
we hebben een verscheidenheid aan configuraties, objectgroottes en tellingen voor client-Workers getest om de doorvoer van een Ceph-cluster van zeven knooppunten voor kleine en grote objecten te maximaliseren. Zoals beschreven in de eerste post het Ceph cluster werd gebouwd met behulp van een enkele OSD (Object Storage Device) geconfigureerd per HDD, met een totaal van 112 OSD ‘ s per Ceph cluster. In deze post, zullen we de top-line prestaties voor verschillende object maten en workloads begrijpen.
opmerking: De termen “lezen” en HTTP GET worden door elkaar gebruikt in dit bericht, net als de termen HTTP PUT en “write.”
werkbelasting voor grote objecten
werkbelasting voor grote objecten sequentiële input / output (I / O) is een van de meest voorkomende use cases voor Ceph-objectopslag. Deze high-throughput workloads omvatten big data analytics, back-up, en archiveringssystemen, beeldopslag, en streaming audio en video. Voor dit soort werklasten is de doorvoer (MB / s of GB / s) de belangrijkste maatstaf die de opslagprestaties definieert.
zoals getoond in grafiek 1 grote object 100% HTTP GET en HTTP PUT workload tentoongesteld sub-lineaire schaalbaarheid bij het verhogen van het aantal RGW hosts. Als zodanig hebben we gemeten ~ 5.5 GBps geaggregeerde bandbreedte voor HTTP GET en HTTP PUT workloads en interessant hebben we niet merkt bron verzadiging in Ceph cluster nodes.
