
különféle konfigurációkat, objektumméreteket és ügyfélmunkások számát teszteltük annak érdekében, hogy maximalizáljuk a hét csomópontú Ceph fürt teljesítményét kis és nagy objektum munkaterhelések esetén. Amint azt az első bejegyzés részletezi, a Ceph klasztert egyetlen, HDD-nként konfigurált OSD (Object Storage Device) felhasználásával építették, Ceph-fürtönként összesen 112 OSD-vel. Ebben a bejegyzésben meg fogjuk érteni a különböző objektumméretek és munkaterhelések csúcsminőségű teljesítményét.
Megjegyzés: A” read “és a HTTP GET kifejezéseket felcserélhetően használják ebben a bejegyzésben, csakúgy, mint a HTTP PUT és az “write” kifejezéseket.”
Nagyobjektum-terhelés
Nagyobjektum-szekvenciális bemeneti/kimeneti (I/O) terhelések a Ceph-objektumok tárolásának egyik leggyakoribb felhasználási esete. Ezek a nagy áteresztőképességű munkaterhelések magukban foglalják a nagy adatelemzést, a biztonsági mentési és archiválási rendszereket, a képtárolást, valamint a hang-és videofolyamatot. Az ilyen típusú munkaterhelések esetében az átviteli sebesség (MB/s vagy GB/s) a legfontosabb mutató, amely meghatározza a tárolási teljesítményt.
amint azt az 1.ábra mutatja nagy objektum 100% HTTP GET és HTTP PUT munkaterhelés szublineáris skálázhatóságot mutatott az RGW gazdagépek számának növelésekor. Mint ilyen, ~5,5 GBps összesített sávszélességet mértünk a HTTP GET és a HTTP PUT munkaterhelésekhez, és érdekes módon nem vettük észre az erőforrás-telítettséget a Ceph fürt csomópontokban.
Ez a klaszter többet tud kiüríteni, ha több terhelést tudunk irányítani rá. Tehát ennek két módját azonosítottuk. 1) Adjon hozzá több ügyfélcsomópontot 2) Adjon hozzá több RGW csomópontot. Nem mehettünk az 1. opcióval, mivel a laborban elérhető fizikai ügyfélcsomópontok korlátoztak minket. Tehát a 2. opciót választottuk, és újabb tesztkört futottunk le, de ezúttal 14 RGW-vel.
amint az a 2. ábrán látható, a 7 RGW teszthez képest a 14 RGW teszt 14% – kal magasabb írási teljesítményt eredményezett, ~6,3 GBps sebességgel, hasonlóan a HTTP GET munkaterhelés 16% – kal magasabb olvasási teljesítményt mutatott, ~6,5 GBps sebességgel. Ez volt az ezen a klaszteren megfigyelt maximális összesített áteresztőképesség, amely után a Média (HDD) telítettségét észlelték az 1.ábrán látható módon. Az eredmények alapján úgy gondoljuk, hogy több Ceph OSD csomópontot adtunk hozzá ehhez a klaszterhez, a teljesítményt még tovább lehetett volna méretezni, amíg az erőforrás-telítettség nem korlátozza.
