
Abbiamo testato una varietà di configurazioni, dimensioni di oggetti e conteggi di lavoratori client per massimizzare il throughput di un cluster Ceph a sette nodi per carichi di lavoro di oggetti piccoli e grandi. Come dettagliato nel primo post, il cluster Ceph è stato creato utilizzando un singolo OSD (Object Storage Device) configurato per HDD, con un totale di 112 OSD per cluster Ceph. In questo post, capiremo le prestazioni top-line per le diverse dimensioni degli oggetti e carichi di lavoro.
Nota: I termini “read” e HTTP GET sono usati in modo intercambiabile in questo post, così come i termini HTTP PUT e “write.”
Carico di lavoro a oggetti di grandi dimensioni
I carichi di lavoro a input/output sequenziali a oggetti di grandi dimensioni (I / O) sono uno dei casi d’uso più comuni per l’archiviazione di oggetti Ceph. Questi carichi di lavoro ad alto throughput includono analisi dei Big Data, sistemi di backup e archiviazione, archiviazione di immagini, streaming audio e video. Per questi tipi di carichi di lavoro il throughput (MB/s o GB/s) è la metrica chiave che definisce le prestazioni dello storage.
Come mostrato nella tabella 1 Oggetto di grandi dimensioni 100% HTTP GET e HTTP PUT workload hanno mostrato scalabilità sub-lineare quando si incrementa il numero di host RGW. Come tale abbiamo misurato ~ 5,5 GBps di larghezza di banda aggregata per i carichi di lavoro HTTP GET e HTTP PUT e, curiosamente, non abbiamo notato la saturazione delle risorse nei nodi del cluster Ceph.
