
Funzionalità
di Seguito è un elenco delle funzionalità di base di MDF:
-
la struttura Chimica di ricerca: Full, Sub, SMARTS, Similarity, Formula
-
Le ricerche di strutture chimiche possono essere combinate con ricerche di proprietà
-
Le ricerche di strutture chimiche sono impaginate e memorizzate nella cache
-
Supporto per composti multicomponenti (miscele)
-
3 entità ricercabili di strutture chimiche: ChemicalCompound, Contenibile e ChemicalCompoundContainer
-
l’Importazione e l’Esportazione di SD-File per il al di sopra dei 3 enti
-
Transazionale di accesso al database
-
di sicurezza Opzionale (autorizzazione)
Con il design e la funzionalità del MDF è possibile costruire diversi tipi di sistema, come ad esempio sistemi di registrazione, sistemi di inventario o di un semplice composto di database. Mentre si potrebbe anche creare il proprio ELN, esiste anche il libero Indigo ELN. Questo ELN è stato creato da GGA Software Services ed è utilizzato da Pfizer .
A differenza di MolDB5R e MyMolDB , MDF non è un’applicazione web standalone completamente funzionale con ricerca di strutture chimiche. Come suggerisce il nome, è un framework per semplificare la creazione di tale applicazione. MDF può anche essere utilizzato per creare applicazioni desktop locali o client-server. MDF è destinato agli sviluppatori di software e non destinato all’uso da parte degli scienziati stessi. Tuttavia le caratteristiche MDF sono molto robuste. La ricerca della struttura chimica viene eseguita nel database e non nel codice dell’applicazione. Quindi è possibile cercare per struttura chimica e altre proprietà allo stesso tempo, i risultati possono essere ordinati per più proprietà e possono essere impaginati (OFFSET SQL e clausole LIMITE). Si noti che se si esegue la ricerca della struttura chimica nel codice dell’applicazione, qualsiasi query richiederà almeno due viaggi nel database, ovvero la ricerca della struttura e successivamente il filtraggio per altre proprietà, l’ordinamento e/o la limitazione. Entrambi devono accadere nella stessa transazione. Non è stato determinato se MolDB5R e MyMolDB lo facciano effettivamente nella stessa transazione.
In MDF i composti chimici possono essere associati a un contenibile, che nei sistemi di registrazione sarebbe un lotto o in un sistema di inventario molto. Un campione specifico fisicamente disponibile in una bottiglia con codice a barre può quindi essere associato a un contenitore. Questi contenitori possono anche essere ricercati dalla struttura chimica. Questa è la base per la creazione di un sistema di inventario. Gli sviluppatori possono aggiungere tutte le proprietà aggiuntive che vogliono a ciascuna delle entità e tutte sono ricercabili insieme alla struttura chimica.
Tutto l’accesso ai dati in MDF è transazionale per evitare incongruenze di dati. MDF può essere configurato per utilizzare un pool di connessioni al database. Quando si esegue l’interrogazione di un RDBMS, la creazione di una connessione richiede spesso più tempo della query stessa e, quindi, se si dispone già di connessioni aperte, i tempi di risposta possono essere ridotti.
Per la ricerca di similarità MDF esposto gli algoritmi forniti dalla cartuccia Bingo che sono Tanimoto, Tversky e metrica euclidea per sottostrutture.
MDF è pronto per essere utilizzato con molla di sicurezza. La sicurezza è facoltativa. MDF offre sicurezza a livello di metodo (autorizzazione). Non offre alcuna funzionalità di autenticazione.
Gestione della miscela
MDF supporta composti chimici multicomponenti. La ricerca per sottostruttura restituirà tutti i composti che hanno almeno un componente (struttura chimica) corrispondente alla struttura della query. Questo è importante perché i prodotti di reazione che possono essere inseriti in un sistema di registrazione chimica sono quasi sempre miscele a meno che non venga eseguita un’ampia purificazione.
