
przetestowaliśmy różne konfiguracje, rozmiary obiektów i liczbę pracowników klienta, aby zmaksymalizować przepustowość klastra Ceph o siedmiu węzłach dla małych i dużych obciążeń obiektowych. Jak opisano w pierwszym poście, Klaster Ceph został zbudowany przy użyciu pojedynczego OSD (Object Storage Device) skonfigurowanego na dysk twardy, posiadającego łącznie 112 OSD na klaster Ceph. W tym poście zrozumiemy najwyższą wydajność dla różnych rozmiarów obiektów i obciążeń.
Uwaga: Terminy „read” I HTTP GET są używane zamiennie w tym poście, podobnie jak terminy HTTP PUT i ” write.”
obciążenia dużych obiektów
obciążenia dużych obiektów sekwencyjnymi wejściami/wyjściami (I/O) są jednym z najczęstszych przypadków użycia pamięci obiektowej Ceph. Te wysokowydajne obciążenia obejmują analitykę dużych zbiorów danych, Systemy tworzenia kopii zapasowych i archiwizacji, przechowywanie obrazów oraz strumieniowe przesyłanie audio i wideo. Dla tego typu obciążeń przepustowość (MB / s lub GB / s) jest kluczowym wskaźnikiem określającym wydajność pamięci masowej.
jak pokazano na wykresie 1 duży obiekt 100% HTTP GET i HTTP PUT workload wykazywały podliniową skalowalność przy zwiększaniu liczby hostów RGW. W związku z tym mierzyliśmy zagregowaną przepustowość ~5,5 GBps dla obciążeń HTTP GET i HTTP PUT i co ciekawe nie zauważyliśmy nasycenia zasobów w węzłach klastra Ceph.
