
funkcjonalność
Poniżej znajduje się lista podstawowych funkcjonalności MDF:
-
wyszukiwanie struktury chemicznej:
-
wyszukiwanie struktury chemicznej może być połączone z wyszukiwaniem właściwości
-
wyszukiwanie struktury chemicznej jest pagedowane i buforowane
-
Wsparcie dla związków wieloskładnikowych (mieszanin)
-
3 obiekty do wyszukiwania struktury chemicznej: ChemicalCompound, Containable i ChemicalCompoundContainer
-
Import i eksport plików SD dla powyższych 3 podmiotów
-
dostęp do transakcyjnych baz danych
-
opcjonalne bezpieczeństwo (autoryzacja)
dzięki projektowi i funkcjonalności MDF można zbudować wiele różnych typów systemów, takich jak systemy rejestracji, systemy inwentaryzacji lub po prostu prosta złożona baza danych. Chociaż możesz również stworzyć swój własny ELN, istnieje również darmowy Indigo ELN. Ten ELN został stworzony przez GGA Software Services i jest używany w Pfizer .
w przeciwieństwie do MolDB5R i MyMolDB , MDF nie jest w pełni funkcjonalną samodzielną aplikacją internetową z wyszukiwaniem struktury chemicznej. Jak sama nazwa wskazuje jest to framework, aby uprościć tworzenie takiej aplikacji. MDF może być również używany do tworzenia lokalnych lub klient-serwer aplikacji desktopowych. MDF jest skierowany do twórców oprogramowania i nie jest przeznaczony do użytku przez samych naukowców. Jednak funkcje MDF są bardzo wytrzymałe. Wyszukiwanie struktury chemicznej odbywa się w bazie danych, a nie w kodzie aplikacji. W związku z tym można wyszukiwać według struktury chemicznej i innych właściwości w tym samym czasie, wyniki mogą być sortowane według wielu właściwości i mogą być paged (SQL OFFSET i klauzule LIMIT). Zauważ, że jeśli wykonasz wyszukiwanie struktury chemicznej w kodzie aplikacji, każde zapytanie będzie wymagało co najmniej dwóch przejazdów do bazy danych, a mianowicie wyszukiwania struktury, a następnie filtrowania według innych właściwości, sortowania i / lub ograniczania. Oba muszą się zdarzyć w tej samej transakcji. Nie ustalono, czy MolDB5R i MyMolDB rzeczywiście robią to w tej samej transakcji.
w MDF związki chemiczne mogą być związane z zawartością, która w systemach rejestracji byłaby partia lub w systemie inwentaryzacji dużo. Konkretna fizycznie dostępna Próbka w butelce z kodem kreskowym może być następnie powiązana z pojemnikiem. Pojemniki te można również przeszukiwać według struktury chemicznej. Jest to podstawa do stworzenia systemu inwentaryzacji. Programiści mogą dodać dowolną liczbę dodatkowych właściwości do każdej z jednostek, a wszystkie z nich można przeszukiwać wraz ze strukturą chemiczną.
cały dostęp do danych w MDF jest transakcyjny, aby zapobiec niespójności danych. MDF może być skonfigurowany do korzystania z puli połączeń z bazą danych. Podczas odpytywania RDBMS tworzenie połączenia często zajmuje więcej czasu niż samo zapytanie, a zatem, jeśli masz już otwarte połączenia, Czas odpowiedzi może zostać skrócony.
do wyszukiwania podobieństw MDF ujawnił algorytmy dostarczone przez wkład Bingo, które są Tanimoto, Tversky i Euklidesowe metryki dla podstruktur.
MDF jest gotowy do użycia z zabezpieczeniem sprężynowym. Bezpieczeństwo jest opcjonalne. MDF oferuje bezpieczeństwo na poziomie metody (autoryzacja). Nie oferuje żadnych funkcji uwierzytelniania.
obsługa mieszanek
MDF obsługuje wieloskładnikowe związki chemiczne. Wyszukiwanie według podstruktury zwróci wszystkie związki, które mają co najmniej jeden składnik (strukturę chemiczną) pasujący do struktury zapytania. Jest to ważne, ponieważ produkty reakcji, które mogą zostać wprowadzone do systemu rejestracji chemicznej, są prawie zawsze mieszaninami, chyba że zostanie przeprowadzone intensywne oczyszczanie.