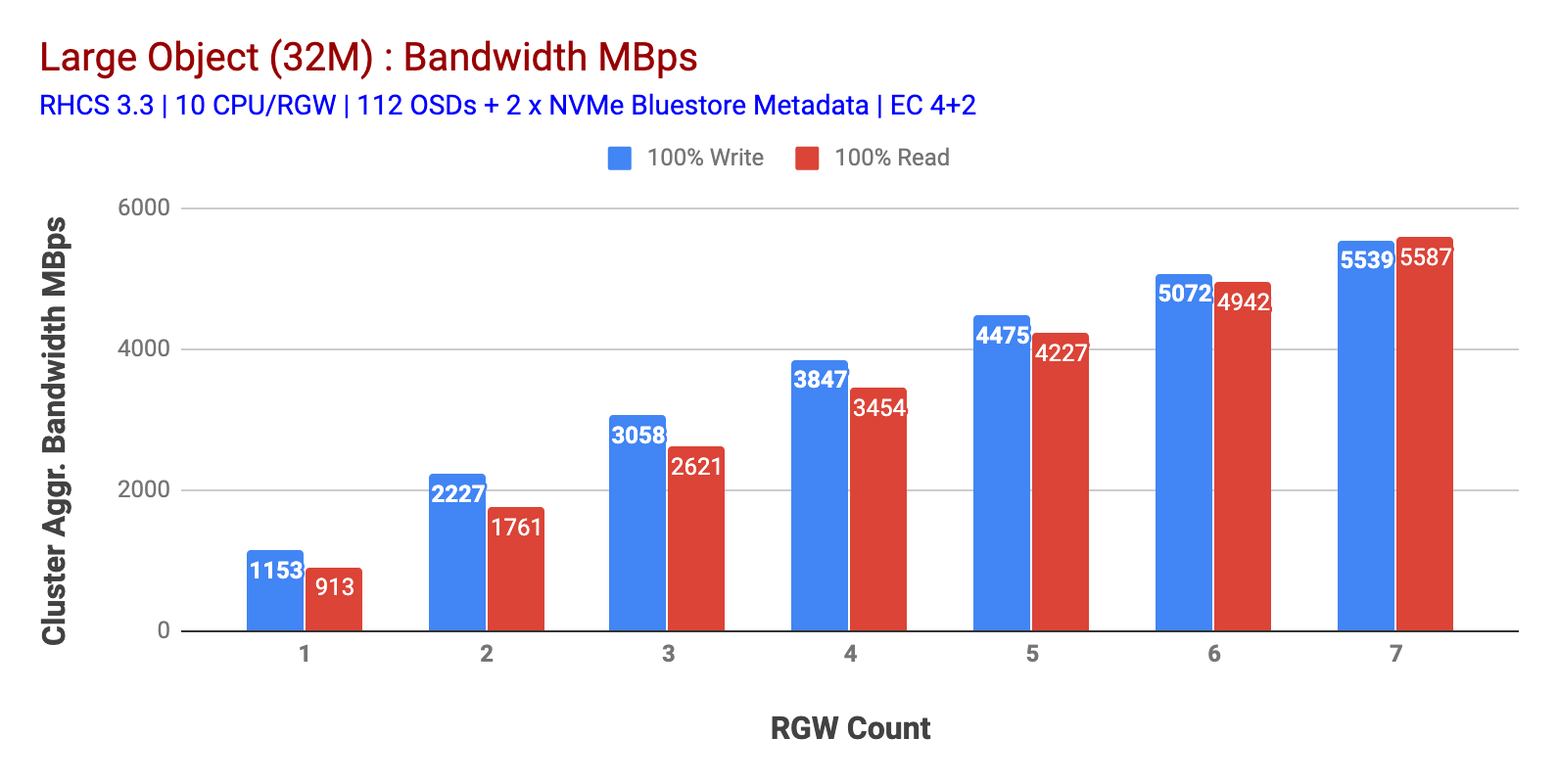
1. ábra: nagy tárgy teszt
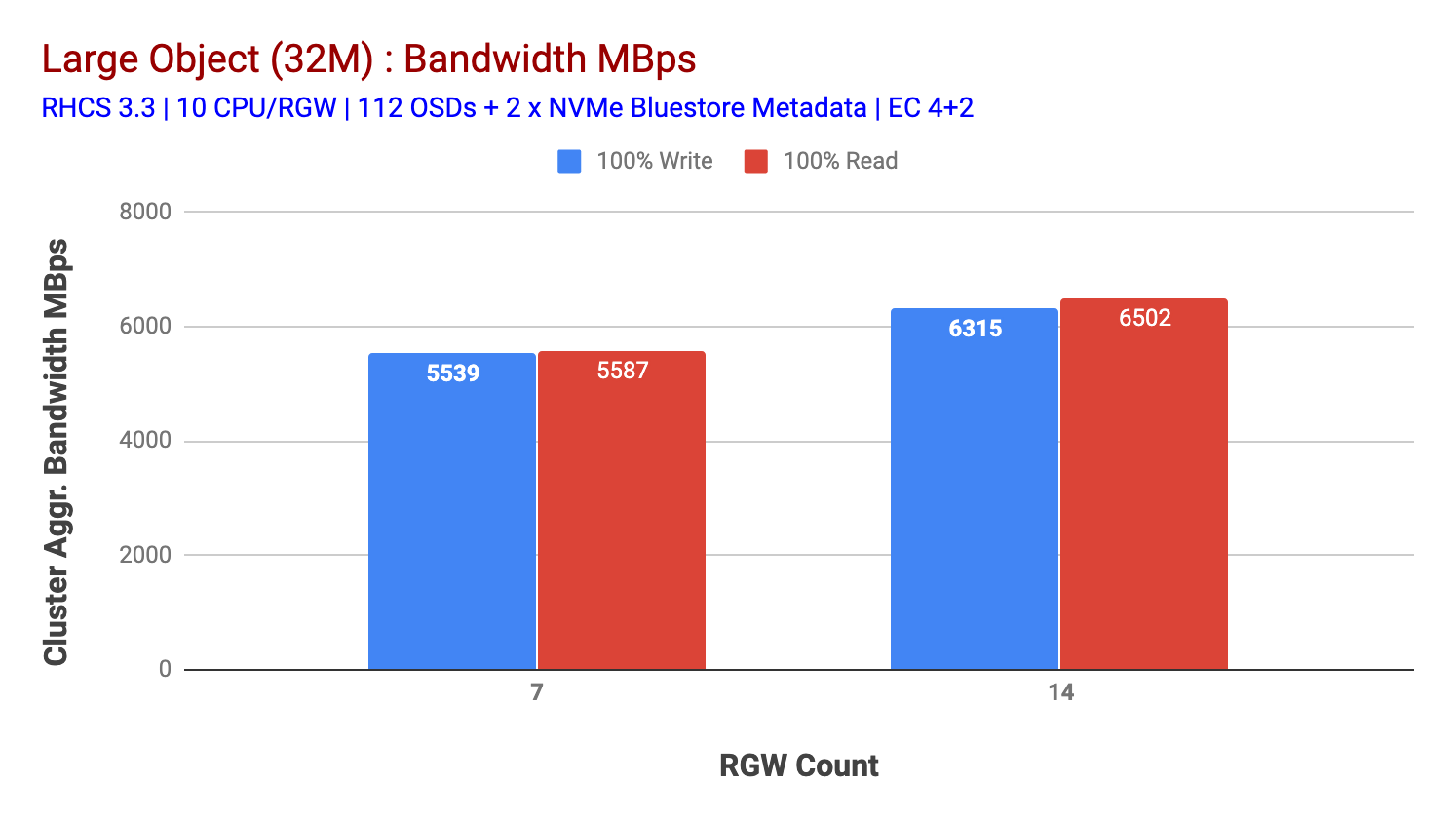
2. ábra: nagy tárgy teszt 14 RGW-vel
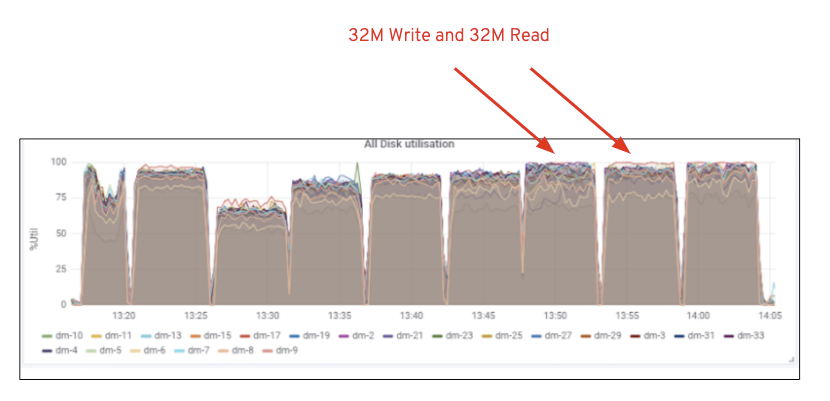
1. ábra: Ceph OSD (HDD) médiafelhasználás
kis objektum munkaterhelés
amint azt a 3.ábra mutatja kis objektum 100% HTTP GET és HTTP PUT a munkaterhelések szublineáris skálázhatóságot mutattak az RGW-gazdagépek számának növelésekor. Mint ilyen, ~6,2 K Ops áteresztőképességet mértünk a HTTP-hez 9 ms-os alkalmazásírási késleltetéssel, és ~3,2 K Ops a HTTP-hez 7 RGW-es példányokkal.