ten klaster może się bardziej rozwinąć, jeśli możemy skierować do niego więcej obciążeń. Zidentyfikowaliśmy dwa sposoby, aby to zrobić. 1) Dodaj więcej węzłów klienta 2) Dodaj więcej węzłów RGW. Nie mogliśmy skorzystać z opcji 1, ponieważ byliśmy ograniczeni przez fizyczne węzły klienta dostępne w tym laboratorium. Zdecydowaliśmy się więc na opcję 2 i przeprowadziliśmy kolejną rundę testów, ale tym razem z 14 RGWs.
jak pokazano na wykresie 2, w porównaniu do testu 7 RGW, test 14 RGW dał o 14% wyższą wydajność zapisu, osiągając ~6,3 Gb / s, podobnie obciążenie HTTP GET wykazało 16% wyższą wydajność odczytu, zwiększając ~6,5 Gb / s. Była to maksymalna zagregowana przepustowość zaobserwowana w tym klastrze, po której zauważono nasycenie nośników (HDD), jak pokazano na fig. Opierając się na wynikach, uważamy, że gdybyśmy dodali więcej węzłów Ceph OSD do tego klastra, wydajność mogłaby być jeszcze bardziej skalowana, aż do ograniczenia przez nasycenie zasobów.
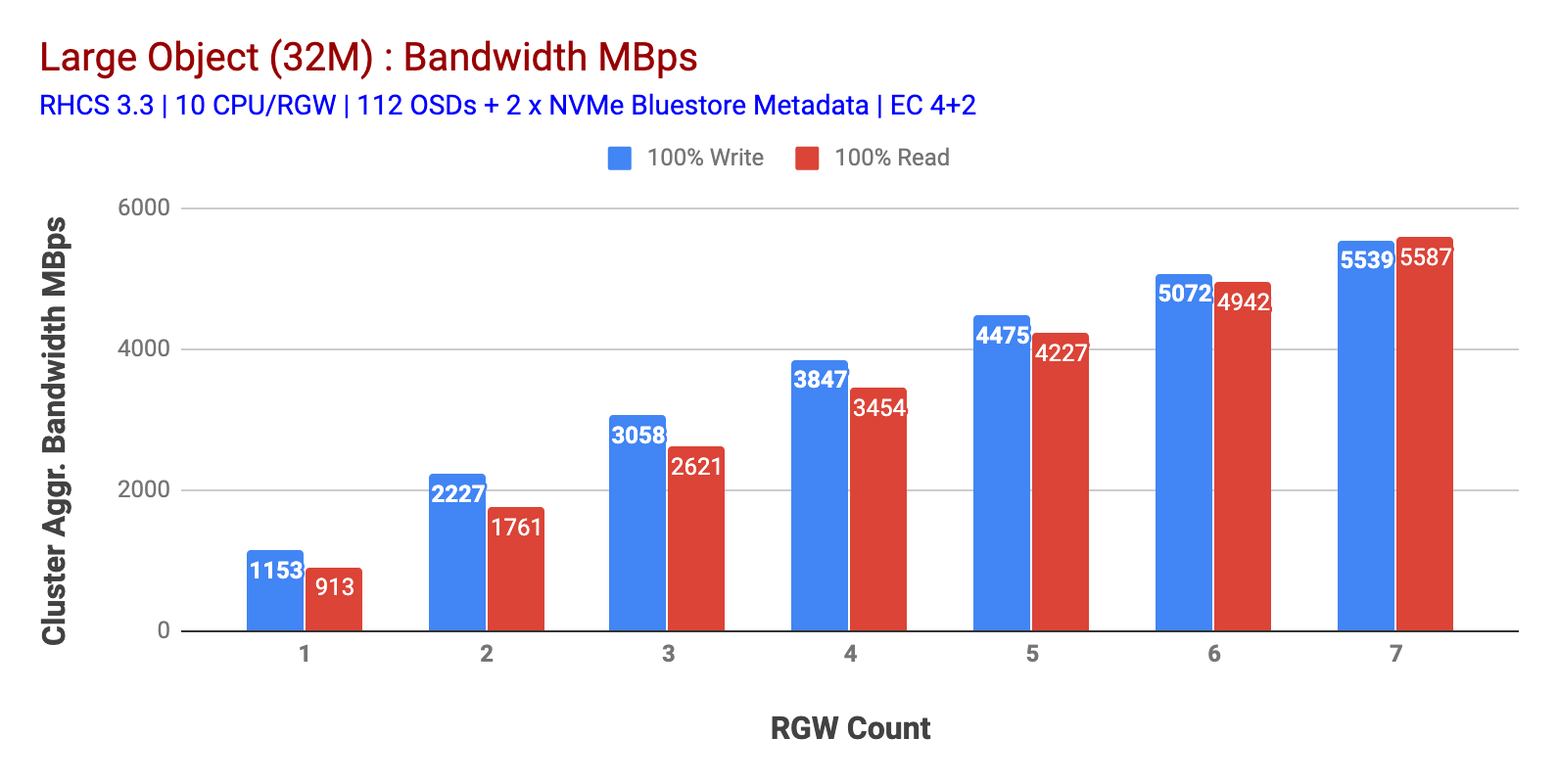
wykres 1: Test dużego obiektu
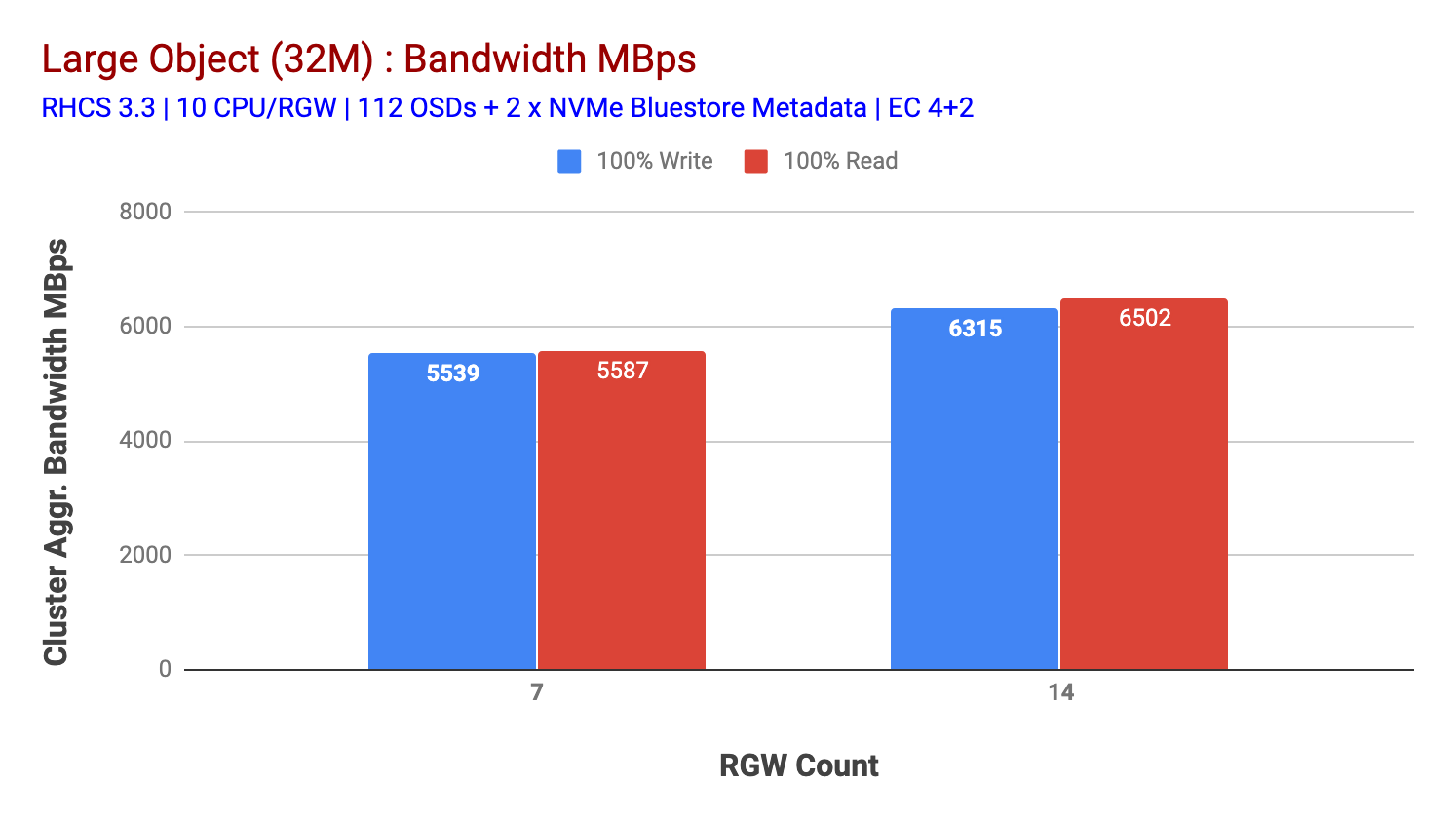
wykres 2: Test dużego obiektu z 14 RGWs
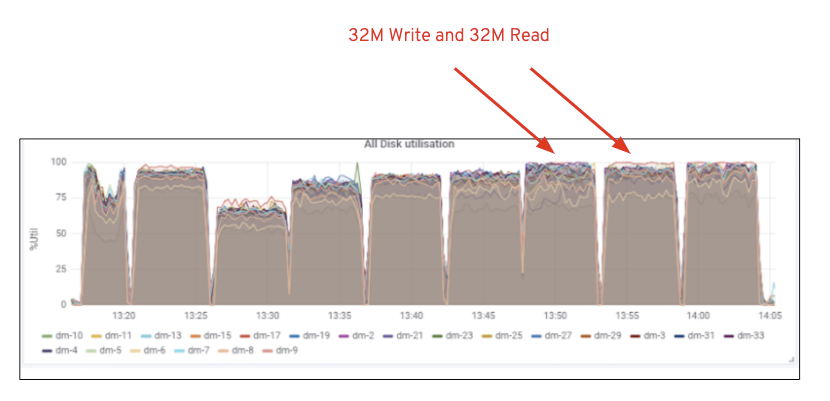
rysunek 1: Wykorzystanie nośników Ceph OSD (HDD)
małe obciążenie obiektów
jak pokazano na wykresie 3 małe obiekty 100% obciążenia HTTP GET i HTTP PUT wykazywały podliniową skalowalność podczas zwiększania liczby hostów RGW. W związku z tym mierzyliśmy przepustowość ~ 6.2 K Ops dla HTTP przy 9ms opóźnieniu zapisu aplikacji i ~3.2 K Ops dla HTTP pobiera obciążenia z 7 wystąpieniami RGW.
