
Vi har testet en rekke konfigurasjoner, objektstørrelser og antall klientarbeidere for å maksimere gjennomstrømningen av en ceph-klynge med syv noder for små og store objektarbeidsbelastninger. Som beskrevet i det første innlegget Ble Ceph-klyngen bygget ved hjelp AV en ENKELT OSD (Object Storage Device) konfigurert per HDD, med totalt 112 Osder per Ceph-klynge. I dette innlegget vil vi forstå topplinjens ytelse for forskjellige objektstørrelser og arbeidsbelastninger.
Merk: Begrepene «lese» OG HTTP GET brukes om hverandre i hele dette innlegget, som er begrepene HTTP PUT og » skrive.»
Arbeidsbelastning med store Objekter
arbeidsbelastninger med sekvensielle inndata/utdata (I/O) Med store objekter er et av de vanligste bruksområdene for Ceph-objektlagring. Disse høy gjennomstrømmingsarbeidsbelastningene inkluderer big data analytics, backup og arkivsystemer, bildelagring og streaming av lyd og video. For disse typer arbeidsbelastninger er gjennomstrømming (MB/s eller GB / s) den viktigste beregningen som definerer lagringsytelse.
som vist I Diagram 1 Stort objekt 100% HTTP GET OG HTTP PUT arbeidsbelastning utstilt sub-lineær skalerbarhet når øke antall rgw verter. Som sådan målte vi ~5.5 GBps aggregert båndbredde FOR HTTP GET OG HTTP PUT arbeidsbelastninger og interessant la vi ikke merke til ressursmetning i Ceph cluster noder.