Se una voce in un file SD importato è costituita da più strutture disconnesse, si presume che questa voce sia una miscela e ogni struttura sia memorizzata come una struttura chimica separata.
Normalizzazione della struttura
Per impostazione predefinita MDF memorizza le strutture chimiche man mano che vengono inviate. MDF non fa alcuna standardizzazione / normalizzazione delle strutture chimiche. Spetta allo sviluppatore che utilizza MDF assicurarsi che le strutture chimiche siano correttamente normalizzate prima di salvarle nel database. Attualmente si suggerisce agli sviluppatori di implementare tale funzionalità sovrascrivendo il metodo preSave () di ChemicalCompoundServiceImpl. Questo metodo viene chiamato prima che qualsiasi composto chimico venga creato o aggiornato. All’interno di questo metodo il composto chimico e tutte le strutture chimiche di cui è costituito possono essere liberamente manipolati a piacere. Si noti che ogni composto salvato verrà elaborato con questo metodo.
Sali, solvati e soluzioni
La versione attuale di MDF 1.0.1 non ha alcuna manipolazione speciale per sali, solvati o soluzioni. MDF memorizzerà componenti separati in un file di struttura chimica come struttura chimica separata. Quindi salvare un sale come 1 = CC = CC = C1. sarà rappresentato come una miscela dei due ioni senza alcuna percentuale impostata. Una ricerca di struttura esatta per uno ion restituirebbe questo sale. Se il sale ha una carica maggiore di 1 e più ioni associati ad esso come 1 = CC = C = C1.. il sale sarà conservato come una miscela di 1 = CC = C = C1 e senza alcuna percentuale impostata. Se la struttura chimica è un singolo ion sarà memorizzato e ricercabile come qualsiasi altra struttura chimica. Se questo comportamento non è adatto in un caso specifico, gli sviluppatori possono implementare funzionalità di gestione salt e solvate nel metodo preSave ().
Alcuni sistemi commerciali sembrano anche non avere modo di gestire soluzioni. Si consiglia di creare il composto come se fosse puro e aggiungere le informazioni sulla soluzione come campi separati a livello di composto.
Esempio di applicazione web
È stata creata una semplice applicazione web che utilizza MDF. L’applicazione web fa uso di Spring MVC. L’applicazione non utilizza l’integrazione di sicurezza e non utilizza le entità Containable e ChemicalCompoundContainer. Utilizza solo entità ChemicalCompound. L’applicazione è un database composto per composti multi-componente. Ha una pagina per importare le strutture chimiche in un file SD nel database composto. Il database può essere cercato per sottostruttura e proprietà. Utilizza JSME per disegnare le strutture chimiche (Figura 3). La pagina dei risultati della ricerca visualizza i risultati della ricerca in modo tabellare e paginato. Quando viene eseguita una ricerca sottostruttura, la sottostruttura verrà evidenziata nei risultati della ricerca (Figura 4). I risultati di una ricerca possono essere esportati come file SD. I risultati della ricerca contengono un collegamento a una singola vista composta. Le proprietà del composto possono essere modificate e le composizioni possono essere aggiunte, modificate e cancellate (Figure 5, 6). Quando si modifica un composto o una composizione, l’applicazione gestisce le modifiche simultanee in modo trasparente e viene visualizzata la finestra di risoluzione dei conflitti in cui l’utente può selezionare i valori da utilizzare per ciascuna proprietà e quindi salvare la nuova versione.
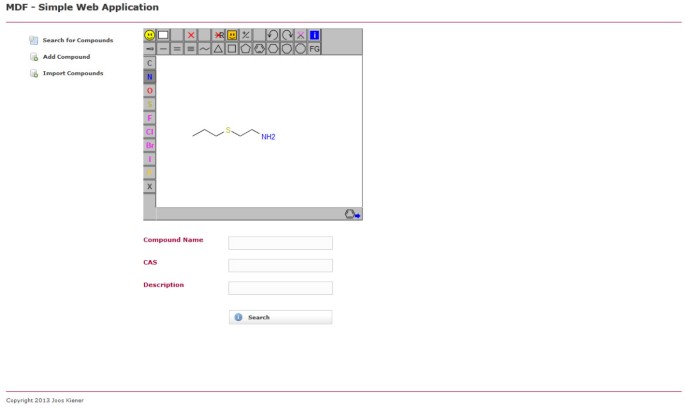
Pagina di ricerca dell’applicazione web di esempio utilizzando MDF. Un utente può cercare nel database composto per sottostruttura chimica e / o proprietà come nome composto o numero CAS.

