
Lauri Hartikkaによって

シンプルなチェスAIを作成するのに役立ついくつかの基本的な概念を見てみましょう。
- 移動生成
- ボード評価
- minimax
- アルファベータプルーニング。
各ステップで、我々はこれらの時の試練を経たチェスプログラミング技術のいずれかで私たちのアルゴリズムを改善します。 それぞれがアルゴリズムの演奏スタイルにどのように影響するかを説明します。最終的なAIアルゴリズムはGitHubで見ることができます。
ステップ1:移動生成とボードの可視化
私たちは、チェスを使用します。移動生成のためのjsライブラリ、およびチェス盤。ボードを視覚化するためのjs。 移動生成ライブラリは基本的にチェスのすべてのルールを実装しています。 これに基づいて、与えられたボード状態のすべての法的移動を計算できます。
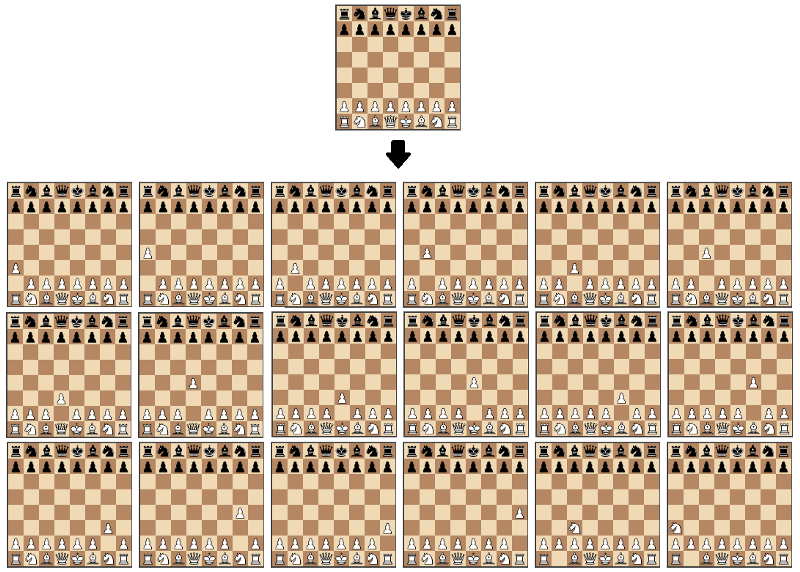
これらのライブラリを使用すると、最も興味深いタスクにのみ焦点を当てるのに役立ちます。
すべての可能な動きからランダムな動きを返す関数を作成することから始めます。
このアルゴリズムは非常に堅実なチェスプレーヤーではありませんが、実際に対戦することができるので、良い出発点です。
ステップ2 : 位置評価
さて、特定の位置でどちらの側が強いかを理解しようとしましょう。 これを達成する最も簡単な方法は、次の表を使用してボード上のピースの相対的な強さをカウントすることです。

評価関数を使用すると、最高の評価を与える動きを選択するアルゴリズムを作成することができます。
唯一の具体的な改善は、可能であれば、私たちのアルゴリズムは今、作品をキャプチャします。
ステップ3:Minimaxを使用してツリーを検索
次に、アルゴリズムが最良の動きを選択できる検索ツリーを作成します。 これは、Minimaxアルゴリズムを使用して行われます。
このアルゴリズムでは、すべての可能な動きの再帰的な木が与えられた深さまで探索され、位置は木の終わりの”葉”で評価されます。
その後、移動する白か黒かに応じて、子の最小値または最大値のいずれかを親ノードに返します。 (つまり、各レベルで結果を最小化または最大化しようとします。)
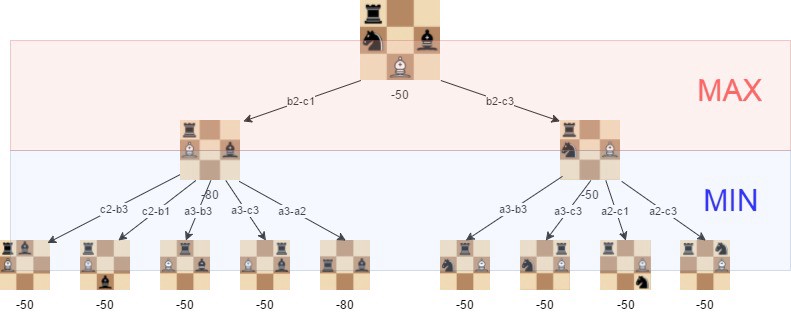
minimaxを使用すると、アルゴリズムはチェスの基本的な戦術を理解し始めています。
minimaxアルゴリズムの有効性は、達成できる検索深度に大きく基づいています。 これは、次のステップで改善するものです。ステップ4
ステップ4
ステップ5: Alpha-beta pruning
Alpha-beta pruningは、検索ツリー内のいくつかの枝を無視することを可能にするminimaxアルゴリズムの最適化方法です。 これは、同じリソースを使用しながら、minimax検索ツリーをより深く評価するのに役立ちます。
アルファベータプルーニングは、以前に発見された動きよりも悪い状況につながる動きを見つけた場合、検索ツリーの一部の評価を停止できる状況に基
alpha-beta pruningはminimaxアルゴリズムの結果に影響を与えません—それはそれをより速くするだけです。
アルファ-ベータアルゴリズムは、良い動きにつながるパスを最初に訪問すると、より効率的です。
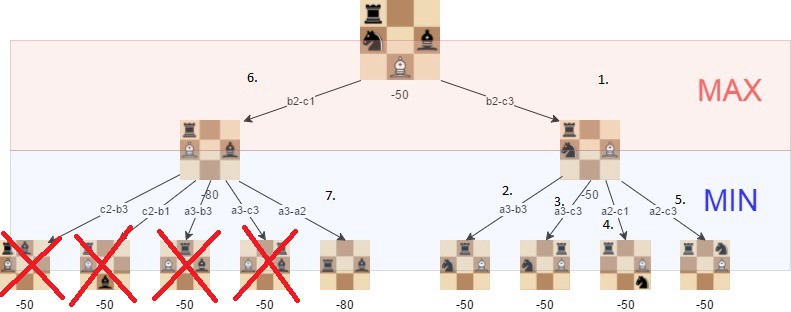
alpha-betaを使用すると、次の例に示すように、minimaxアルゴリズムに大幅なブーストが得られます:

チェスAIのアルファベータ改良版を試してみるには、このリンクに従ってください。
ステップ5:評価関数の改善
最初の評価関数は、ボード上にある材料だけを数えるので、非常に素朴です。 これを改善するために、作品の位置を考慮した要因を評価に追加します。 たとえば、ボードの中央にある騎士は、ボードの端にある騎士よりも優れています(より多くのオプションがあり、したがってよりアクティブであるため)。
もともとchess-programming-wikiで説明されているpiece-squareテーブルのわずかに調整されたバージョンを使用します。
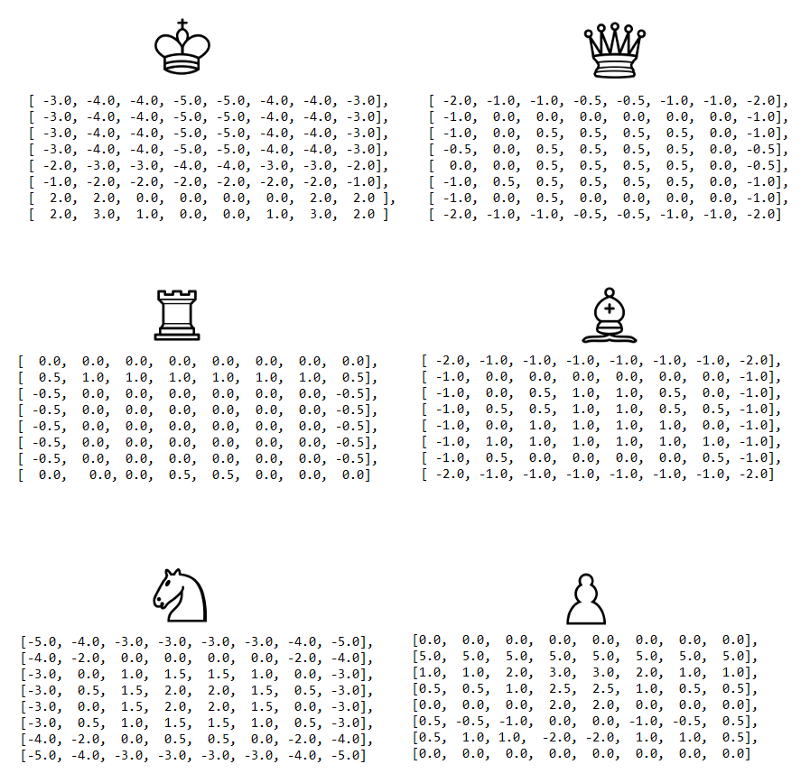
次の改善により、少なくともカジュアルプレイヤーの観点から、いくつかの”まともな”チェスを再生するアルゴリズムを取得し始めます。
結論
単純なチェスのアルゴリズムの強さは、愚かな間違いをしないということです。 これは、それはまだ戦略的な理解を欠いている、と述べました。
ここで紹介した方法で、基本的なチェスをプレイできるチェス再生アルゴリズムをプログラムすることができました。 最終的なアルゴリズムの”AI-part”(移動生成を除く)はわずか200行のコードであり、基本的な概念は実装が非常に簡単です。 最終バージョンはGitHubで確認できます。
アルゴリズムにさらに改善できるいくつかの改善は、例えば次のようになります。
- 移動順序
- より高速な移動生成
- およびエンドゲーム固有の評価。