denne klyngen kan churn ut mer hvis vi kan lede mer last til den. Så vi identifiserte to måter å gjøre det på. 1) Legg til flere klientnoder 2) Legg til flere rgw noder. Vi kunne ikke gå med alternativ 1 da vi var begrenset av de fysiske klientnodene som er tilgjengelige i dette laboratoriet. Så vi valgte alternativ 2 og kjørte en annen testrunde, men denne gangen med 14 RGWs.Som vist i Figur 2, sammenlignet med 7 RGW-testen, ga 14 RGW-testen en 14% høyere skriveytelse, topping på ~6.3 GBps, PÅ SAMME måte VISTE HTTP GET-arbeidsbelastningen 16% høyere leseytelse, topping ~6.5 GBps. Dette var den maksimale aggregerte gjennomstrømmingen som ble observert på denne klyngen, hvoretter media (HDD) – metning ble lagt merke til som vist i Figur 1. Basert på resultatene tror vi at vi har lagt til Flere Ceph OSD-noder til denne klyngen, ytelsen kunne ha blitt skalert enda lenger, til begrenset av ressursmetning.
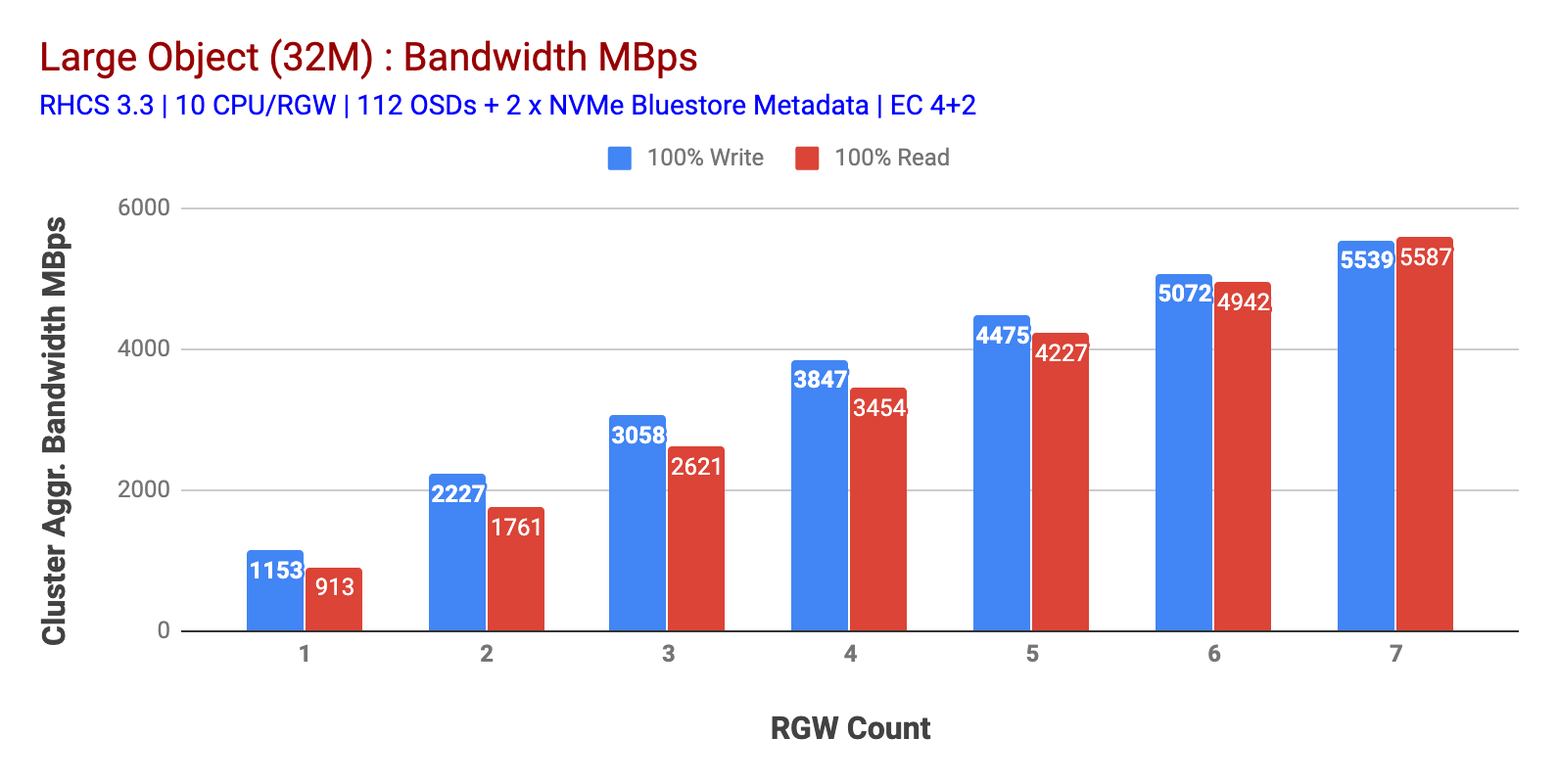
Tabell 1: stort Objekt test
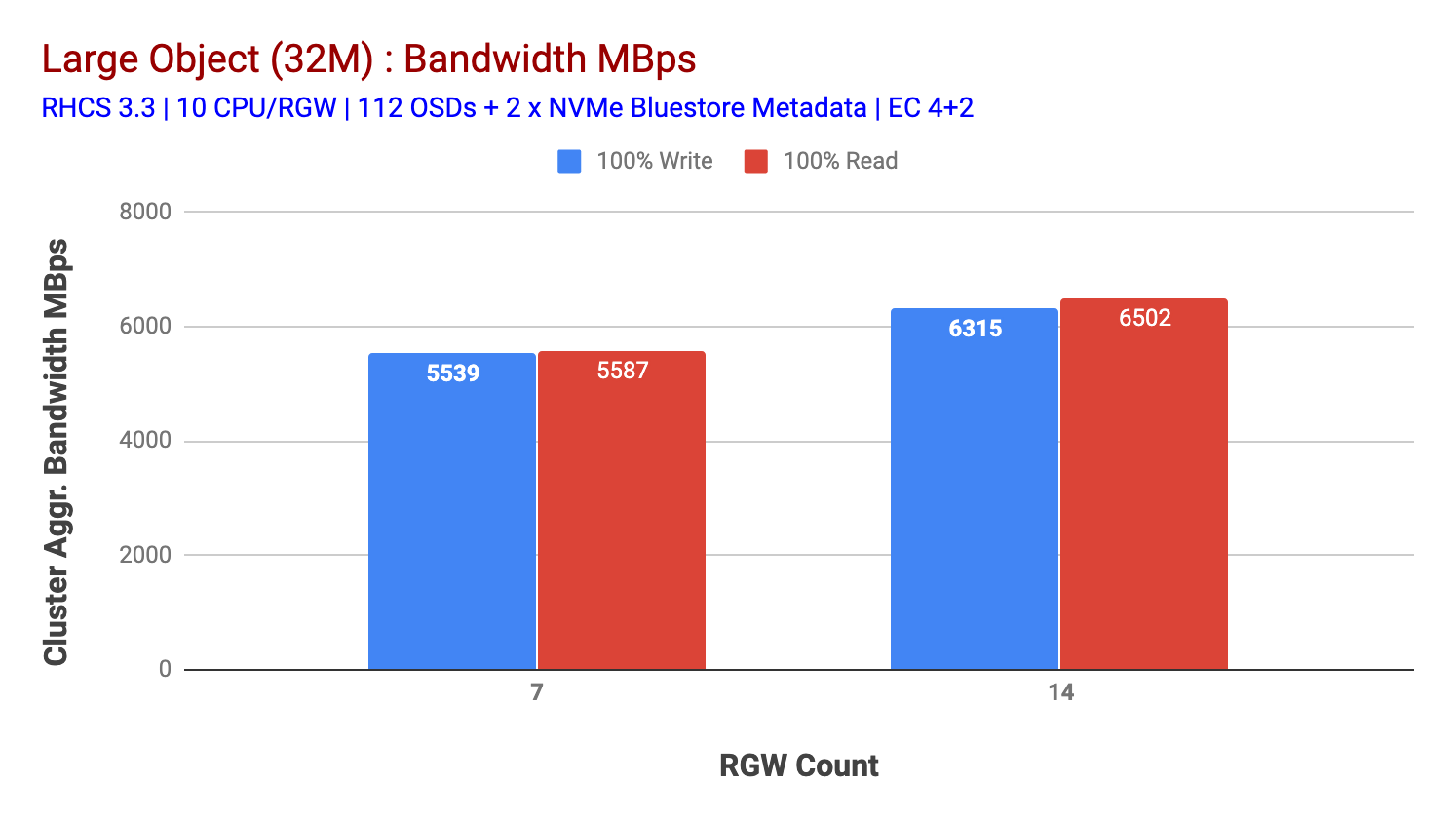
Figur 2: Stort Objekt test med 14 RGWs
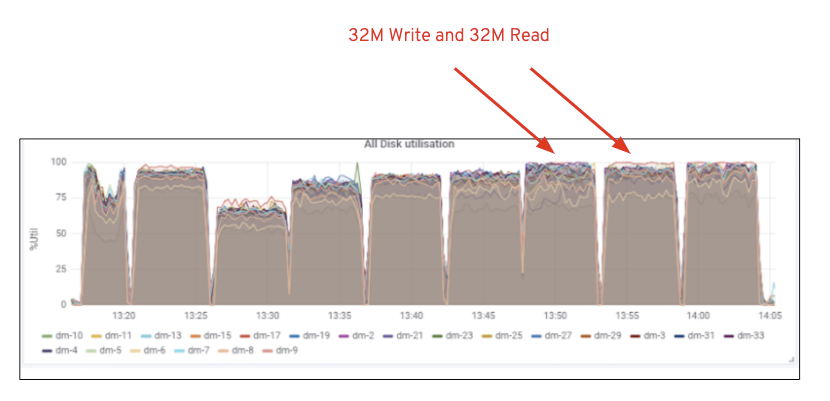
figur 1: Ceph OSD (HDD) medieutnyttelse
arbeidsbelastning for Små Objekter
som vist i Tabell 3 små objekter 100% HTTP GET OG HTTP PUT arbeidsbelastninger utstilt sub-lineær skalerbarhet når du øker antall rgw-verter. Som sådan målte vi ~6.2 K Ops gjennomstrømning FOR HTTP PUT på 9ms søknad skriv latens og ~3.2 K Ops FOR HTTP FÅ arbeidsbelastninger med 7 RGW-forekomster.
