
testamos uma variedade de Configurações, tamanhos de objetos, e contagens de trabalhadores clientes, a fim de maximizar o rendimento de um cluster de sete nós Ceph para pequenas e grandes cargas de trabalho de objetos. Como detalhado no primeiro post, o cluster Ceph foi construído usando um único OSD (dispositivo de armazenamento de objetos) configurado por HDD, com um total de 112 OSDs por cluster Ceph. Neste post, vamos entender o desempenho de topo de linha para diferentes tamanhos de objetos e cargas de trabalho.Nota: Os Termos ” read “e HTTP GET são usados intercambiavelmente durante todo este post, assim como os Termos HTTP PUT e “write”.”
carga de trabalho de grandes objetos
entradas/saídas sequenciais de grandes objetos (I / O) são um dos casos de uso mais comuns para armazenamento de objetos Ceph. Estas cargas de trabalho de alta capacidade incluem grande análise de dados, backup, e sistemas de arquivos, armazenamento de imagens, e streaming de áudio, e vídeo. Para estes tipos de transferência de carga de trabalho (MB/s ou GB/s) é a métrica chave que define o desempenho de armazenamento.
Como mostrado no gráfico 1, o ‘Large-object’ 100% HTTP GET e o ‘HTTP PUT’ exibiram a escalabilidade sub-linear ao aumentar o número de máquinas RGW. Como tal, medimos ~5.5 GBps largura de banda agregada para HTTP GET e HTTP colocar cargas de trabalho e curiosamente não notamos saturação de recursos em nós de cluster Ceph.
