
機能
以下はMDFのコア機能のリストです。
-
化学構造検索機能を備えたデータベースアプリケーションを作成するためのフレームワークです。
-
化学構造検索機能を備えたデータベースアプリケーションを作成するためのフレームワークです。
-
化学構造検索機能を備えたデータベースアプリケーションを作成するためのフレームワーク: フル、サブ、知性、類似性、式
-
化学構造検索は、プロパティ検索と組み合わせることができます
-
化学構造検索はページ化され、キャッシュされています
-
多成分化合物(混合物)のサポート
-
3化学構造検索可能なエンティティ: CHEMICALCOMPOUND,Containable and ChemicalCompoundContainer
-
上記の3つのエンティティのSDファイルのインポートとエクスポート
-
トランザクションデータベースアクセス
-
オプションのセキュリティ(承認)
MDFの設計と機能により、登録システム、インベントリシステム、または単純な複合データベースなど、多くの異なるタイプのシステムを構築することが可能です。 独自のELNを作成することもできますが、無料のIndigo ELNも存在します。 このELNはGGA Software Servicesによって作成され、ファイザーで使用されています。
Moldb5RやMyMolDBとは対照的に、MDFは化学構造検索を備えた完全に機能するスタンドアロンwebアプリケーションではありません。 名前が示すように、それはそのようなアプリケーションの作成を簡素化するためのフレームワークです。 MDFは、ローカルまたはクライアントサーバーのデスクトップアプリケーションを作成するためにも使用できます。 MDFはソフトウェア開発者を対象としており、科学者自身が使用することを意図していません。 しかし、MDFの機能は非常に堅牢です。 化学構造検索は、アプリケーションコードではなくデータベースで行われます。 したがって、化学構造やその他のプロパティで同時に検索することができ、結果を複数のプロパティでソートしてページ設定することができます(SQL OFFSETとLIMIT句)。 アプリケーションコードで化学構造検索を行う場合、どのクエリでもデータベースへの少なくとも二つのトリップ、すなわち構造検索とその後の他のプロパテ 両方とも同じトランザクションで発生する必要があります。 Moldb5RとMyMolDBが実際に同じトランザクションでこれを行うかどうかは決定されませんでした。
MDFでは、化合物はcontainableに関連付けることができ、登録システムではバッチまたは在庫システムで多くのものになります。 バーコード化されたびんの特定の物理的に利用できるサンプルは容器とそれから関連付けることができる。 これらの容器はまた化学構造によって捜すことができる。 これは、在庫システムを作成するための基盤です。 開発者は、エンティティのそれぞれに必要なだけ多くの追加プロパティを追加することができ、それらのすべてが化学構造と一緒に検索可能です。
MDFのすべてのデータアクセスは、データの不整合を防ぐためにトランザクション的です。 MDFは、データベース接続プールを使用するように構成できます。 RDBMSを照会する場合、接続の作成にはクエリ自体よりも時間がかかることが多いため、既に開いている接続がある場合は応答時間を短縮できます。
類似性探索のために、部分構造に対する谷本、トヴェルスキー、ユークリッド計量であるBingoカートリッジによって提供されるアルゴリズムが公開された。MDFはSpring securityで使用する準備ができています。 セキュリティはオプションです。 MDFは、メソッドレベルのセキュリティ(承認)を提供します。 認証機能は提供していません。
混合物処理
MDFは、多成分化合物をサポートしています。 サブ構造で検索すると、クエリ構造に一致する少なくとも一つの成分(化学構造)を持つすべての化合物が返されます。 化学登録システムに入力される可能性のある反応生成物は、大規模な精製が行われない限り、ほとんど常に混合物であるため、これは重要です。
インポートされたSDファイル内のエントリが複数の切断された構造で構成されている場合、このエントリは混合物であり、各構造は別々の化学構造とし
構造の正規化
