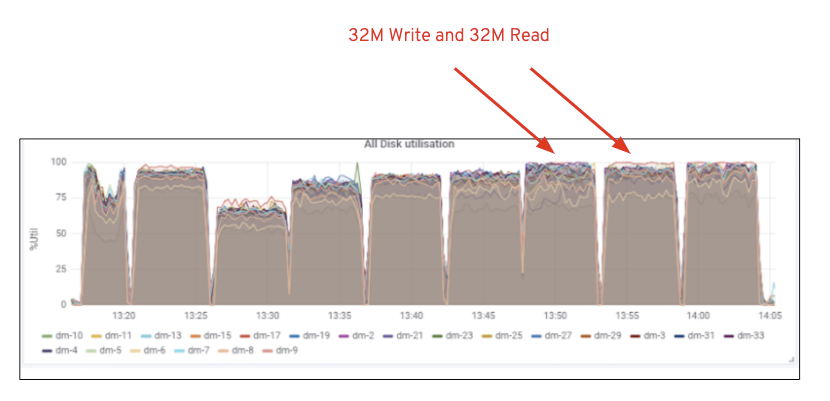
figura 1: Ceph OSD (HDD) utilizarea mass-media
volumul de lucru obiect mic
așa cum se arată în graficul 3 obiect mic 100% HTTP GET și HTTP pune sarcini de lucru expuse scalabilitate sub-lineară atunci când incrementarea numărul de gazde RGW. Ca atare, am măsurat ~6.2 K Ops tranzitată pentru HTTP pune la 9MS cerere scrie latență și ~ 3.2 K Ops pentru HTTP obține sarcini de lucru cu 7 instanțe RGW.
până la 7 instanțe RGW, nu am observat saturația resurselor, așa că am dublat instanțele RGW prin scalarea celor la 14 și am observat performanțe degradate pentru volumul de lucru HTTP PUT, care este atribuit saturației media, în timp ce performanța HTTP GET a crescut și a depășit la ~4.5 K Ops. Ca atare, performanța de scriere ar fi putut fi scalată mai mare, dacă am fi adăugat mai multe noduri Ceph OSD. În ceea ce privește performanța citirii, credem că adăugarea mai multor noduri client ar fi trebuit să o îmbunătățească, dar nu am mai avut noduri fizice în laborator pentru a testa această ipoteză.
o altă observație interesantă din graficul 3 este timpul mediu de răspuns redus pentru sarcinile de lucru HTTP PUT care au fost măsurate la 9ms, în timp ce HTTP GET a arătat 17ms de latență medie măsurată din volumul de muncă generator de aplicații. Credem că unul dintre motivele latenței aplicației cu o singură cifră pentru volumul de lucru de scriere este combinația de îmbunătățire a performanței provenind de la backend-ul BlueStore OSD, precum și de înaltă performanță Intel Optane NVMe folosit pentru a susține dispozitivul de metadate BlueStore. Este demn de remarcat faptul că realizarea unei latențe medii de scriere cu o singură cifră dintr-un sistem de stocare a obiectelor nu este banală. Așa cum este descris în graficul 3, Ceph object storage atunci când este implementat cu bluestore OSD backend și Intel Optane pentru metadate poate atinge debitul de scriere la un timp de răspuns mai mic.