Este aglomerado pode produzir mais se pudermos direcionar mais carga para ele. Então, identificamos duas maneiras de fazer isso. 1) adicionar mais nós clientes 2) adicionar mais nós RGW. Não podíamos escolher a opção 1, pois estávamos limitados pelos nós de clientes físicos disponíveis neste laboratório. Então optamos pela Opção 2 e fizemos outra rodada de testes, mas desta vez com 14 RGWs.
Como mostrado no gráfico 2, em comparação com o teste de 7 RGW, o teste de 14 RGW rendeu um desempenho de escrita 14% maior, atingindo ~6.3 GBps, da mesma forma, a carga de trabalho HTTP GET mostrou 16% maior desempenho de leitura, superando ~6.5 GBps. Este foi o débito máximo agregado observado neste aglomerado após o qual a saturação de mídia (HDD) foi observada como representado na Figura 1. Com base nos resultados, acreditamos que adicionamos mais nós Ceph OSD a este cluster, o desempenho poderia ter sido escalado ainda mais, até ser limitado pela saturação de recursos.
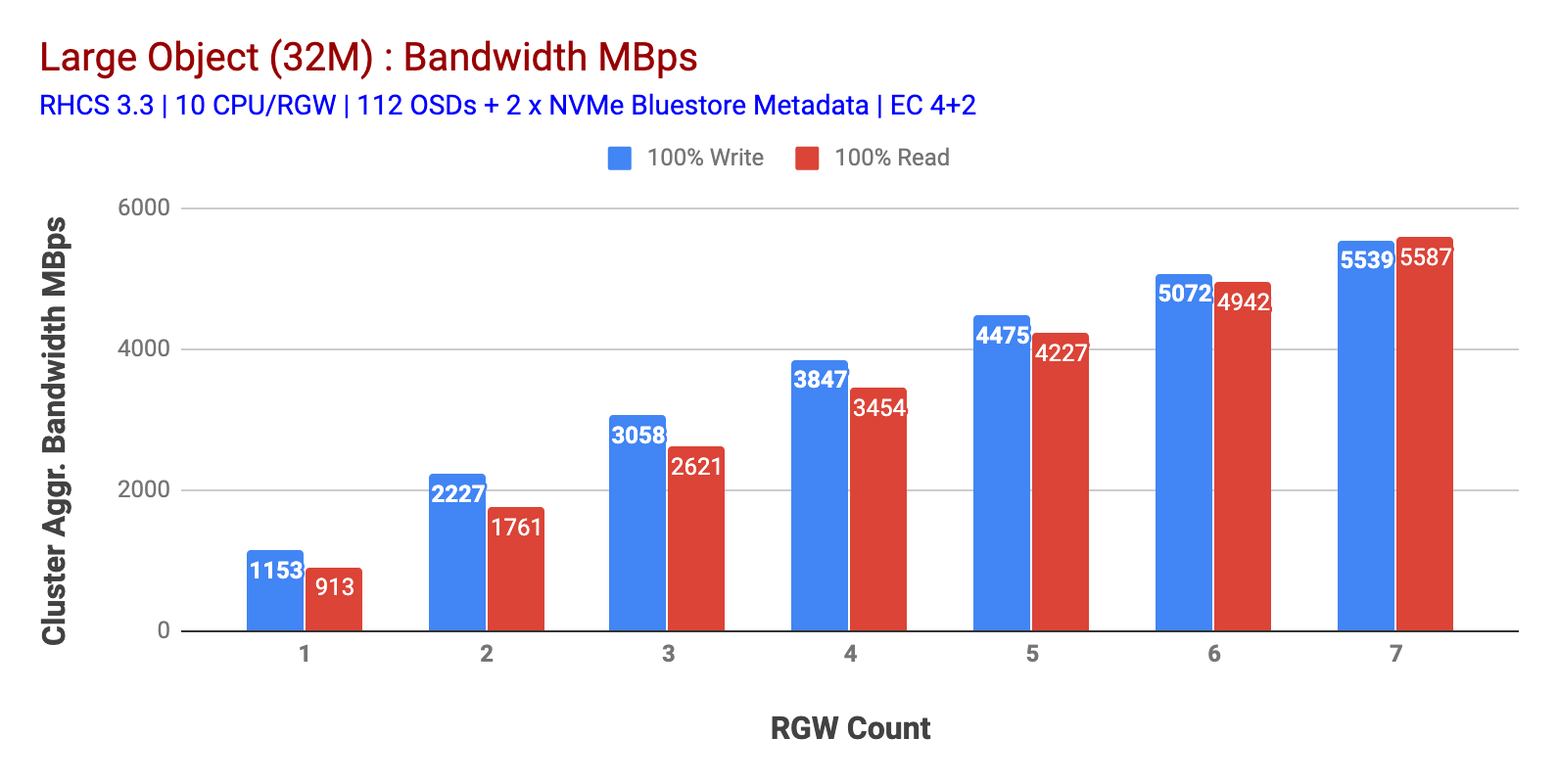
Gráfico 1: Grande Objeto de teste
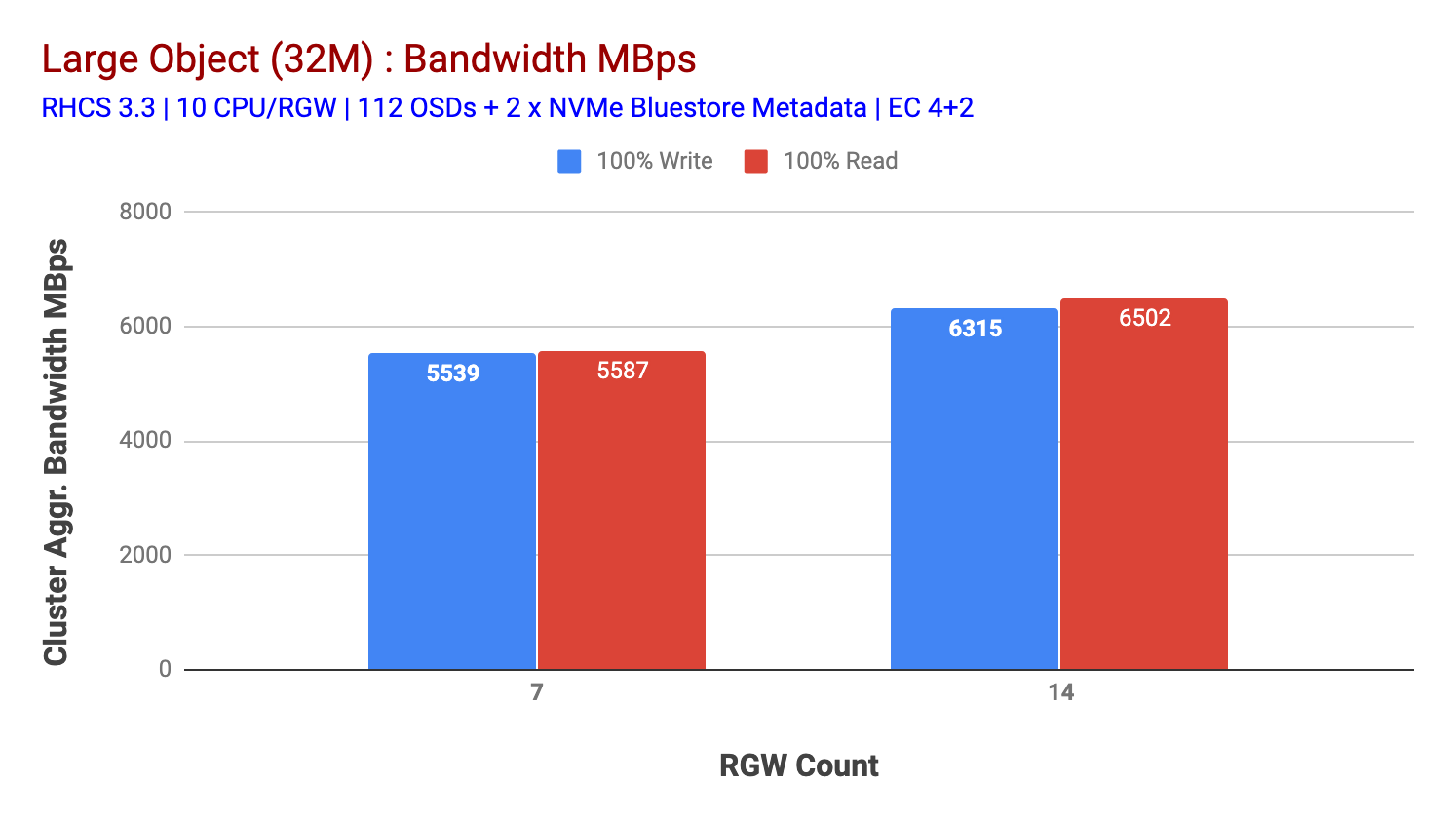
Gráfico 2: Grande Objeto de teste com 14 RGWs
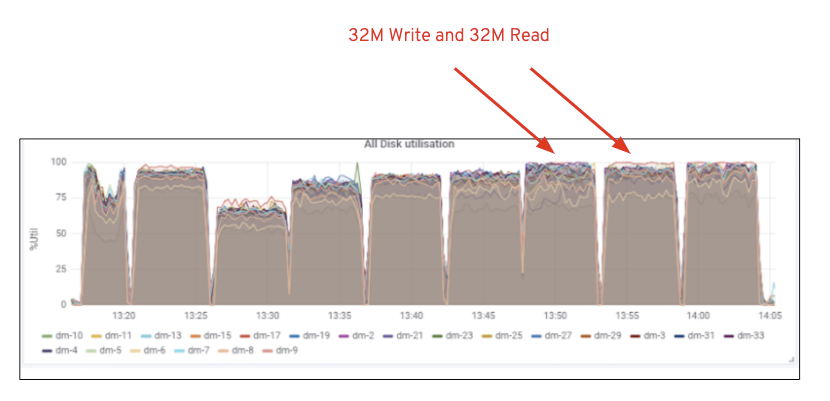
a Figura 1: Utilização multimédia do Ceph OSD (HDD)
pequena carga de trabalho de objectos
como mostrado no gráfico 3 pequenos objectos 100% HTTP GET e HTTP PUT workloads exibiram escalabilidade sub-linear ao aumentar o número de máquinas RGW. Como tal, medimos o débito de ~6.2 K Ops para HTTP PUT em 9ms aplicação write latency e ~3.2 K Ops para HTTP GET workloads com 7 instâncias RGW.