7 RGW példányig nem vettük észre az erőforrás-telítettséget, ezért megdupláztuk az RGW példányokat 14-re méretezve, és megfigyeltük a HTTP PUT munkaterhelés teljesítményének romlását, amelyet a Média telítettségének tulajdonítanak, míg a HTTP GET teljesítményét ~4,5 K Ops-nál növeltük. Mint ilyen, írási teljesítmény volna skálázott magasabb, volna hozzá több Ceph OSD csomópontok. Ami az olvasási teljesítményt illeti, úgy gondoljuk, hogy további ügyfélcsomópontok hozzáadásával javítani kellett volna, de nem volt több fizikai csomópont a laboratóriumban ennek a hipotézisnek a tesztelésére.
egy másik érdekes megfigyelés a 3. táblázatból a csökkentett átlagos válaszidő a HTTP PUT munkaterheléseknél, amelyek 9 ms-nál mértek, míg a HTTP GET 17 ms átlagos késleltetést mutatott az alkalmazás generáló munkaterhelésétől mérve. Úgy gondoljuk, hogy az írási munkaterhelés egyjegyű alkalmazás késleltetésének egyik oka a BlueStore OSD háttérrendszerből származó teljesítményjavítás, valamint a nagy teljesítményű Intel Optane NVMe kombinációja, amelyet a BlueStore metaadat-eszköz támogatására használnak. Érdemes megjegyezni, hogy az egyjegyű írási átlagos késleltetés elérése egy Objektumtároló rendszerből nem triviális. Amint azt a 3. ábra mutatja, A BlueStore OSD backend és az Intel Optane for metaadatok használatával a Ceph objektumtárolás alacsonyabb válaszidő mellett képes elérni az írási teljesítményt.