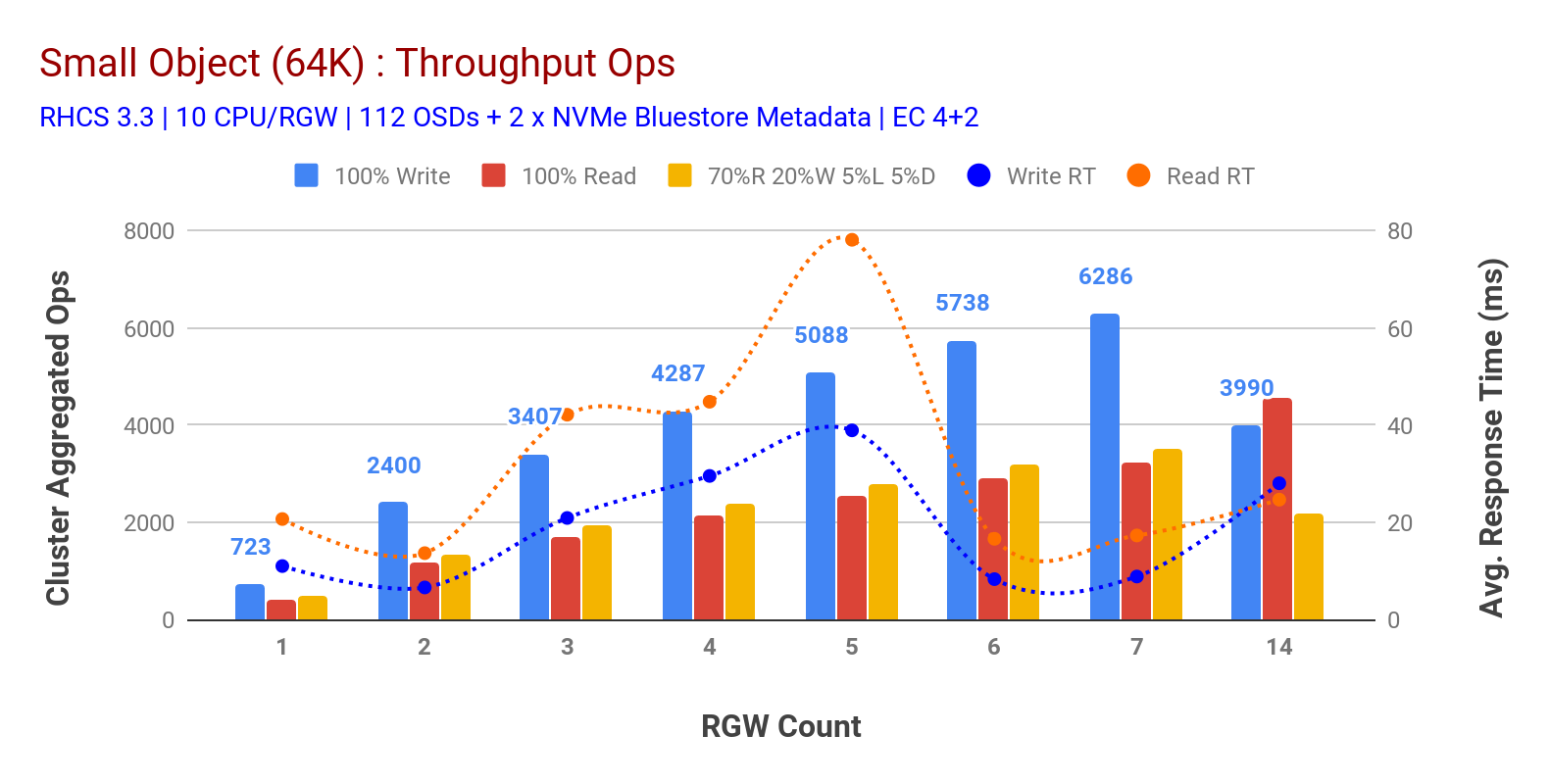
graficul 3: Test de obiecte mici
rezumat și în continuare
clusterul de dimensiuni fixe utilizat în această testare a livrat ~6,3 GBps și ~6,5 GBps lățime de bandă mare pentru obiecte de scriere și citire, respectiv. Același cluster pentru dimensiunea obiectelor mici a livrat ~6,5 K Ops și ~ 4,5 K Ops pentru volumul de lucru de scriere și citire, respectiv.
rezultatele au arătat, de asemenea, că BlueStore OSD în combinație cu Intel Optane NVMe a livrat o latență medie a aplicației cu o singură cifră, care este non-banală pentru sistemele de stocare a obiectelor. În următoarea postare, vom explora performanța asociată cu shardingul dinamic al Cupei și modul în care Cupa pre-sharding poate ajuta la performanța deterministă.