até 7 instâncias RGW, nós não notamos a saturação de recursos, então nós dobramos em instâncias RGW, escalando para 14 e observado desempenho degradado para HTTP PUT carga de trabalho que é atribuído à saturação de mídia, enquanto HTTP obter desempenho escalado para cima e para cima em ~4.5 K Ops. Como tal, o desempenho de escrita poderia ter escalado mais alto, se tivéssemos adicionado mais nós Ceph OSD. No que diz respeito ao desempenho da leitura, acreditamos que a adição de mais nós clientes deveria tê-lo melhorado, mas não tínhamos mais nós físicos no laboratório para testar esta hipótese.
outra observação interessante do Gráfico 3 é o tempo de resposta médio reduzido para HTTP PUT workloads que calculou em 9ms, enquanto HTTP GET mostrou 17ms de latência média medida a partir da carga geradora de Aplicação. Acreditamos que uma das razões para a latência de aplicação de um dígito para a carga de trabalho de escrita é a combinação de melhoria de desempenho vindo da infra-estrutura BlueStore OSD, bem como o alto desempenho Intel Optane NVMe usado para back bluestore metadata dispositivo. Vale a pena notar que alcançar uma latência média de um dígito de escrita a partir de um sistema de armazenamento de objetos não é trivial. Como descrito no gráfico 3, O armazenamento de objetos Ceph quando implantado com a infra-estrutura BlueStore OSD e Intel Optane para metadados pode alcançar o rendimento de escrita em menor tempo de resposta.