デフォルトでは、MDFは送信された化学構造を保存します。 MDFは化学構造の標準化/正規化を行いません。 化学構造をデータベースに保存する前に、化学構造が正しく正規化されていることを確認するのは、MDFを使用する開発者次第です。 現在、開発者は、chemicalcompoundserviceimplのpreSave()メソッドをオーバーライドすることによって、このような機能を実装することが提案されています。 このメソッドは、化学化合物が作成または更新される前に呼び出されます。 この方法の中では化学化合物およびから成っているすべての化学構造は望まれるように自由に処理することができる。 保存されるすべての化合物は、この方法で処理されることに注意してください。
塩、溶媒和物および溶液
MDFの現在のバージョン1.0.1は、塩、溶媒和物または溶液のための特別な取り扱いを持っていません。 MDFは、別々の化学構造として化学構造ファイルに別々のコンポーネントを格納します。 したがって、1=CC=CC=C1のような塩を保存します。 任意のパーセンテージを設定せずに二つのイオンの混合物として表されます。 いずれかのイオンの正確な構造検索は、この塩を返すでしょう。 塩が1より大きい電荷を持ち、1=CC=C=C1のように複数のイオンがそれに関連付けられている場合。. 塩は、1=CC=C=C1の混合物として保存され、パーセンテージは設定されません。 化学構造が単一のイオンである場合、それは他の化学構造と同様に保存され、検索可能になります。 この動作が特定のケースでは不適切である場合、開発者はpreSave()メソッドに塩と溶媒和物の処理機能を実装することができます。
一部の商用システムには、ソリューションを処理する方法がないように見えます。 化合物が純粋であるかのように化合物を作成し、化合物レベルで溶液情報を別々のフィールドとして追加することをお勧めします。
Webアプリケーションの例
MDFを使用した単純なwebアプリケーションが作成されました。 WebアプリケーションはSpring MVCを利用しています。 アプリケーションはセキュリティ統合を使用せず、ContainableおよびChemicalCompoundContainerエンティティを使用しません。 それはChemicalCompoundの実体だけを使用します。 アプリケーションは、多成分化合物のための化合物データベースです。 これは、化合物データベースにSDファイル内の化学構造をインポートするためのページを持っています。 データベースは、サブ構造とプロパティで検索できます。 これは、化学構造を描画するためにJSMEを使用しています(図3)。 検索結果ページには、検索ヒットが表形式およびページ形式で表示されます。 下部構造の検索が行われると、その下部構造が検索結果で強調表示されます(図4)。 検索のヒットは、SDファイルとしてエクスポートすることができます。 検索結果には、単一の複合ビューへのリンクが含まれています。 化合物の特性を編集することができ、組成物を追加、編集、および削除することができる(図5、6)。 コンポジションまたはコンポジションを編集すると、アプリケーションは同時に変更を透過的に処理し、競合解決ダイアログが表示され、ユーザーは各プロ
図3 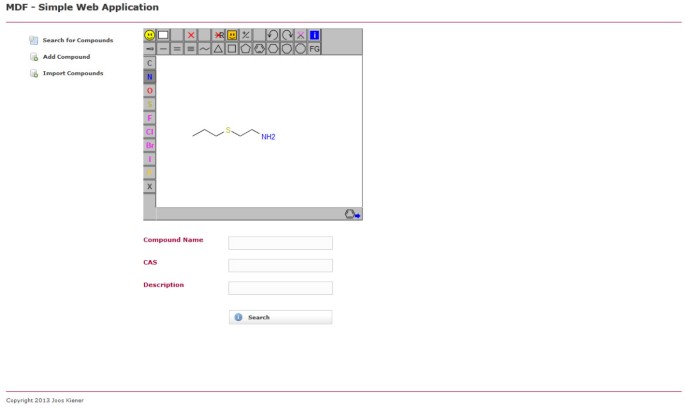
MDFを使用した例のwebアプリケーションの検索ページ。 ユーザーは、化合物名またはCAS番号のような化学的な基礎構造および/または特性によって化合物データベースを検索することができます。
図4 
サブ構造検索の結果ページ。 結果は、JQueryプラグインdatatablesによって生成されたページテーブルに表示されます。 化学構造画像には、一致する下部構造が赤で強調表示されています。 化学構造の画像をクリックすると、その笑顔が表示されます。
図5 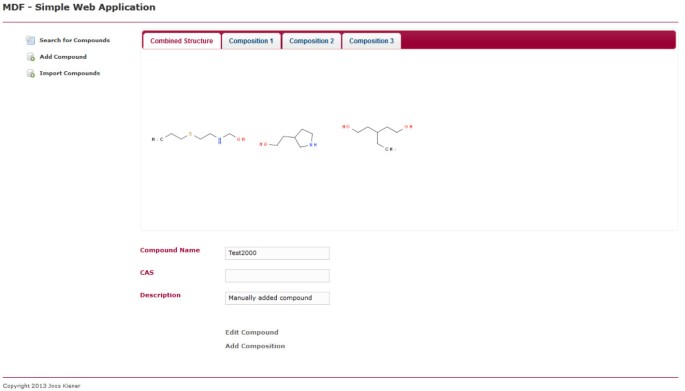
個々の複合ビュー。 このwebページには、単一の化合物が表示されます。 化合物は、ページ内の該当するリンクをクリックすることで編集または削除することができます。 すべての含まれている化学構造および混合物がから成っている各々の個々の構成のためのタブを表示するタブがあります。
図6 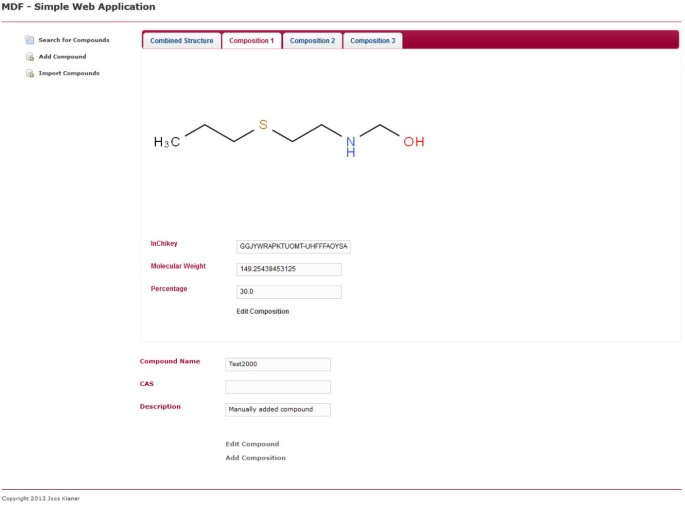