Questo cluster può sfornare di più se possiamo indirizzare più carico ad esso. Quindi abbiamo identificato due modi per farlo. 1) Aggiungere più nodi client 2) Aggiungere più nodi RGW. Non abbiamo potuto andare con l’opzione 1 in quanto eravamo limitati dai nodi client fisici disponibili in questo laboratorio. Quindi abbiamo optato per l’opzione 2 e abbiamo eseguito un altro giro di test, ma questa volta con 14 RGWS.
Come mostrato nella tabella 2, rispetto al test 7 RGW, il test 14 RGW ha prodotto prestazioni di scrittura superiori del 14%, raggiungendo ~6,3 GBps, allo stesso modo, il carico di lavoro HTTP GET ha mostrato prestazioni di lettura superiori del 16%, superando ~6,5 GBps. Questo è stato il throughput aggregato massimo osservato su questo cluster dopo il quale è stata notata la saturazione del supporto (HDD) come illustrato nella Figura 1. Sulla base dei risultati, riteniamo che se avessimo aggiunto più nodi OSD Ceph a questo cluster, le prestazioni avrebbero potuto essere ulteriormente ridimensionate, fino a quando limitate dalla saturazione delle risorse.
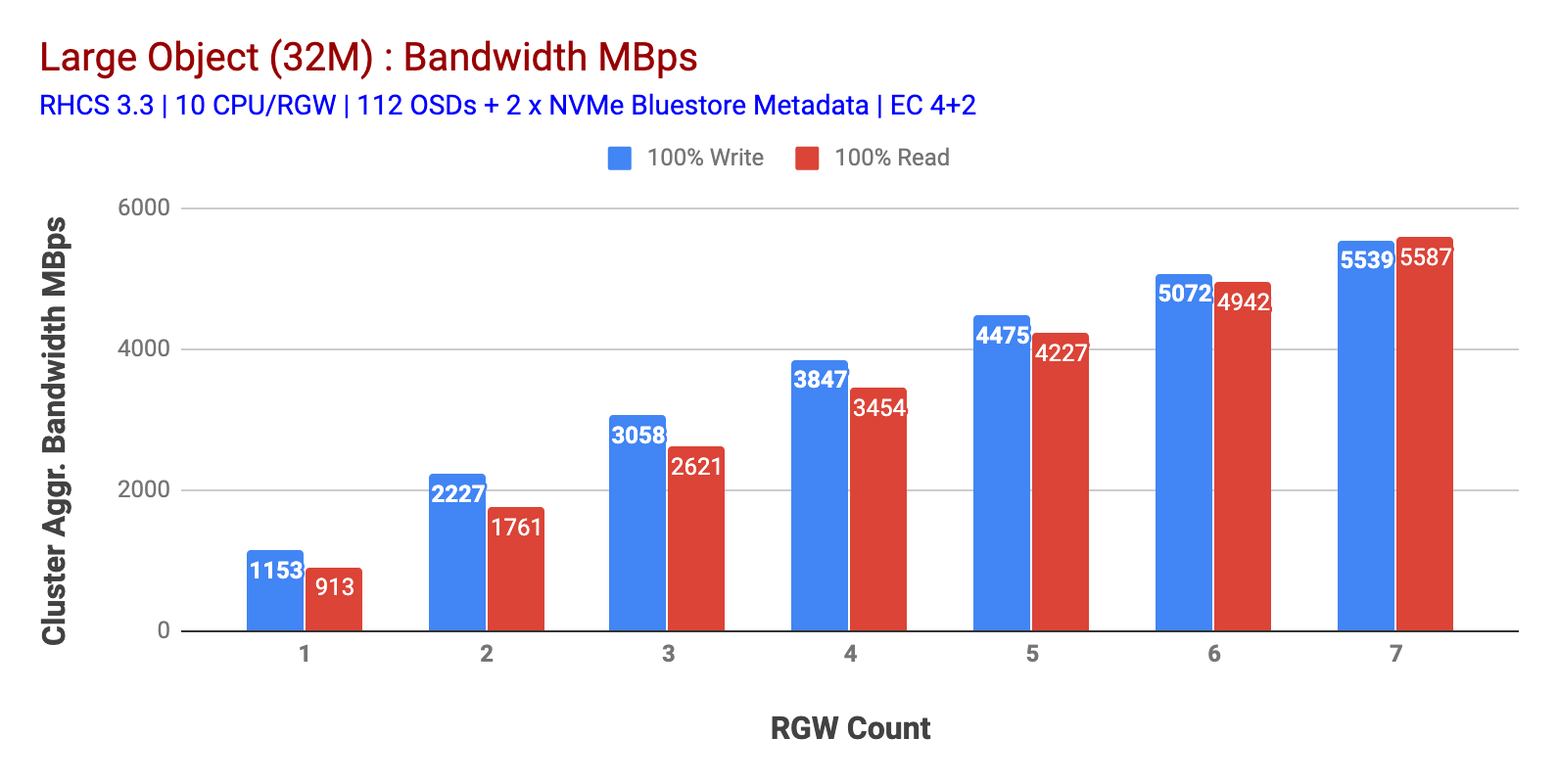
Grafico 1: Grande Oggetto di prova
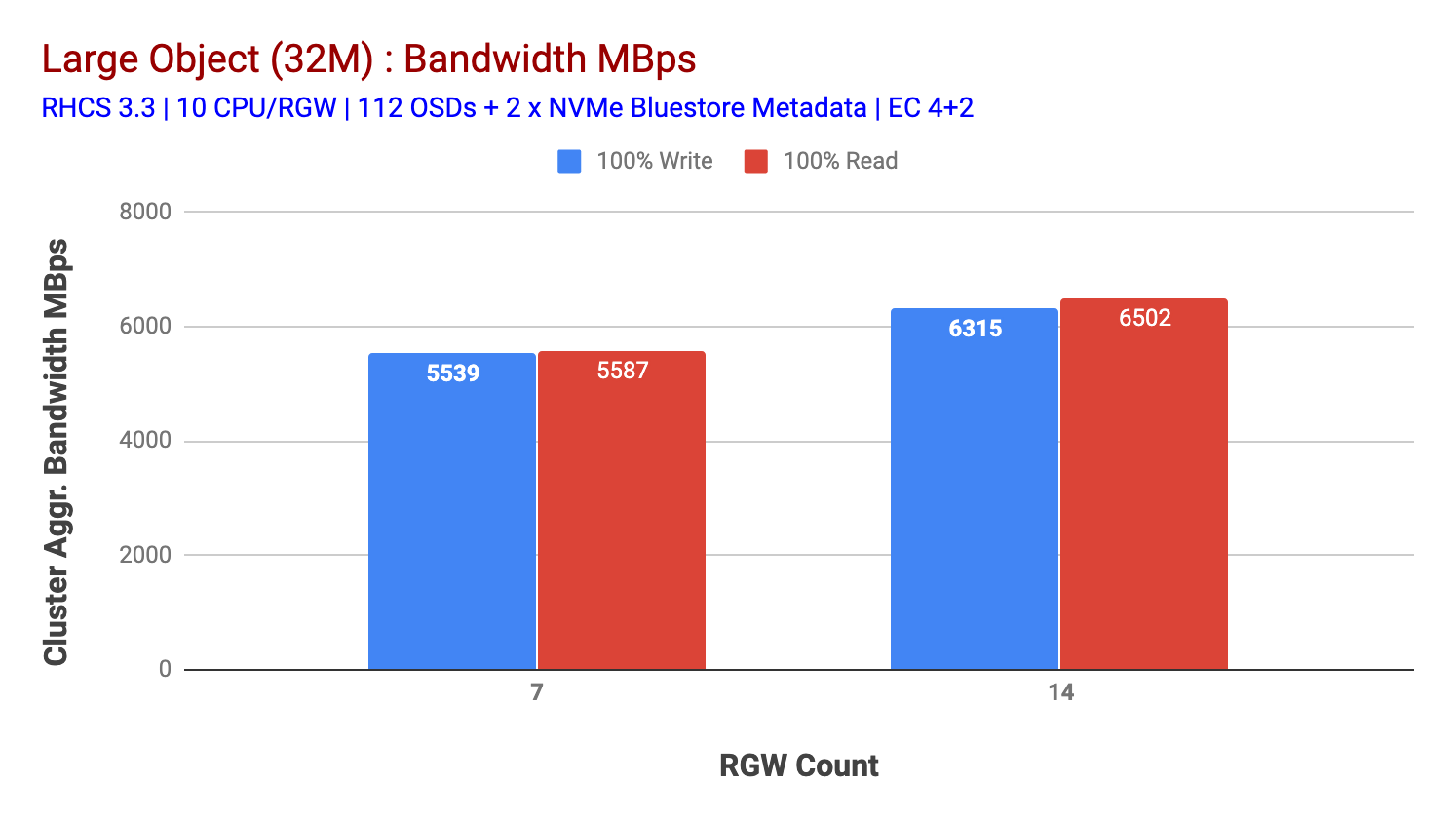
Grafico 2: Grande Oggetto di prova con 14 RGWs
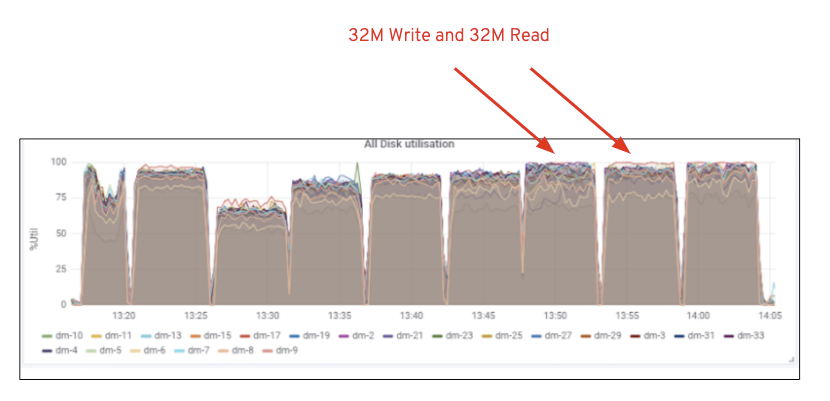
Figura 1: Ceph OSD (HDD) media utilization
Small Object workload
Come mostrato nella tabella 3 small object 100% HTTP GET e HTTP PUT workload hanno mostrato scalabilità sub-lineare quando si incrementa il numero di host RGW. Come tale abbiamo misurato ~ 6.2 K Ops throughput per HTTP PUT a 9ms applicazione scrivere latenza e ~ 3.2 K Ops per HTTP GET carichi di lavoro con 7 istanze RGW.