Jeśli wpis w importowanym pliku SD składa się z wielu rozłączonych struktur, zakłada się, że ten wpis jest mieszaniną, a każda struktura jest przechowywana jako oddzielna struktura chemiczna.
normalizacja struktury
domyślnie MDF przechowuje struktury chemiczne, które są przesyłane. MDF nie wykonuje żadnej standaryzacji / normalizacji struktur chemicznych. Programista korzystający z MDF musi upewnić się, że struktury chemiczne są prawidłowo znormalizowane przed zapisaniem ich do bazy danych. Obecnie sugeruje się, aby Programiści implementowali taką funkcję przez nadpisanie metody preSave () ChemicalCompoundServiceImpl. Metoda ta jest wywoływana przed utworzeniem lub aktualizacją jakiegokolwiek związku chemicznego. W ramach tej metody można dowolnie manipulować związkiem chemicznym i wszystkimi strukturami chemicznymi, z których się składa. Zauważ, że każdy zapisany związek będzie przetwarzany tą metodą.
Sole, solwaty i roztwory
MDF aktualna wersja 1.0.1 nie ma specjalnej obsługi dla soli, solwatów i roztworów. MDF będzie przechowywać oddzielne składniki w pliku struktury chemicznej jako oddzielną strukturę chemiczną. Dlatego zapisywanie soli jak 1 = CC = CC = C1. będzie reprezentowany jako mieszanina dwóch jonów bez żadnego ustawionego procentu. Dokładne wyszukiwanie struktury obu jonów zwróci tę sól. Jeśli sól ma ładunek większy niż 1 i wiele jonów z nim związanych, jak 1 = CC = C = C1.. sól będzie przechowywana jako mieszanina 1 = CC = C = C1 i bez żadnych ustawionych wartości procentowych. Jeśli struktura chemiczna jest jednym Jonem, będzie przechowywana i wyszukiwana jak każda inna struktura chemiczna. Jeśli takie zachowanie jest nieodpowiednie w konkretnym przypadku, programiści mogą zaimplementować funkcje obsługi salt i solvate w metodzie preSave ().
niektóre systemy komercyjne również wydają się nie mieć możliwości obsługi rozwiązań. Zaleca się utworzenie związku tak, jakby był czysty i dodanie informacji o roztworze jako oddzielnych pól na poziomie związku.
Przykładowa aplikacja webowa
powstała prosta aplikacja webowa wykorzystująca MDF. Aplikacja internetowa wykorzystuje Spring MVC. Aplikacja nie korzysta z integracji zabezpieczeń i nie wykorzystuje podmiotów Containable oraz ChemicalCompoundContainer. Używa tylko chemicalcompound entity. Aplikacja jest złożoną bazą danych dla związków wieloskładnikowych. Posiada stronę do importowania struktur chemicznych w pliku SD do bazy danych związków. Bazę danych można przeszukiwać według podstruktury i właściwości. Używa JSME do rysowania struktur chemicznych (ryc. 3). Strona wyników wyszukiwania wyświetla wyniki wyszukiwania w formie tabelarycznej i pagedowej. Po zakończeniu wyszukiwania podkonstrukcja zostanie wyróżniona w wynikach wyszukiwania (Rysunek 4). Trafienia wyszukiwania mogą być eksportowane jako plik SD. Wyniki wyszukiwania zawierają łącze do pojedynczego widoku złożonego. Właściwości związku można edytować, a kompozycje można dodawać, edytować i usuwać (Fig. 5, 6). Podczas edycji związku lub kompozycji aplikacja obsługuje współbieżne modyfikacje w przejrzysty sposób i wyświetlane jest okno dialogowe rozwiązywania konfliktów, w którym użytkownik może wybrać wartości do wykorzystania dla każdej właściwości, a następnie zapisać nową wersję.