la pagina dei Risultati di una sottostruttura di ricerca. I risultati vengono visualizzati in una tabella di paging generata dai datatables del plugin jQuery . Le immagini della struttura chimica hanno la sottostruttura corrispondente evidenziata in rosso. Facendo clic nell’immagine della struttura chimica verranno visualizzati i SORRISI per esso.
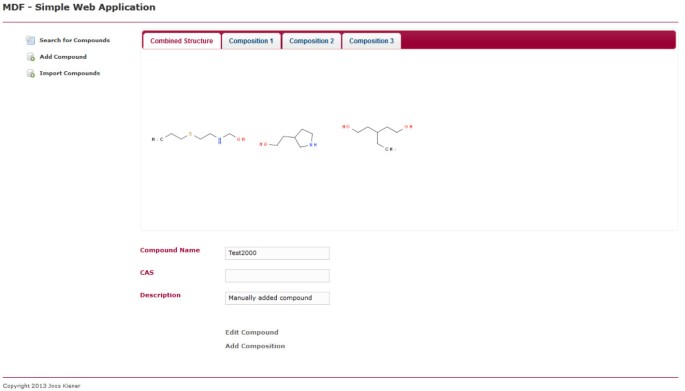
i Singoli composti vista. Questa pagina web visualizza un singolo composto. Il composto può essere modificato o eliminato facendo clic sul link corrispondente all’interno della pagina. C’è una scheda che visualizza tutte le strutture chimiche contenute e una scheda per ogni singola composizione del composto.
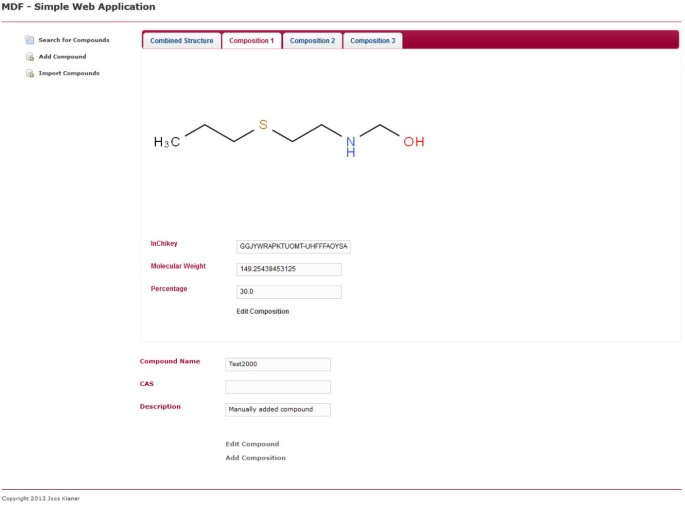
composizione Unica. Mostra la stessa pagina della Figura 5 ma al posto della scheda Struttura combinata, viene selezionata la scheda della prima composizione. La composizione può essere modificata cliccando sul link corrispondente all’interno della pagina.