Fino a 7 istanze RGW, non abbiamo notato la saturazione delle risorse, quindi abbiamo raddoppiato le istanze RGW scalandole a 14 e osservato prestazioni degradate per il carico di lavoro HTTP PUT che è attribuito alla saturazione dei media, mentre HTTP GET prestazioni scalate e superate a ~4.5 K Ops. Come tale, le prestazioni di scrittura avrebbero potuto scalare più in alto, se avessimo aggiunto più nodi OSD Ceph. Per quanto riguarda le prestazioni di lettura, riteniamo che l’aggiunta di più nodi client avrebbe dovuto migliorarlo, ma non avevamo più nodi fisici in laboratorio per testare questa ipotesi.
Un’altra osservazione interessante dal grafico 3 è il tempo di risposta medio ridotto per i carichi di lavoro HTTP PUT che misuravano a 9ms mentre HTTP GET mostrava 17ms di latenza media misurata dall’applicazione che generava il carico di lavoro. Riteniamo che uno dei motivi della latenza dell’applicazione a una cifra per il carico di lavoro di scrittura sia la combinazione di miglioramenti delle prestazioni provenienti dal back-end OSD BlueStore e dalle alte prestazioni Intel Optane NVMe utilizzate per eseguire il backup del dispositivo metadati BlueStore. Vale la pena notare che ottenere una latenza media di scrittura a una cifra da un sistema di archiviazione di oggetti non è banale. Come illustrato nella tabella 3, Ceph object storage quando distribuito con backend OSD BlueStore e Intel Optane per i metadati può raggiungere il throughput di scrittura a tempi di risposta inferiori.