dit cluster kan meer draaien als we er meer belasting naar kunnen sturen. Dus we identificeerden twee manieren om dat te doen. 1) meer clientknooppunten toevoegen 2) Meer RGW-knooppunten toevoegen. We konden niet gaan met optie 1 omdat we werden beperkt door de fysieke client nodes beschikbaar in dit lab. Dus kozen we voor Optie 2 en deden nog een ronde van tests, maar deze keer met 14 RGWs.
zoals weergegeven in grafiek 2, in vergelijking met de 7 RGW test, 14 RGW test leverde een 14% hogere schrijfprestatie, topping op ~6,3 GBps, vergelijkbaar, de HTTP GET workload toonde 16% hogere leesprestaties, topping ~6,5 GBps. Dit was de maximale geaggregeerde doorvoer waargenomen op dit cluster waarna media (HDD) verzadiging werd opgemerkt zoals afgebeeld in Figuur 1. Op basis van de resultaten zijn we van mening dat we meer Ceph OSD-knooppunten aan dit cluster hebben toegevoegd, de prestaties nog verder hadden kunnen worden geschaald, totdat ze werden beperkt door bronverzadiging.
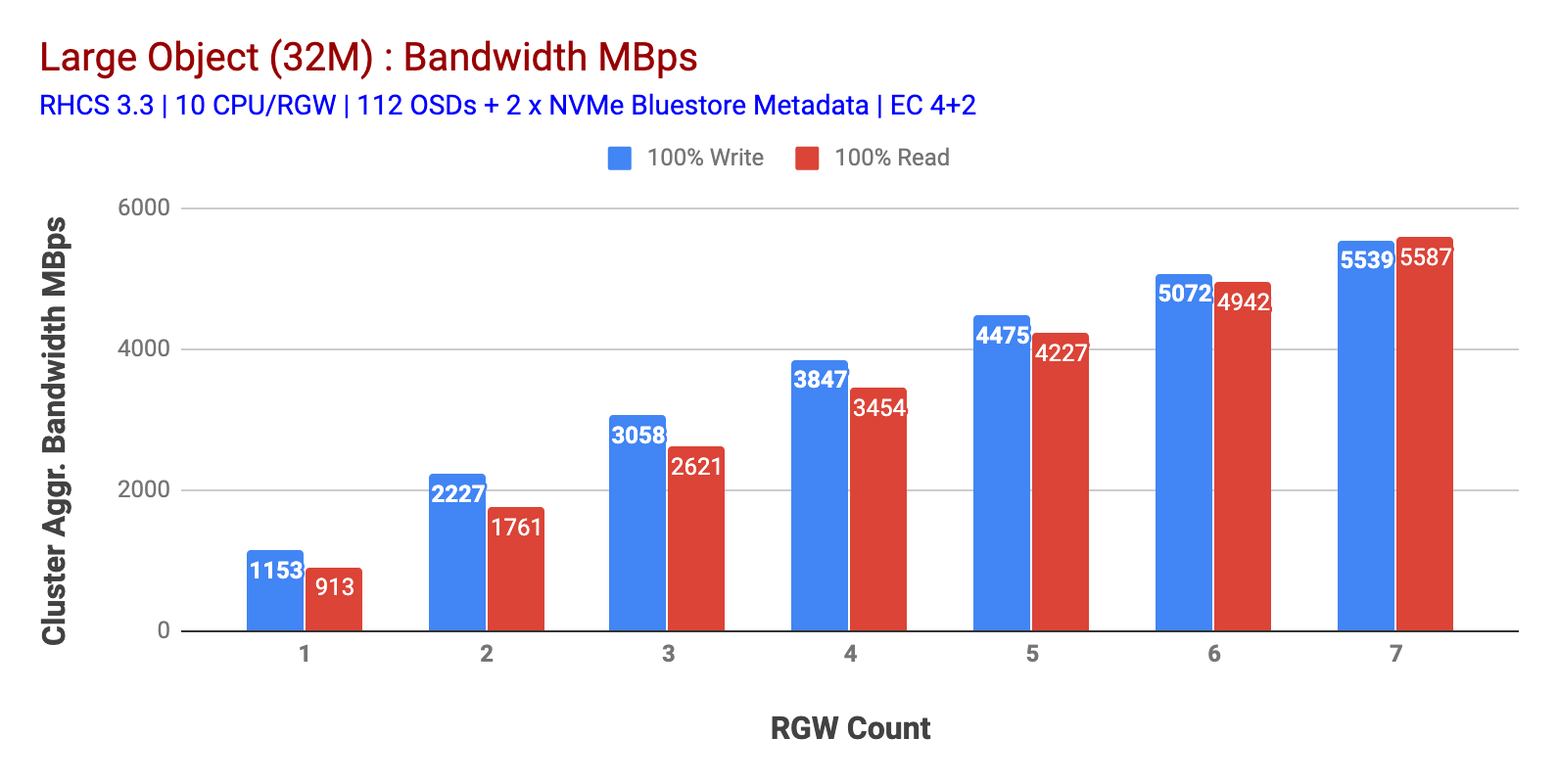
Grafiek 1: Large Object test
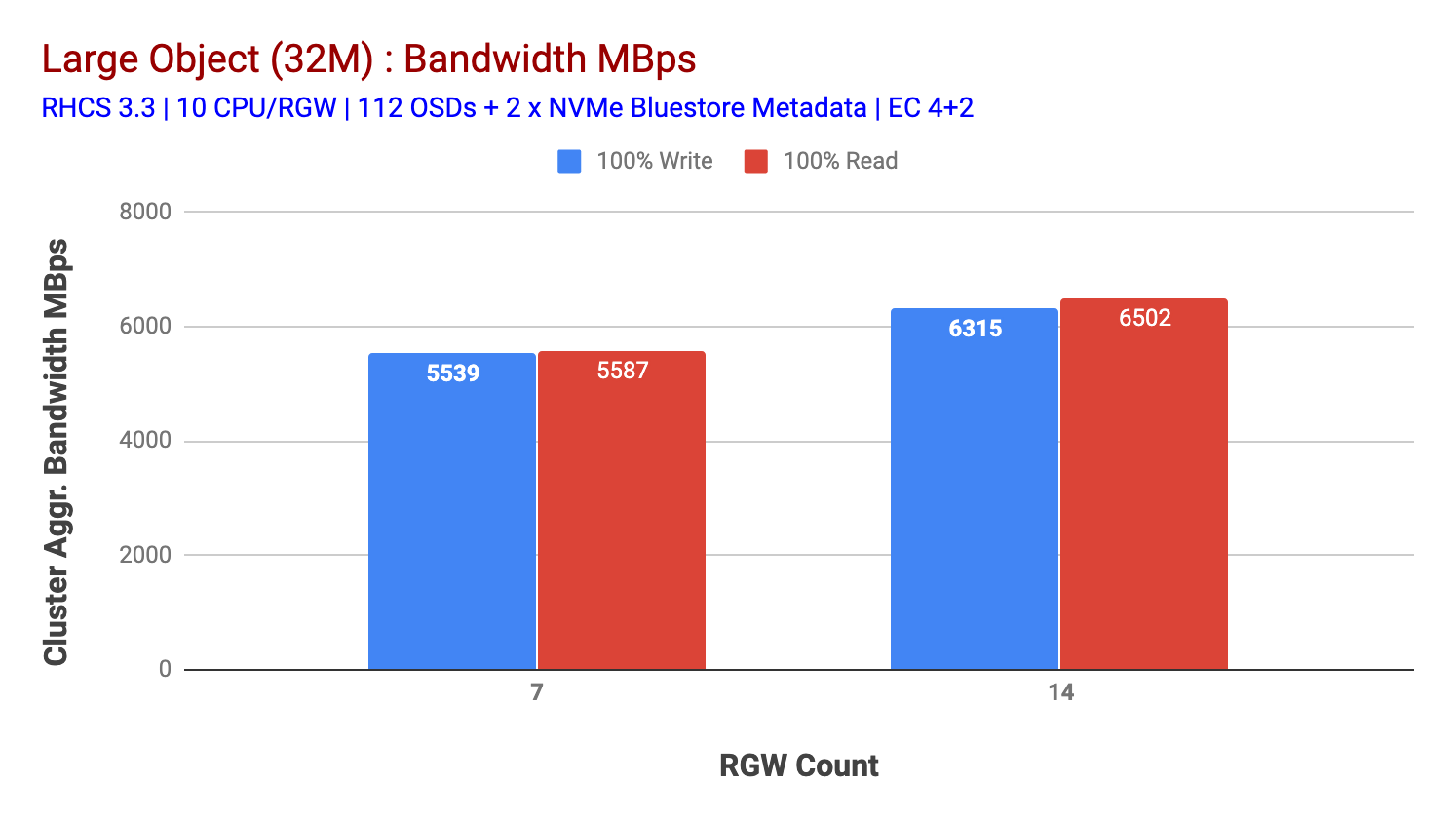
Grafiek 2: Large Object test met 14 RGWs
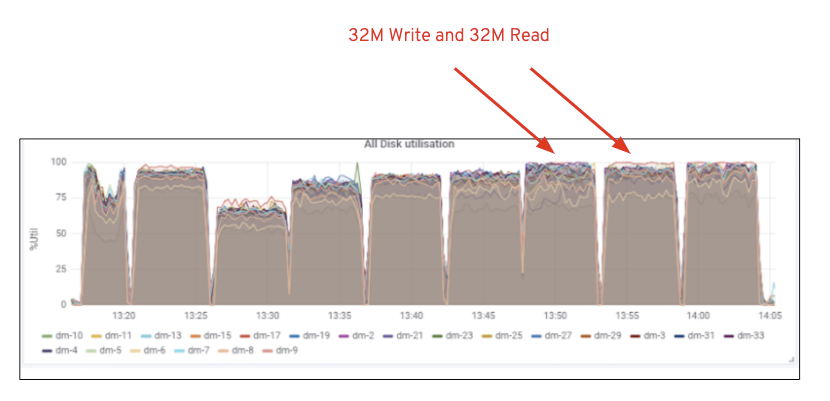
Figuur 1: Ceph OSD (HDD) mediagebruik
kleine Objectbelasting
zoals weergegeven in grafiek 3 kleine object 100% HTTP GET en HTTP PUT workloads vertonen sub-lineaire schaalbaarheid bij het verhogen van het aantal RGW hosts. Als zodanig hebben we gemeten ~ 6.2 K Ops doorvoer voor HTTP gezet op 9ms toepassing schrijf latency en ~ 3.2 K Ops voor HTTP GET workloads met 7 RGW instanties.