Til 7 RGW-forekomster merket vi ikke ressursmetning, så vi doblet ned PÅ RGW-forekomster ved å skalere dem til 14 og observert forringet ytelse FOR HTTP PUT-arbeidsbelastning som tilskrives mediemetning, MENS HTTP FÅR ytelse skalert opp og toppet ut på ~4.5 K Ops. Som sådan kunne skriveytelsen ha skalert høyere, hadde vi lagt til flere Ceph OSD-noder. Når det gjelder leseytelse, tror vi at å legge til flere klientnoder burde ha forbedret det, men vi hadde ikke flere fysiske noder i laboratoriet for å teste denne hypotesen.En annen interessant observasjon fra Diagram 3 er den reduserte gjennomsnittlige responstiden FOR HTTP PUT-arbeidsbelastninger som gauged på 9ms mens HTTP GET viste 17ms gjennomsnittlig ventetid målt fra applikasjonen som genererer arbeidsbelastning. Vi tror at en av årsakene til enkeltsifret applikasjonsforsinkelse for skrivearbeidsbelastning er kombinasjonen av ytelsesforbedring som kommer fra BlueStore OSD-backend, samt Den høye ytelsen Intel Optane NVMe som brukes Til Å sikkerhetskopiere BlueStore metadata-enheten. Det er verdt å merke seg at å oppnå ensifret skriv gjennomsnittlig ventetid fra Et Objektlagringssystem er ikke-trivielt. Som vist I Diagram 3, Kan Ceph-objektlagring når den distribueres Med BlueStore OSD-backend og Intel Optane for metadata oppnå skrivegjennomstrømning ved lavere responstid.