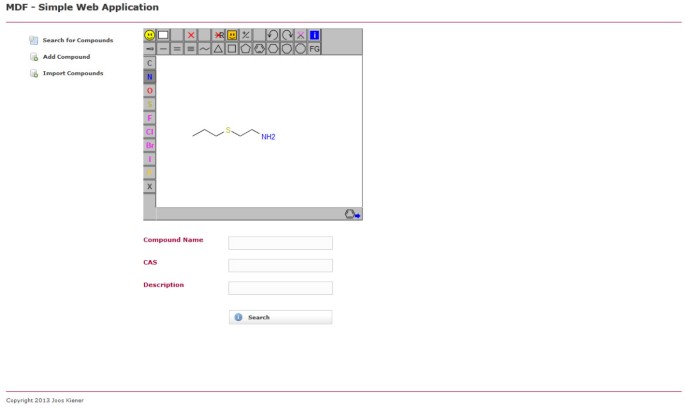
wyszukaj stronę przykładowej aplikacji webowej przy użyciu MDF. Użytkownik może przeszukiwać bazę danych związków według struktury chemicznej i / lub właściwości, takich jak nazwa związku lub numer CAS.

Strona wyników wyszukiwania podkonstrukcji. Wyniki są wyświetlane w tabeli paged Wygenerowanej Przez datatables wtyczki jQuery . Obrazy struktury chemicznej mają dopasowaną podbudowę podświetloną na Czerwono. Kliknięcie obrazu struktury chemicznej spowoduje wyświetlenie uśmiechów.
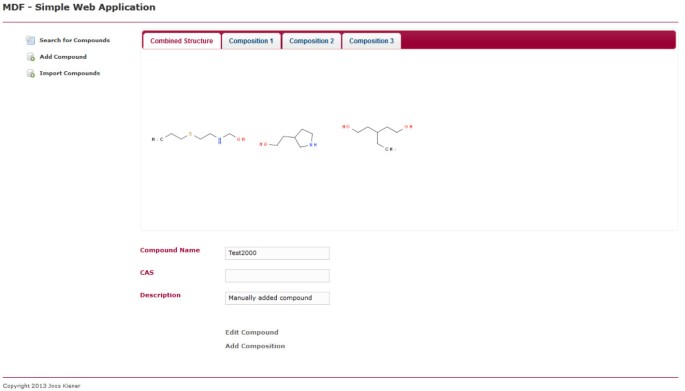
indywidualny widok złożony. Ta strona internetowa wyświetla pojedynczy związek. Związek można edytować lub usuwać, klikając odpowiedni link na stronie. Istnieje zakładka wyświetlająca wszystkie zawarte struktury chemiczne i zakładka dla każdego indywidualnego składu, z którego składa się Związek.
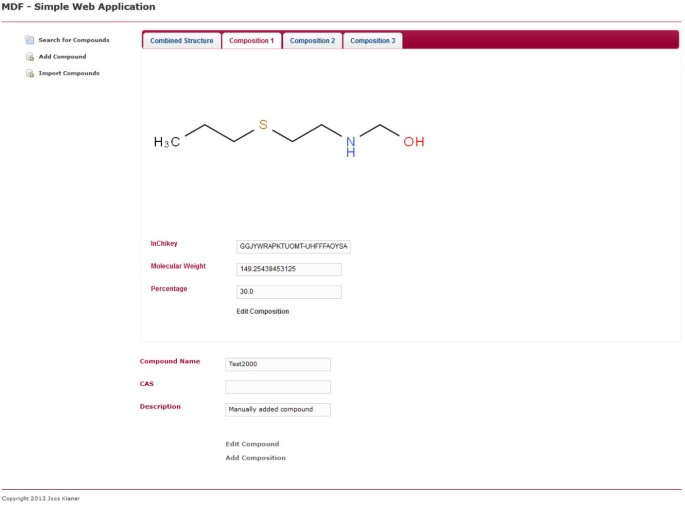
kompozycja pojedyncza. Pokazuje tę samą stronę, co rysunek 5, ale zamiast zakładki struktura połączona, zaznaczona jest zakładka pierwszej kompozycji. Kompozycję można edytować, klikając odpowiedni link na stronie.