Prestazioni
MDF ha un problema di prestazioni principale quando si maneggiano miscele. Se un’applicazione utilizza miscele, cioè composti con più componenti, una query di struttura chimica restituirà una riga per ogni componente in un composto corrispondente alla query. Questo è indesiderabile perché gli utenti finali vogliono vedere ogni composto che corrisponde alla query solo una volta. La soluzione al problema consiste nell’utilizzare una query distinta ed è qui che si verifica il problema delle prestazioni. Se si esegue una query distinta, è necessario cercare l’intero database indipendentemente dalla clausola limit che aumenta notevolmente il tempo di esecuzione. Si noti che l’ordinamento ha lo stesso effetto. Quindi l’ordinamento può avere anche un’enorme penalizzazione delle prestazioni e quando si esegue il paging si dovrebbe sempre ordinare per ottenere un risultato prevedibile. Per rendere questo ancora peggiore Cartuccia Bingo per PostgreSQL non ha ancora una corretta implementazione per la stima dei costi e il costo per l’utilizzo dell’indice di struttura chimica è hard coded e sottovalutato. Ciò induce in errore la pialla di query PostgreSQL per utilizzare sempre una scansione completa dell’indice sull’indice di ricerca della struttura anche quando la query ha una clausola where aggiuntiva che limita notevolmente la quantità di risultati. In questi casi, ad esempio, sarebbe più veloce utilizzare l’indice per il numero CAS e utilizzare la funzione Bingo matchsub per il filtraggio. La funzione matchsub esegue la corrispondenza della sottostruttura senza indice. Questo è ovviamente più lento rispetto a un indice, ma se deve essere fatto solo per un piccolo numero di strutture è molto più veloce della scansione completa dell’indice. Per risolvere il problema della stima dei costi, MDF esegue alcuni calcoli interni per decidere esplicitamente se viene utilizzata l’indice di struttura o la funzione matchsub. Ciò può migliorare le prestazioni di un ordine di grandezza. Si noti che il fornitore della cartuccia Bingo è a conoscenza di questo problema e la tempistica per la correzione era fine del 2013. Tuttavia, il problema principale delle query e dell’ordinamento distinti è inerente al funzionamento dei database relazionali e non può essere risolto se non con un indice di ricerca della sottostruttura migliore o un hardware migliore. MDF offre anche un’impostazione per disabilitare query distinte a livello di applicazione per database composti a singolo componente.
Per eseguire il benchmark MDF è stata utilizzata l’applicazione Web descritta in precedenza. Il database contiene 525573 composti unici. I composti provengono dal sottoinsieme di zinco 13 a pH di riferimento 7 i file SD 13_p0.0.sdf, 13_p0. 1.sdf, 13_p0. 10.sdf e 13_p0. 11.sdf. Le strutture sono memorizzate nel database come SORRISI. L’importazione di ciascuno dei file SD, che contengono circa 131 ‘ 000 strutture chimiche, ha richiesto 12 minuti con l’indice di ricerca delle strutture chimiche disabilitato. Ricostruire l’indice dopo che tutti i file SD sono stati importati ha richiesto 22 min su un laptop con 4 GB di RAM, CPU Core i5-3220M e un SSD Samsung 830 da 512 GB. Che ammonta a 1 h 10 min per impostare un database completamente indicizzato con mezzo milione di composti. Come riferimento aggiuntivo la stessa importazione è stata effettuata su un PC desktop con 12 GB di RAM, i7-875K @ 3.4 GHz e il database in esecuzione su un’unità verde Western Digital (5400 RPM). Qui l’importazione ha richiesto 8 min e la conclusione è che l’importazione è limitata dalla CPU piuttosto che limitata dalla velocità di archiviazione. La generazione dell’indice ha richiesto circa 22 min sul laptop e 20 min sul desktop. La conclusione qui è che è limitata più dalla CPU, ma anche la velocità di guida è importante. Le prestazioni di importazione e generazione dell’indice durante l’archiviazione delle strutture come molfiles non sono state sottoposte a benchmark.
Le prestazioni di ricerca della sottostruttura sono state confrontate con diverse impostazioni di configurazione. La ricerca della sottostruttura viene eseguita dalla cartuccia Bingo PostgreSQL e questo benchmark riflette quindi le sue prestazioni e qualsiasi sovraccarico causato da MDF. Con l’eccezione di c1ccccc1 l’autore ha disegnato strutture chimiche senza significato specifico e testato la velocità di ricerca. La velocità di ricerca è stata determinata dall’implementazione dei logback di org.slf4j. profiler.Profiler.