aż do 7 wystąpień RGW nie zauważyliśmy nasycenia zasobów, więc podwoiliśmy liczbę wystąpień RGW, skalując je do 14 i obserwując spadek wydajności dla HTTP nakładało obciążenie, które jest przypisywane nasyceniu mediów, podczas gdy http zwiększał wydajność i zwiększał ją do ~4.5 K Ops. W związku z tym wydajność zapisu mogłaby być skalowana wyżej, gdybyśmy dodali więcej węzłów Ceph OSD. Jeśli chodzi o wydajność odczytu, uważamy, że dodanie większej liczby węzłów klienta powinno ją poprawić, ale nie mieliśmy więcej fizycznych węzłów w laboratorium, aby przetestować tę hipotezę.
kolejną ciekawą obserwacją z wykresu 3 jest skrócony średni czas odpowiedzi dla obciążeń HTTP PUT, które mierzono na poziomie 9ms, podczas gdy HTTP GET pokazywał 17ms średniego opóźnienia mierzonego od obciążenia generowanego przez aplikację. Uważamy, że jednym z powodów jednocyfrowego opóźnienia aplikacji dla obciążenia pracą zapisu jest połączenie poprawy wydajności pochodzącej z zaplecza OSD BlueStore, a także wysokowydajnego urządzenia Intel Optane NVMe używanego do przechowywania metadanych BlueStore. Warto zauważyć, że osiągnięcie średniego opóźnienia zapisu jednocyfrowego z systemu Object Storage nie jest trywialne. Jak pokazano na wykresie 3, Ceph object storage po wdrożeniu z zapleczem OSD BlueStore i Intel Optane for metadane może osiągnąć wydajność zapisu przy krótszym czasie reakcji.