wydajność
MDF ma jeden główny problem z wydajnością podczas obsługi mieszanek. Jeśli aplikacja używa mieszanin, tj. związków z wieloma składnikami, Zapytanie o strukturę chemiczną zwróci jeden wiersz dla każdego składnika w związku pasującym do zapytania. Jest to niepożądane, ponieważ użytkownicy końcowi chcą zobaczyć każdy związek, który pasuje do zapytania tylko raz. Rozwiązaniem problemu jest użycie odrębnego zapytania i tutaj występuje problem z wydajnością. Jeśli wykonasz odrębne zapytanie, cała baza danych musi zostać przeszukana niezależnie od klauzuli limit, co znacznie wydłuża czas wykonania. Zauważ, że sortowanie ma ten sam efekt. Więc sortowanie może mieć ogromne kary wydajności zbyt i podczas stronicowania należy zawsze sortować, aby uzyskać przewidywalny wynik. Co gorsza, kartridż Bingo dla PostgreSQL nie ma jeszcze odpowiedniej implementacji do kosztorysowania, a koszt użycia indeksu struktury chemicznej jest mocno zakodowany i zaniżony. Powoduje to, że planer zapytań PostgreSQL zawsze używa pełnego skanowania indeksu w indeksie wyszukiwania struktury, nawet jeśli zapytanie ma dodatkową klauzulę where, która znacznie ogranicza ilość wyników. W takich przypadkach szybsze byłoby na przykład użycie indeksu dla numeru CAS i użycie funkcji Bingo matchsub do filtrowania. Funkcja matchsub umożliwia dopasowanie podbudowy bez indeksu. Jest to oczywiście wolniejsze niż w przypadku indeksu, ale jeśli trzeba to zrobić tylko dla małej liczby struktur, jest to o wiele szybsze niż pełne skanowanie indeksu. Aby rozwiązać problem z szacowaniem kosztów, MDF wykonuje wewnętrzne obliczenia, aby wyraźnie zdecydować, czy używany jest indeks struktury, czy funkcja matchsub. Może to poprawić wydajność o rząd wielkości. Zauważ, że dostawca kasety Bingo jest świadomy tego problemu, a harmonogram poprawki był pod koniec 2013 roku. Główny problem odrębnych zapytań i sortowania jest jednak nieodłącznym elementem działania relacyjnych baz danych i nie może być rozwiązany z wyjątkiem lepszego indeksu wyszukiwania podbudowy lub lepszego sprzętu. MDF oferuje również ustawienie wyłączające odrębne zapytania dla całej aplikacji dla jednoskładnikowych złożonych baz danych.
do benchmarku MDF użyto wcześniej opisanej aplikacji internetowej. Baza zawiera 525573 unikalnych związków. Związki pochodzą z podgrupy cynku 13 przy pH odniesienia 7 Pliki SD 13_p0. 0.sdf, 13_p0. 1.sdf, 13_p0. 10.sdf i 13_p0. 11.sdf. Struktury są przechowywane w bazie danych jako SMILES. Importowanie każdego z plików SD, które zawierają około 131’000 struktur chemicznych, trwało 12 minut z wyłączonym indeksem wyszukiwania struktur chemicznych. Odbudowanie indeksu po zaimportowaniu wszystkich plików SD zajęło 22 min na laptopie z 4 GB RAM, procesorem Core i5-3220m i 512GB Samsung 830 SSD. To wynosi 1 h 10 min, aby skonfigurować w pełni indeksowaną bazę danych z pół milionem związków. Jako dodatkowe odniesienie ten sam import został wykonany na komputerze stacjonarnym z 12 GB PAMIĘCI RAM, i7-875k @ 3.4 GHz i bazie danych działającej na dysku Western Digital Green (5400 RPM). Tutaj import zajął 8 minut, a wniosek jest taki, że import jest ograniczony procesorem, a nie jest ograniczony szybkością przechowywania. Generowanie indeksu trwało około 22 min na laptopie i 20 min na komputerze stacjonarnym. Wniosek jest taki, że jest on bardziej ograniczony przez procesor, ale liczy się również prędkość napędu. Wydajność generowania importu i indeksu podczas przechowywania struktur jako molfiles nie była porównywana.
wydajność wyszukiwania podkonstrukcji została porównana z różnymi ustawieniami konfiguracji. Wyszukiwanie podkonstrukcji odbywa się za pomocą kartridża Bingo PostgreSQL, a zatem ten test odzwierciedla jego wydajność plus wszelkie koszty spowodowane przez MDF. Z wyjątkiem c1cccc1 autor narysował struktury chemiczne bez określonego znaczenia i przetestował szybkość wyszukiwania. Szybkość wyszukiwania została określona przez wdrożenie logbacks org.slf4j.profilerProfiler.
