
から最大のパフォーマンスを達成する小規模および大規模なオブジェクトのワークロードに対して、セブンノードCephクラスターのスループットを最大化するために、さまざまな構成、オブジェクトサイズ、およびクライアントワーカー数をテストしました。 最初の投稿で詳述したように、Cephクラスターは、HDDごとに構成された単一のOSD(Object Storage Device)を使用して構築され、Cephクラスターごとに合計112のOsdを持ちます。 この記事では、さまざまなオブジェクトサイズとワークロードの最上位のパフォーマンスを理解します。ノート
: “Read”とHTTP GETという用語は、HTTP PUTと”write”という用語と同じように、この投稿全体で同じ意味で使用されています。”
ラージオブジェクトワークロード
ラージオブジェクトシーケンシャル入出力(I/O)ワークロードは、Cephオブジェクトストレージの最も一般的なユースケース これらのハイスループットワークロードには、ビッグデータ分析、バックアップ、アーカイブシステム、イメージストレージ、ストリーミングオーディオ、ビデオが含まれます。 これらのタイプのワークロードでは、スループット(MB/sまたはGB/s)がストレージパフォーマンスを定義する重要なメトリ
図1に示すように、ラージオブジェクト100%HTTP GETおよびHTTP PUTワークロードは、RGWホストの数を増やすと、サブリニアスケーラビリティを示しました。 そのため、HTTP GETとHTTP PUTのワークロードでは〜5.5GBpsの集約帯域幅を測定しましたが、興味深いことに、Cephクラスターノードではリソースの飽和に気付きませんでした。
このクラスターは、より多くの負荷を向けることができれば、より多くの負荷を発生させる可能性があります。 そこで私たちはそれを行う2つの方法を特定しました。 1)より多くのクライアントノードを追加2)より多くのRGWノードを追加します。 このラボで利用可能な物理クライアントノードによって制限されていたため、オプション1を使用することはできませんでした。 そこで、オプション2を選択し、別のテストラウンドを実行しましたが、今回は14RGWsで実行しました。
チャート2に示すように、7RGWテストと比較して、14RGWテストは-6.3GBpsでトッピング、14%高い書き込み性能をもたらし、同様に、HTTP GETワークロードは-6.5GBpsをトッピング、16%高い読み取り性能を示した。 これは、図1に示すように、メディア(HDD)の飽和が検出された後、このクラスタで観測された最大集約スループットでした。 結果に基づいて、このクラスターにCeph OSDノードを追加すると、リソースの飽和によって制限されるまで、パフォーマンスはさらに拡大される可能性があると考P>
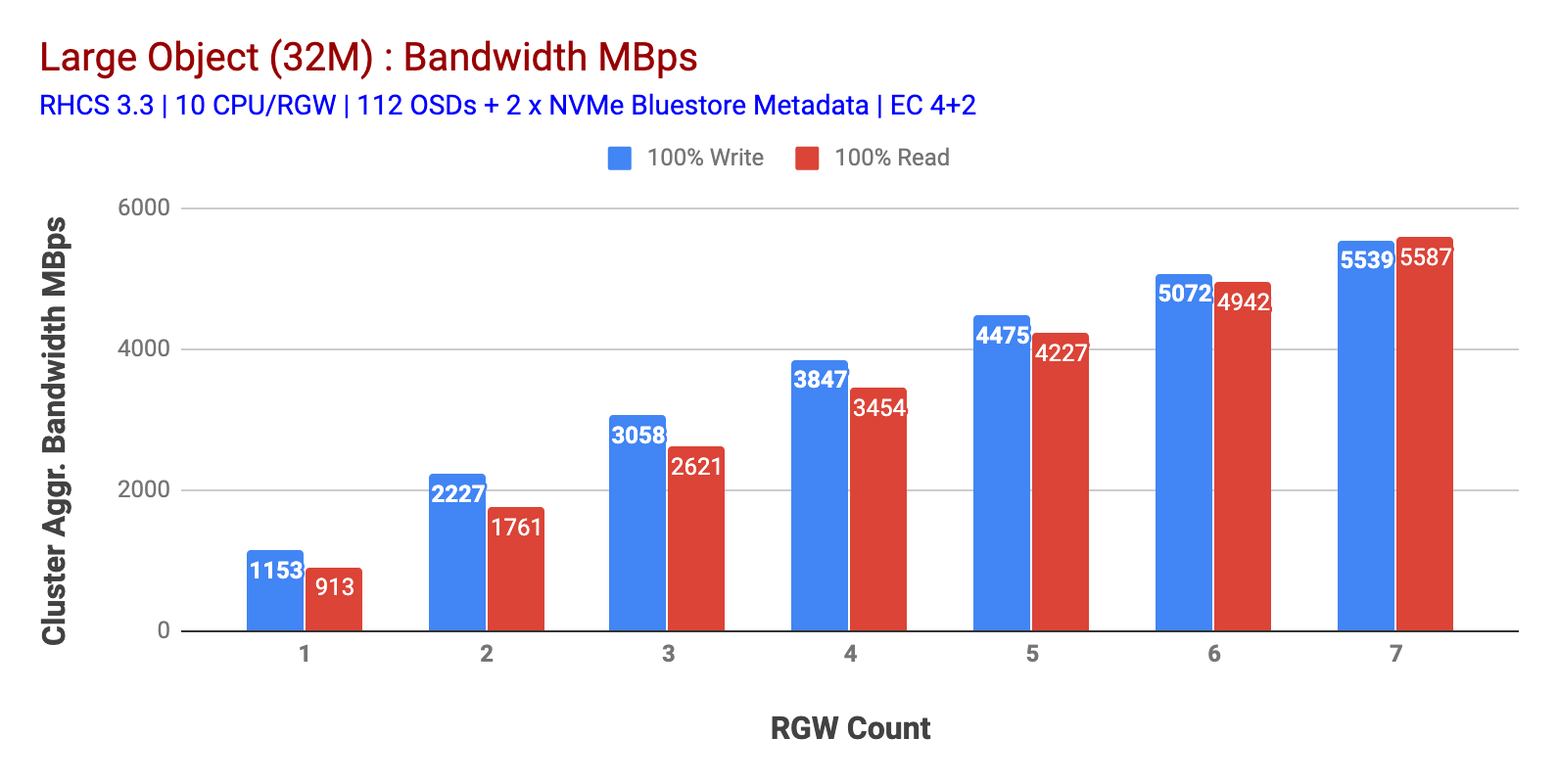