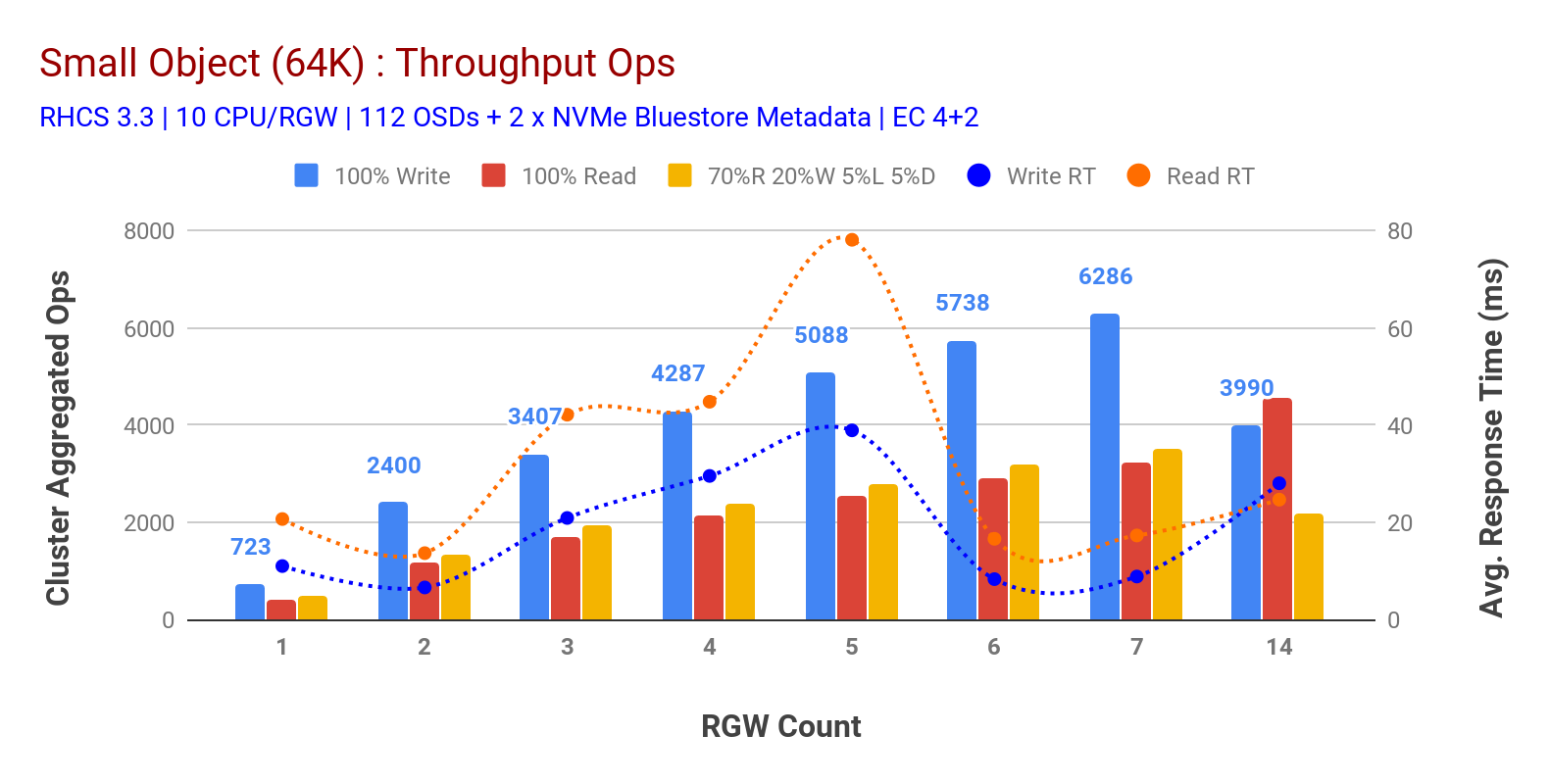
Chart 3: Small Object Test
Summary and up next
The fixed-size cluster used in this testing has delivered ~6.3 GBps and ~6.5 GBps large object bandwidth for write and read workloads respectively. O mesmo conjunto para tamanho de objeto pequeno entregou ~6.5 K Ops e ~4.5 K Ops para escrever e ler carga de trabalho, respectivamente.
os resultados também mostraram que o BlueStore OSD em combinação com o Intel Optane NVMe entregou latência média de aplicação de um dígito, o que não é trivial para sistemas de armazenamento de objetos. No próximo post, vamos explorar o desempenho associado com o bucket sharding dinâmico e como o balde pré-sharding pode ajudar no desempenho determinístico.