Il primo benchmark è un riferimento. Questo benchmark ha utilizzato l’opzione per disabilitare tutte le query distinte e non è stato eseguito alcun ordinamento. MDF esegue un conteggio degli hit totali alla prima occorrenza di una ricerca di strutture chimiche e il conteggio viene memorizzato nella cache, il che fa sì che la prima pagina venga caricata più lentamente delle pagine successive. Ogni pagina contiene 4 record. I risultati sono riportati nella Tabella 2 ordinati in ordine crescente per numero di visite.
Il benchmark è stato ripetuto ma questa volta con query distinte abilitate. Il tempo di caricamento della prima pagina viene raddoppiato perché viene eseguita la query count e quindi viene eseguita la query effettiva che richiede circa la stessa quantità di tempo della query count a causa della clausola distinct. La seconda pagina richiede sempre la metà del tempo di caricamento rispetto alla prima pagina per lo stesso motivo (Tabella 3). Il numero di hit è identico a quelli della Tabella 2 perché tutti i composti nel database sono costituiti da un solo componente.
I risultati mostrano che il Bingo non ottimizzazioni per il comune di sottostruttura query come un anello di benzene e, di conseguenza, la ricerca di c1ccccc1 in un database in cui quasi tutte le molecole hanno questa caratteristica è molto lento. Per migliorare la velocità di ricerca in uno scenario di questo tipo, si consiglia di filtrare per proprietà aggiuntive. Quindi il benchmark è stato ripetuto con un filtro aggiuntivo di nome composto che inizia con “ZINC34”.
La tabella 4 mostra il vantaggio dell’ottimizzazione MDF come soluzione alternativa al problema della stima dei costi nella cartuccia Bingo PostgreSQL. Senza questa ottimizzazione, il benchmark avrebbe le stesse prestazioni indicate nella Tabella 3.
MDF utilizza anche Cartucce Bingo funzionalità di ricerca somiglianza. Le sue prestazioni sono state testate cercando composti con un punteggio di somiglianza di 0,9 utilizzando la misura di somiglianza Tanimoto nota anche come Indice Jaccard . I risultati sono riportati nella Tabella 5.
Outlook
Per generare le raffigurazioni della struttura chimica viene utilizzato il toolkit Indigo. Il toolkit può essere configurato per generare le strutture in molti modi tra cui la colorazione degli eteroatomi, la lunghezza e la larghezza del legame e molti altri. Attualmente questo è hard coded e non può essere regolato dall’utente. Un passo successivo sarebbe quello di esporre queste opzioni di configurazione in modo che possano essere impostate attraverso un file di proprietà Java. Anche la manipolazione di sali e solvati deve essere implementato per rendere MDF utilizzabile in aree dove tali composti sono importanti.
Per utilizzare MDF devi essere in grado di programmare in Java e avrai bisogno di conoscenze di base su Spring framework e su come configurarlo. Questo limita il pubblico di destinazione. Quando si utilizza MDF è necessario scrivere un codice della piastra della caldaia e quindi il passo successivo sarebbe quello di creare strumenti aggiuntivi per facilitare l’utilizzo di MDF come la generazione automatica delle classi di entità e dei loro repository e servizi. Questi strumenti dovrebbero essere configurabili in modo che un utente possa definire le proprietà desiderate per ciascuna delle entità e i metodi di ricerca desiderati. Un’opzione sarebbe un plugin maven. I plugin Maven possono generare codice come la creazione di metamodel eseguita dal plugin QueryDSL-maven. Un’altra opzione sarebbe annotazioni che generano codice in compilazione come fa Project Lombok .
Il passo finale sarebbe quello di creare una piattaforma di applicazioni Web che consente agli amministratori di creare nuove applicazioni Web con funzionalità di ricerca di strutture chimiche semplicemente inserendo le proprietà desiderate per le entità in un modulo Web e facendo clic su un pulsante. È ovvio che ciò richiederebbe uno sforzo significativo di sviluppo.