単一の組成。 図5と同じページが表示されますが、”結合構造”タブの代わりに、最初のコンポジションのタブが選択されます。 コンポジションは、ページ内の該当するリンクをクリックすることで編集できます。
パフォーマンス
MDFは、混合物を処理するときに1つの主なパフォーマンスの問題があります。 アプリケーションが混合物、つまり複数の成分を含む化合物を使用する場合、化学構造クエリは、クエリに一致する化合物内のすべての成分について エンドユーザーは、クエリに一度だけ一致する各化合物を表示する必要があるため、これは望ましくありません。 この問題の解決策は、別個のクエリを使用することであり、これがパフォーマンスの問題が発生する場所です。 個別のクエリを実行する場合は、limit句に関係なくデータベース全体を検索する必要があり、実行時間が大幅に増加します。 並べ替えは同じ効果があることに注意してください。 したがって、ソートはパフォーマンスに大きなペナルティを与える可能性があり、ページング時には常にソートして予測可能な結果を得る必要があります。 これをさらに悪化させるために、PostgreSQL用のBingoカートリッジはまだコスト推定のための適切な実装を持っておらず、化学構造指数を使用するためのコストはハードコーディングされ、過小評価されている。 これにより、クエリに結果の量を大幅に制限するwhere句が追加されている場合でも、PostgreSQLクエリプレーナーは構造検索インデックスで常にフルインデックススキャンを使用するように誤解されます。 このような場合、たとえば、CAS番号のインデックスを使用し、フィルタリングにBingo matchsub関数を使用する方が高速です。 関数matchsubは、インデックスなしで部分構造の一致を行います。 もちろん、これはインデックスよりも遅くなりますが、少数の構造に対してのみ行う必要がある場合は、完全なインデックススキャンよりもはるかに高速です。 コスト推定の問題を修正するために、MDFはいくつかの内部計算を行い、構造インデックスまたはmatchsub関数が使用されるかどうかを明示的に決定します。 これにより、パフォーマンスが一桁向上します。 ビンゴカートリッジのサプライヤーはこの問題を認識しており、修正のタイムラインは2013年末であったことに注意してください。 しかし、個別のクエリと並べ替えの主な問題は、リレーショナルデータベースがどのように機能するかに固有のものであり、より良いサブ構造検索インデ MDFでは、単一コンポーネントの複合データベースに対してアプリケーション全体で個別のクエリを無効にする設定も提供されています。
MDFをベンチマークするために、前述のwebアプリケーションが使用されました。 データベースには525573個のユニークな化合物が含まれています。 化合物は亜鉛サブセット13からのものであり、参照pH7のSD-ファイル13_p0.0である。自衛隊、13_p0.1。自衛隊、13_p0.10。自衛隊と13_p0.11。自衛隊… 構造体はSMILESとしてデータベースに格納されます。 約131,000の化学構造を含む各SDファイルのインポートには、化学構造検索インデックスが無効になっている状態で12分かかりました。 すべてのSDファイルがインポートされた後にインデックスを再構築するには、4GBのRAM、Core i5-3220M CPU、512GBのSamsung830SSDを搭載したラップトップで22分か それは百万の混合物が付いている十分に指示されたデータベースをセットアップする1時間10分に合計する。 追加の参考として、12GBのRAM、[email protected]、およびWestern Digital Greenドライブ(5400RPM)で実行されているデータベースを搭載したデスクトップPCで同じインポートが行われ ここでインポートには8分かかり、結論は、インポートはストレージ速度によって制限されるのではなくCPUに制限されているということです。 インデックスの生成には、ラップトップで約22分、デスクトップで約20分かかりました。 ここでの結論は、CPUによって制限されるが、ドライブ速度も重要であるということです。 構造体をmolfilesとして格納するときのインポートおよびインデックス生成のパフォーマンスはベンチマークされませんでした。