チャート1:ラージオブジェクトテスト
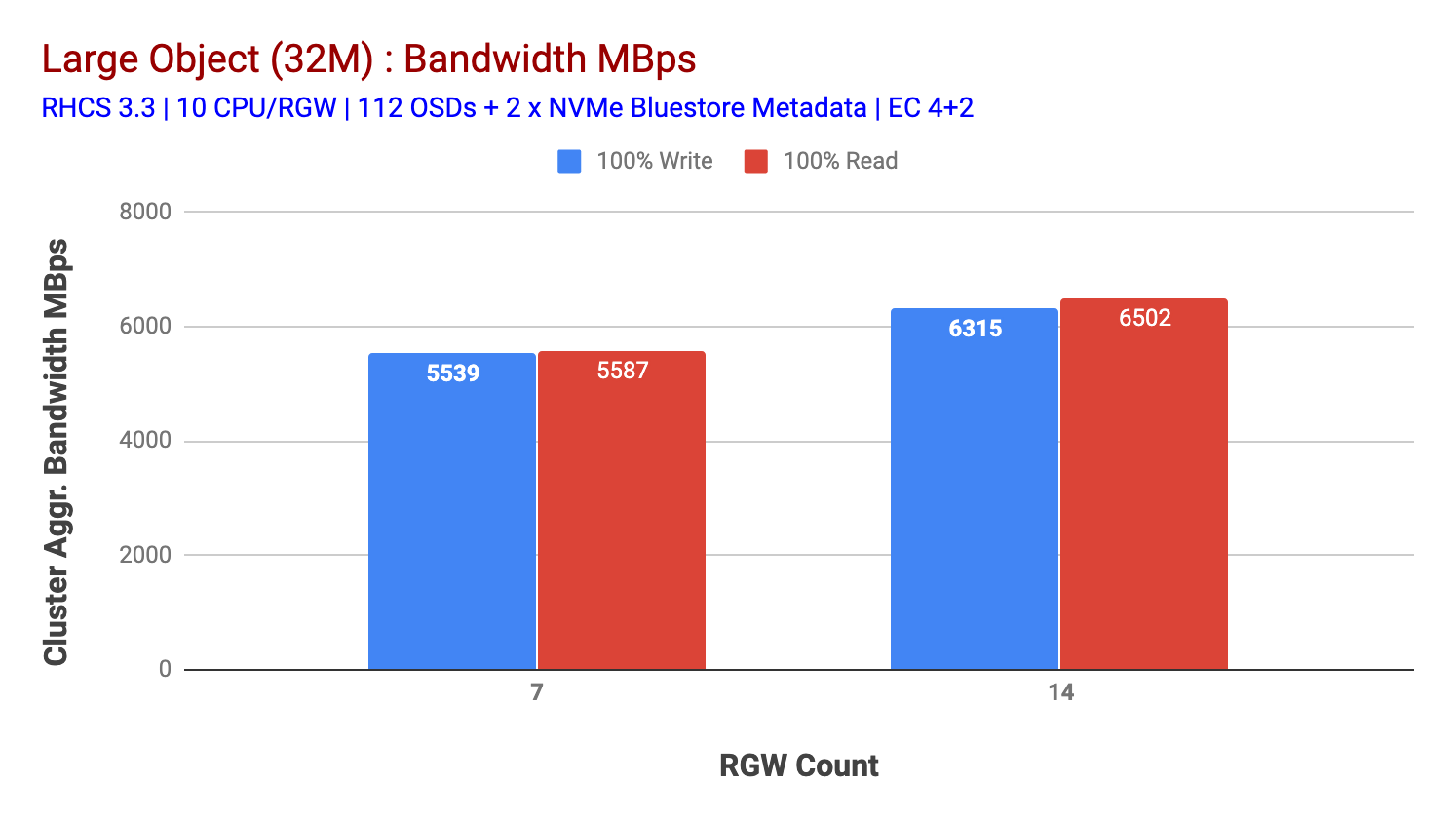
図1:Ceph osd(hdd)メディアの使用率
: Ceph OSD(HDD)メディア使用率
Small Object workload
図表3に示すように、small object100%HTTP GETおよびHTTP PUTワークロードは、RGWホストの数を増やすと、サブリニアスケーラビリティ そのため、9msのアプリケーション書き込みレイテンシでのHTTP PUTの約6.2K Opsスループットと、7RGWインスタンスを持つHTTP GETワークロードの約3.2K Opsを測定しました。
7つのRGWインスタンスまでは、リソースの飽和に気付かなかったため、RGWインスタンスを14にスケーリングすることでrgwインスタンスを倍増させ、HTTP GETパフォー そのため、Ceph osdノードを追加すると、書き込みパフォーマンスがより高くなる可能性があります。 読み取りパフォーマンスに関しては、クライアントノードを追加することで改善されたはずですが、この仮説をテストするための物理ノードはラボにはありませんでした。
チャート3からのもう一つの興味深い観察は、HTTP GETがアプリケーション生成ワークロードから測定された平均レイテンシの17msを示した間、9msで測定されたHTTP PUTワークロードの平均応答時間の減少です。 