tot 7 RGW-instanties merkten we geen bronverzadiging op, dus we verdubbelden op RGW-instanties door deze te schalen naar 14 en waargenomen gedegradeerde prestaties voor HTTP PUT workload die wordt toegeschreven aan mediaverzadiging, terwijl HTTP prestaties worden opgeschaald en aangevuld Bij ~4.5 k Ops. Als zodanig, schrijven prestaties hoger had kunnen worden geschaald, hadden we meer Ceph OSD nodes toegevoegd. Wat de leesprestaties betreft, zijn we van mening dat het toevoegen van meer clientknooppunten het had moeten verbeteren, maar we hadden geen fysieke knooppunten meer in het lab om deze hypothese te testen.
een andere interessante observatie uit Grafiek 3 is de verminderde gemiddelde responstijd voor HTTP PUT workloads die gemeten werden op 9ms, terwijl HTTP GET 17ms gemiddelde latentie liet zien gemeten op basis van de applicatie die werkbelasting genereerde. Wij zijn van mening dat een van de redenen voor een enkele-cijferige applicatie latency voor write workload is de combinatie van prestatieverbetering afkomstig van de BlueStore OSD backend evenals de high performance Intel Optane NVMe gebruikt voor back BlueStore metadata apparaat. Het is vermeldenswaard dat het bereiken van een enkele cijfer schrijven gemiddelde latentie van een Object opslagsysteem is niet-triviaal. Zoals afgebeeld in grafiek 3, kan Ceph-objectopslag bij implementatie met BlueStore OSD-backend en Intel Optane voor Metadata de schrijfsnelheid bereiken bij een lagere responstijd.