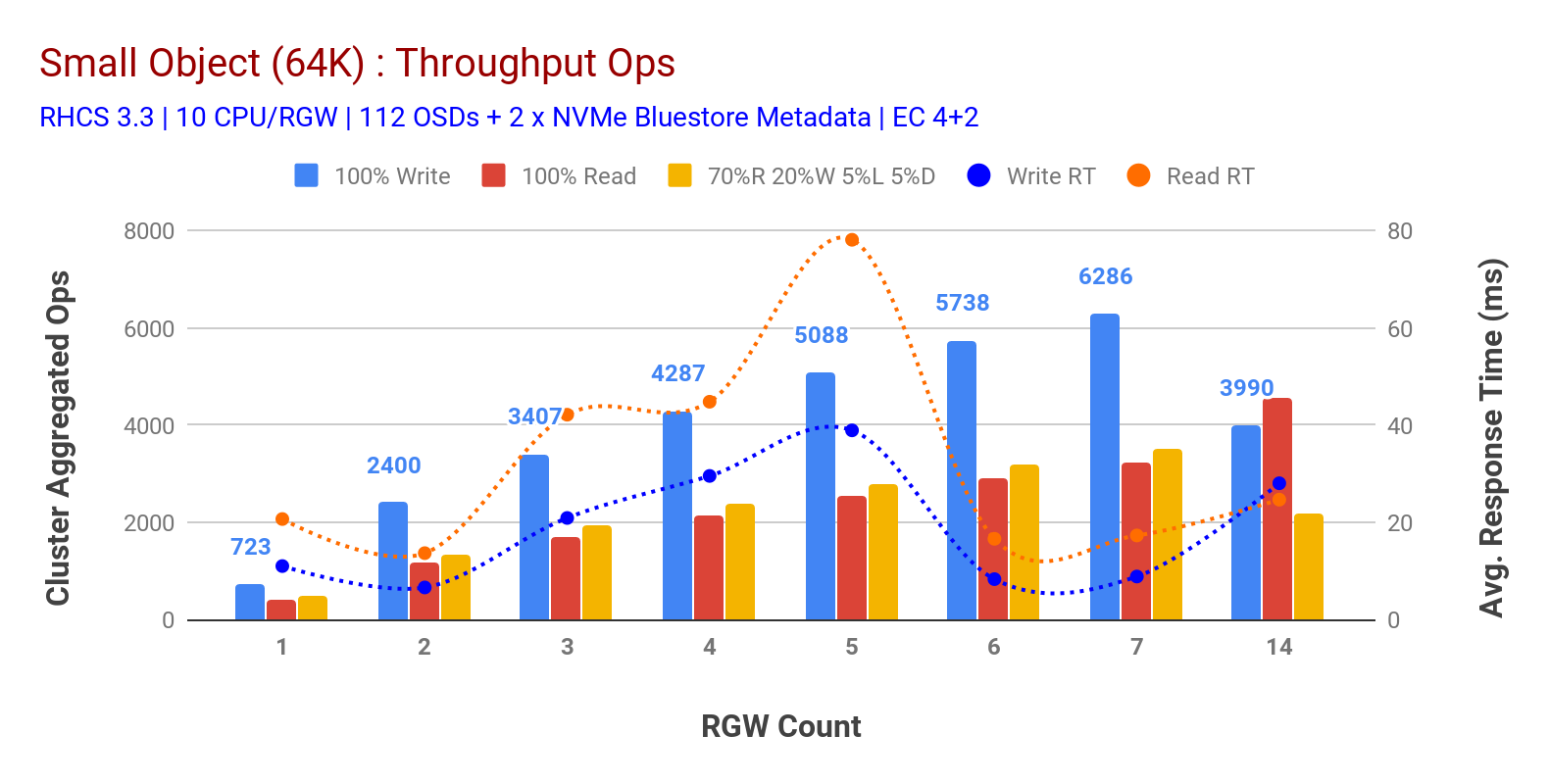
Tabell 3: liten Objekttest
Sammendrag og opp neste
klyngen med fast størrelse som brukes i denne testingen, har levert ~6,3 GBps og ~6,5 GBps stor objektbåndbredde for henholdsvis skrive-og lesearbeidsbelastninger. Den samme klyngen for liten objektstørrelse har levert henholdsvis ~6.5 K Ops og ~4.5 K Ops for skrive og lese arbeidsbelastning. Resultatene har også vist At BlueStore OSD i kombinasjon med Intel Optane NVMe har levert enkeltsifret gjennomsnittlig applikasjonslatens, noe som ikke er trivielt for objektlagringssystemer. I neste innlegg vil vi utforske ytelsen knyttet til bucket dynamic sharding og hvordan pre-sharding bucket kan bidra til deterministisk ytelse.