私たちは、書き込みワークロードのための一桁のアプリケーション遅延の理由の一つは、BlueStore OSDバックエンドからのパフォーマンスの向上と、BlueStoreメタデータデバイ オブジェクトストレージシステムから一桁の書き込み平均レイテンシを達成することは自明ではないことは注目に値します。 図3に示すように、BlueStore OSDバックエンドとIntel Optane for metadataを使用してceph object storageをデプロイすると、より低い応答時間で書き込みスループットを達成できます。
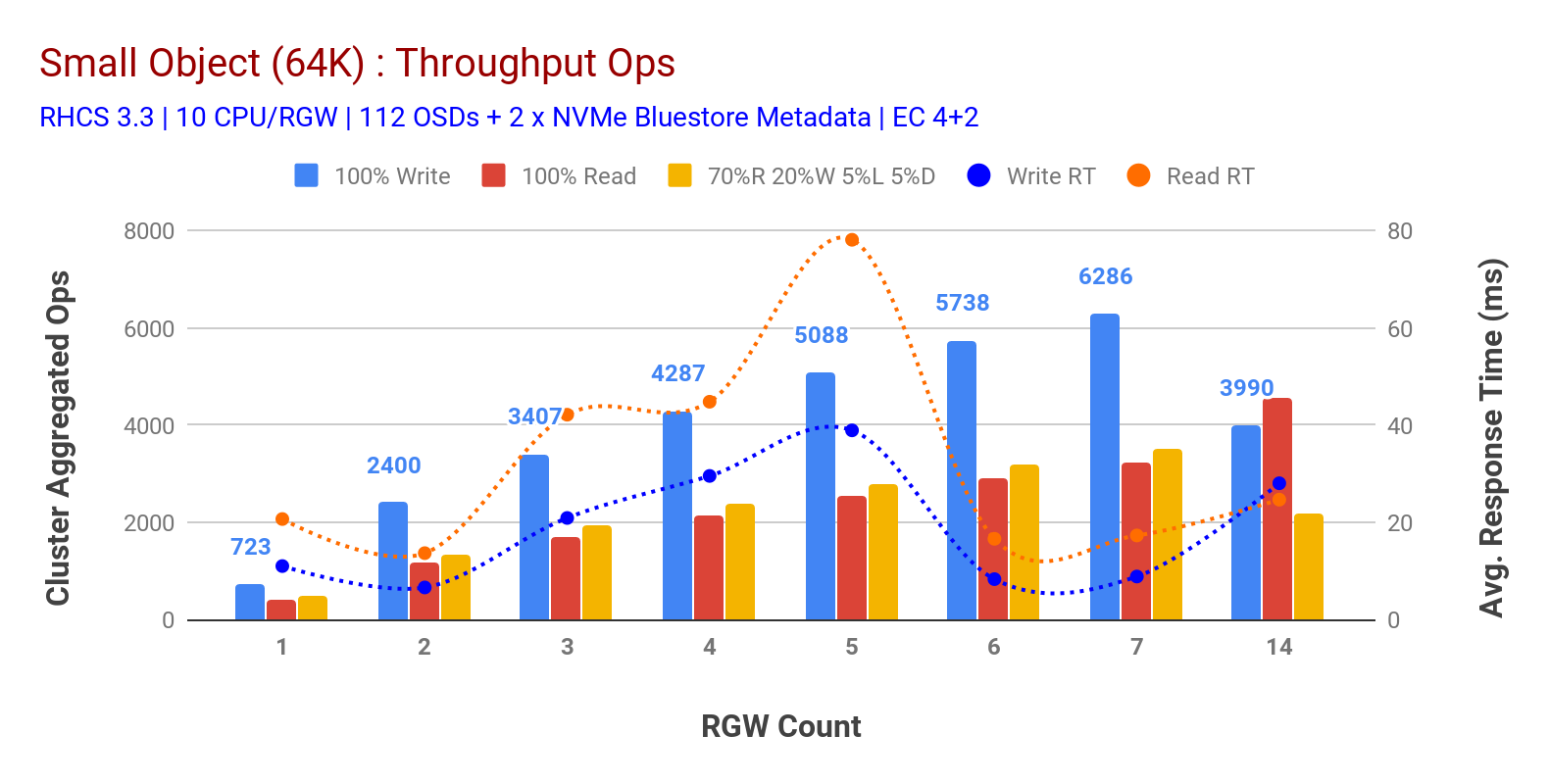
チャート3:スモールオブジェクトテスト
概要と次へ
このテストで使用されている固定サイズのクラスターは、書き込みワークロードと読み取りワークロードに対してそれぞれ最大6.3GBpsと最大6.5GBpsの大きなオブジェクト帯域幅を提供しています。 小さいオブジェクトサイズの同じクラスターは、それぞれ書き込みおよび読み取りワークロード用に約6.5K Opsおよび約4.5K Opsを提供しています。 また、BlueStore OSDとIntel Optane NVMeを組み合わせた結果、1桁の平均アプリケーション遅延が実現したことも示されています。 次の記事では、バケットの動的シャーディングに関連するパフォーマンスと、事前シャーディングバケットが決定的なパフォーマンスにどのように役立