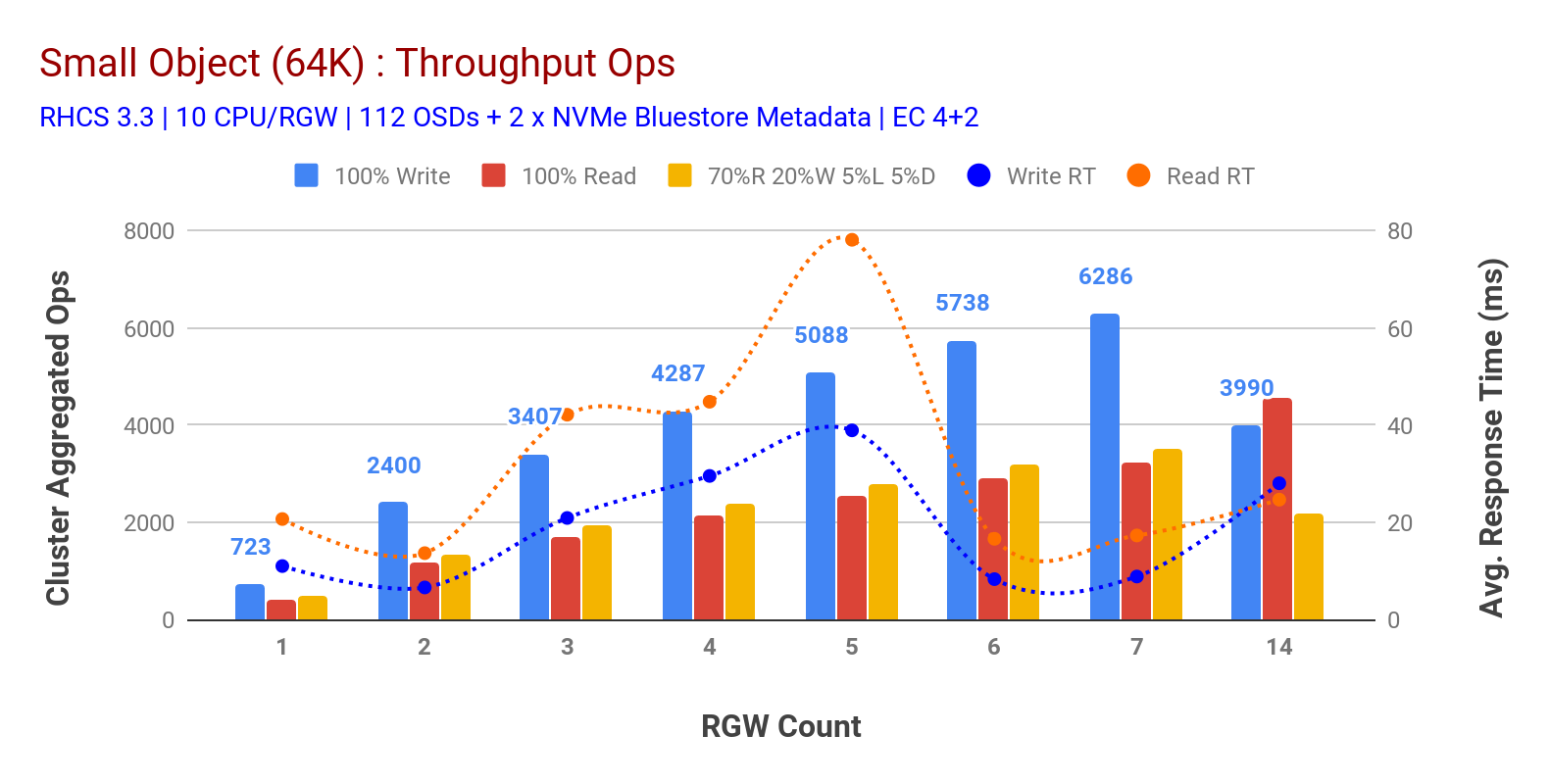
3. ábra: kis objektum teszt
összefoglaló és következő
az ebben a tesztben használt fix méretű fürt ~6,3 GBps, illetve ~6,5 GBps nagy objektum sávszélességet adott az írási és olvasási munkaterhelésekhez. Ugyanaz a fürt a kis objektummérethez ~6,5 K Ops-t, ~4,5 K Ops-t adott az írási és olvasási munkaterheléshez.
Az eredmények azt is kimutatták, hogy a BlueStore OSD az Intel Optane NVMe-vel kombinálva egy számjegyű átlagos alkalmazás késleltetést eredményezett, ami nem triviális az objektumtároló rendszerek esetében. A következő bejegyzésben megvizsgáljuk a vödör dinamikus shardinghoz kapcsolódó teljesítményt, valamint azt, hogy az elő sharding vödör hogyan segíthet a determinisztikus teljesítményben.