サブ構造検索のパフォーマンスは、異なる構成設定でベンチマークされました。 基礎構造検索はBingo PostgreSQLカートリッジによって行われ、このベンチマークはその性能とMDFによるオーバーヘッドを反映しています。 C1cccccc1を除いて、著者は特定の意義を持たない化学構造を描き、検索速度をテストしました。 検索速度は、orgのlogbacks実装によって決定されました。slf4jプロファイラープロファイラー
最初のベンチマークは参照です。 このベンチマークでは、すべての個別クエリを無効にするオプションが使用され、並べ替えは行われませんでした。 MDFは、化学構造検索の最初の出現時に合計ヒット数を実行し、その数がキャッシュされるため、最初のページの読み込みが後続のページよりも遅くなりま 各ページには4つのレコードが含まれています。 結果は、ヒット数で昇順に並べられた表2に示されています。
表2サブ構造検索パフォーマンス ベンチマークは繰り返されましたが、今回は個別のクエリが有効になりました。 最初のページの読み込み時間は、countクエリが実行され、distinct句のためにcountクエリとほぼ同じ時間がかかる実際のクエリが実行されるために倍増します。 2番目のページは、同じ理由で最初のページと比較して常にロードに半分の時間がかかります(表3)。 データベース内のすべての化合物は一つの成分のみで構成されているため、ヒット数は表2のものと同じです。
表3異なる結果を持つサブ構造検索パフォーマンス 結果は、Bingoがベンゼン環のような一般的なサブ構造クエリに対して最適化を行わないことを示しているため、ほとんどすべての分子がこの機能を持つデータベース内のc1cccccc1を検索するのは非常に遅いことを示している。 このようなシナリオで検索速度を向上させるには、追加のプロパティでフィルタリングすることをお勧めします。 したがって、ベンチマークは、”ZINC34″で始まる化合物名の追加フィルタで繰り返されました。
表4は、Bingo PostgreSQLカートリッジのコスト推定問題の回避策としてのMDF最適化の利点を示しています。 この最適化がなければ、ベンチマークの性能は表3と同じになります。
表4複合名の個別のクエリと追加のフィルタ’ZINC34%’を使用したサブ構造検索 MDFはビンゴカートリッジの類似検索機能も使用しています。 その性能は、Jaccard指数としても知られている谷本類似度尺度を用いて0.9の類似度スコアを有する化合物を検索することによって試験された。 その結果を表5に示す。
表5谷本類似性検索性能:少なくとも90%の類似性を持つヒット Outlook
化学構造描写を生成するためにIndigo toolkitを使用し ツールキットは、ヘテロ原子の着色、結合の長さおよび幅、およびより多くの方法を含む多くの方法で構造を生成するように構成することができる。 現在、これはハードコードされており、ユーザーが調整することはできません。 次のステップは、これらの構成オプションを公開して、Javaプロパティファイルを介して設定できるようにすることです。 また、そのような化合物が重要であった地域でMDFを使用可能にするためには、塩および溶媒和物の取り扱いが実施されなければならない。MDFを使用するには、Javaでプログラミングできる必要があり、Spring frameworkとその構成方法に関する基本的な知識が必要です。 これは対象者層を限る。 したがって、次のステップは、エンティティクラスとそのリポジトリとサービスの自動生成のようなMDFの使用を容易にするための追加のツールを作 これらのツールは、ユーザーがエンティティごとに目的のプロパティと目的の検索方法を定義できるように構成可能である必要があります。 オプションはmavenプラグインです。 Mavenプラグインは、QueryDSL-mavenプラグインによって行われるメタモデル作成のようなコードを生成できます。 別のオプションは、Project Lombokのようにコンパイル時にコードを生成する注釈です。
最後のステップは、管理者がwebフォーム上のエンティティの目的のプロパティを入力し、ボタンをクリックするだけで、化学構造検索機能を持つ新し これにはかなりの開発努力が必要であることは明らかです。
-
-