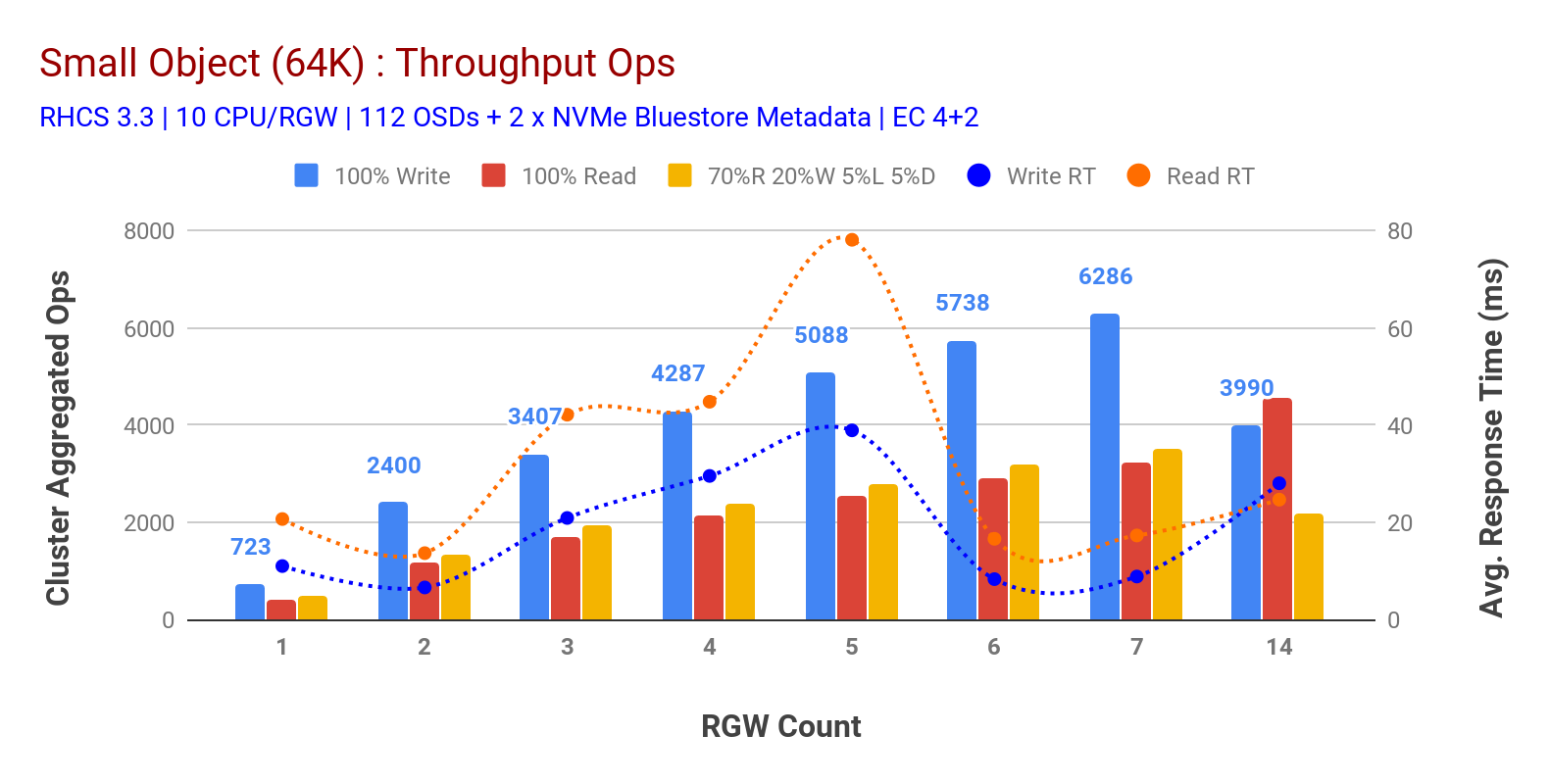
Wykres 3: Test małych obiektów
Podsumowanie i dalej
klaster o stałej wielkości używany w tych testach zapewnia odpowiednio ~6,3 Gb / s i ~6,5 Gb / s dużą przepustowość obiektów do zapisu i odczytu obciążeń. Ten sam klaster dla małych obiektów dostarczył odpowiednio ~6,5 K Ops i ~ 4,5 K Ops dla obciążenia zapisu i odczytu.
wyniki wykazały również, że BlueStore OSD w połączeniu z Intel Optane NVMe zapewnia jednocyfrowe średnie opóźnienie aplikacji, co jest nietrywialne w przypadku systemów obiektowej pamięci masowej. W następnym poście przyjrzymy się wydajności związanej z dynamicznym shardingiem łyżki oraz temu, w jaki sposób łyżka wstępnego shardingu może pomóc w deterministycznej wydajności.