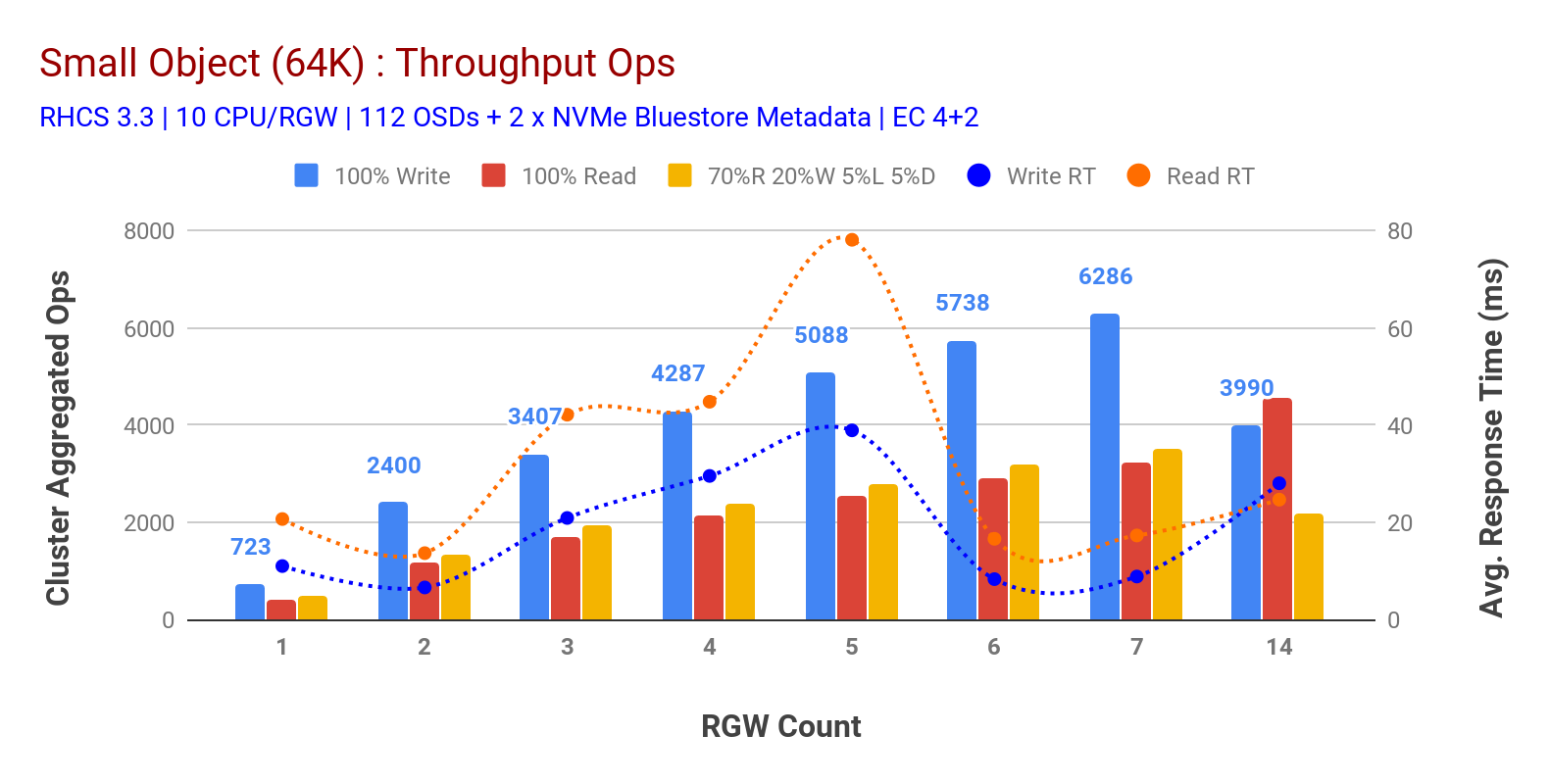
Grafico 3: Small Object Test
Sommario e successivo
Il cluster di dimensioni fisse utilizzato in questo test ha fornito ~6,3 GBps e ~6,5 GBps di larghezza di banda di oggetti di grandi dimensioni per i carichi di lavoro di scrittura e lettura, rispettivamente. Lo stesso cluster per oggetti di piccole dimensioni ha fornito ~ 6,5 K Ops e ~ 4,5 K Ops per il carico di lavoro di scrittura e lettura, rispettivamente.
I risultati hanno anche dimostrato che BlueStore OSD in combinazione con Intel Optane NVMe ha fornito una latenza media delle applicazioni a una cifra, che non è banale per i sistemi di archiviazione di oggetti. Nel prossimo post, esploreremo le prestazioni associate al bucket dynamic sharding e in che modo il bucket pre-sharding può aiutare nelle prestazioni deterministiche.