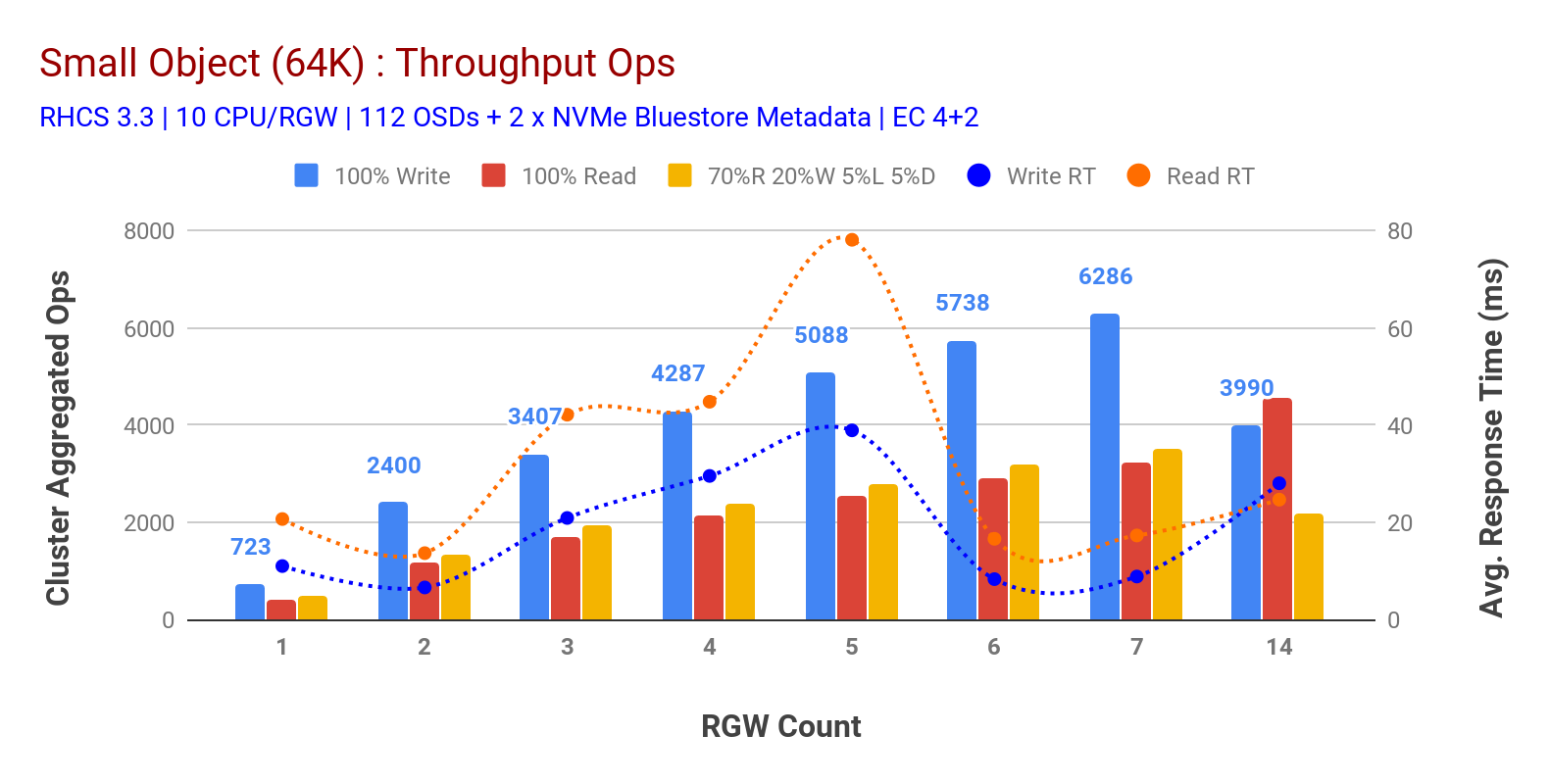
grafiek 3: Small Object Test
samenvatting en volgende
het cluster met vaste grootte dat bij deze test wordt gebruikt, heeft ~6,3 GBps en ~6,5 GBps grote objectbandbreedte opgeleverd voor respectievelijk schrijf-en leesworkloads. Dezelfde cluster voor kleine objectgrootte heeft ~6.5 K Ops en ~4.5 k Ops voor schrijven en lezen werklast, respectievelijk geleverd.
de resultaten hebben ook aangetoond dat BlueStore OSD in combinatie met Intel Optane NVMe gemiddelde latency voor toepassingen heeft opgeleverd, wat niet-triviaal is voor objectopslagsystemen. In de volgende post zullen we de prestaties van bucket dynamic sharding onderzoeken en hoe de pre-sharding bucket kan helpen bij deterministische prestaties.