pierwszy benchmark to Referencja. W tym benchmarku użyto opcji wyłączenia wszystkich odrębnych zapytań i nie przeprowadzono sortowania. MDF wykonuje zliczanie całkowitych trafień przy pierwszym wystąpieniu wyszukiwania struktury chemicznej, a zliczanie jest buforowane, co powoduje, że pierwsza strona ładuje się wolniej niż kolejne strony. Każda strona zawiera 4 rekordów. Wyniki przedstawiono w tabeli 2 uporządkowanej rosnąco według liczby trafień.
benchmark został powtórzony, ale tym razem z włączonymi odrębnymi zapytaniami. Czas ładowania pierwszej strony jest podwojony, ponieważ zapytanie count jest uruchamiane, a następnie uruchamiane jest rzeczywiste zapytanie, które zajmuje mniej więcej tyle samo czasu, co zapytanie count ze względu na odrębną klauzulę. Z tego samego powodu załadowanie drugiej strony zawsze zajmuje połowę czasu w porównaniu z pierwszą stroną (Tabela 3). Liczba trafień jest identyczna jak w tabeli 2, ponieważ wszystkie związki w bazie danych składają się tylko z jednego składnika.
wyniki pokazują, że Bingo nie optymalizuje typowego zapytania podbudowy, takiego jak pierścień benzenowy, a tym samym szuka c1ccccc1 w bazie danych, w której prawie wszystkie cząsteczki mają tę funkcję jest bardzo powolny. Aby poprawić szybkość wyszukiwania w takim scenariuszu zaleca się filtrowanie według dodatkowych właściwości. W związku z tym benchmark został powtórzony z dodatkowym filtrem o nazwie złożonej zaczynającym się od „ZINC34”.
Tabela 4 pokazuje zalety optymalizacji MDF jako obejścia problemu kosztorysowania w kartridżu Bingo PostgreSQL. Bez tej optymalizacji wskaźnik miałby taką samą wydajność, jak pokazano w tabeli 3.
MDF wykorzystuje również funkcję wyszukiwania podobieństwa kartridży Bingo. Jego działanie zostało przetestowane przez wyszukiwanie związków o wyniku podobieństwa 0,9 za pomocą miary podobieństwa Tanimoto znanej również jako indeks Jaccard. Wyniki przedstawiono w tabeli 5.
Outlook
do generowania opisu struktury chemicznej używany jest zestaw narzędzi Indigo. Zestaw narzędzi można skonfigurować do generowania struktur na wiele sposobów, w tym kolorowanie heteroatomów, długość i szerokość wiązania i wiele innych. Obecnie jest to kodowanie twarde i nie może być dostosowane przez użytkownika. Następnym krokiem byłoby ujawnienie tych opcji konfiguracji, dzięki czemu można je ustawić za pomocą pliku właściwości Java. Należy również wdrożyć obsługę soli i solwatów, aby MDF mógł być używany na obszarach, w których takie związki są ważne.
aby korzystać z MDF musisz być w stanie programować w Javie i będziesz potrzebował podstawowej wiedzy na temat Spring framework i jak go skonfigurować. Ogranicza to grupę docelową. Podczas korzystania z MDF musisz napisać jakiś kod kotła-Płyta, a więc następnym krokiem byłoby stworzenie dodatkowych narzędzi, które ułatwią korzystanie z MDF, takich jak automatyczne generowanie klas encji oraz ich repozytoriów i usług. Narzędzia te muszą być konfigurowalne, aby użytkownik mógł zdefiniować żądane właściwości dla każdego z elementów i żądanych metod wyszukiwania. Opcją byłaby wtyczka maven. Wtyczki Mavena mogą generować kod podobny do tworzenia metamodela przez wtyczkę QueryDSL-maven. Inną opcją będą adnotacje generujące kod podczas kompilacji, tak jak robi to projekt Lombok .
ostatnim krokiem byłoby stworzenie platformy aplikacji internetowej, która pozwala administratorom tworzyć nowe aplikacje internetowe z funkcją wyszukiwania struktury chemicznej, po prostu wprowadzając żądane właściwości dla jednostek w formularzu internetowym i klikając przycisk. Oczywiste jest, że wymagałoby to znacznych wysiłków na rzecz rozwoju.