
olemme testanneet erilaisia kokoonpanoja, objektikokoja ja asiakastyöntekijöiden määrää maksimoidaksemme seitsemän solmun Ceph-klusterin läpimenon pienille ja suurille objektien työmäärille. Kuten ensimmäisessä postauksessa on esitetty, Ceph-klusteri on rakennettu käyttämällä yhtä kiintolevyä (Object Storage Device), jossa on yhteensä 112 OSD: tä Ceph-klusteria kohti. Tässä viestissä ymmärrämme huippuluokan suorituskyvyn eri kohteiden kokoisille ja työmäärille.
Huomautus: Termejä ” lukea ”ja HTTP GET käytetään vaihdellen koko tämän postauksen, samoin termejä HTTP laittaa ja” kirjoittaa.”
suurten kohteiden työmäärä
suurten kohteiden peräkkäiset input/output (I / O) työkuormat ovat yksi yleisimmistä Ceph-objektien tallennuksen käyttötapauksista. Näihin suuren suoritustehon työkuormiin kuuluvat big data-analytiikka, varmuuskopiointi-ja arkistointijärjestelmät, kuvantallennus sekä äänen ja videon suoratoisto. Tämäntyyppisten työkuormien läpimeno (MB/s tai GB / s) On keskeinen mittari, joka määrittelee tallennustehon.
kuten kaaviossa 1 Large-object 100% HTTP GET and HTTP PUT workout exhibited sub-linear scalability when increpting the number of RGW hosts. Sellaisenaan mittasimme ~5.5 GBps yhdistettyä kaistanleveyttä HTTP GET ja HTTP laittaa työkuormia ja mielenkiintoista emme huomanneet resurssien kylläisyyttä Ceph cluster solmut.
tämä klusteri voi suoltaa lisää, jos voimme suunnata siihen enemmän kuormaa. Joten tunnistimme kaksi tapaa tehdä se. 1) Lisää Lisää asiakkaan solmuja 2) Lisää Lisää RGW-solmuja. Emme voineet mennä vaihtoehto 1, koska olimme rajoittaneet fyysisen asiakkaan solmut saatavilla tässä laboratoriossa. Joten valitsimme vaihtoehdon 2 ja ajoimme toisen kierroksen testejä, mutta tällä kertaa 14 RGWs.
kuten kaaviossa 2, verrattuna 7 RGW-testiin, 14 RGW-testi tuotti 14% korkeamman kirjoitustehon, keveyden ~6.3 GBps, samoin HTTP GET-työmäärä osoitti 16% korkeamman lukutehon, keveyden ~6.5 GBps. Tämä oli suurin tässä klusterissa havaittu aggregoitu läpimenonopeus, jonka jälkeen havaittiin median (HDD) kyllästyminen Kuvan 1 mukaisesti. Tulosten perusteella uskomme, että olemme lisänneet lisää Ceph OSD-solmuja tähän klusteriin, suorituskykyä olisi voitu skaalata vielä pidemmälle, kunnes resurssien kyllästyminen on rajoittanut sitä.
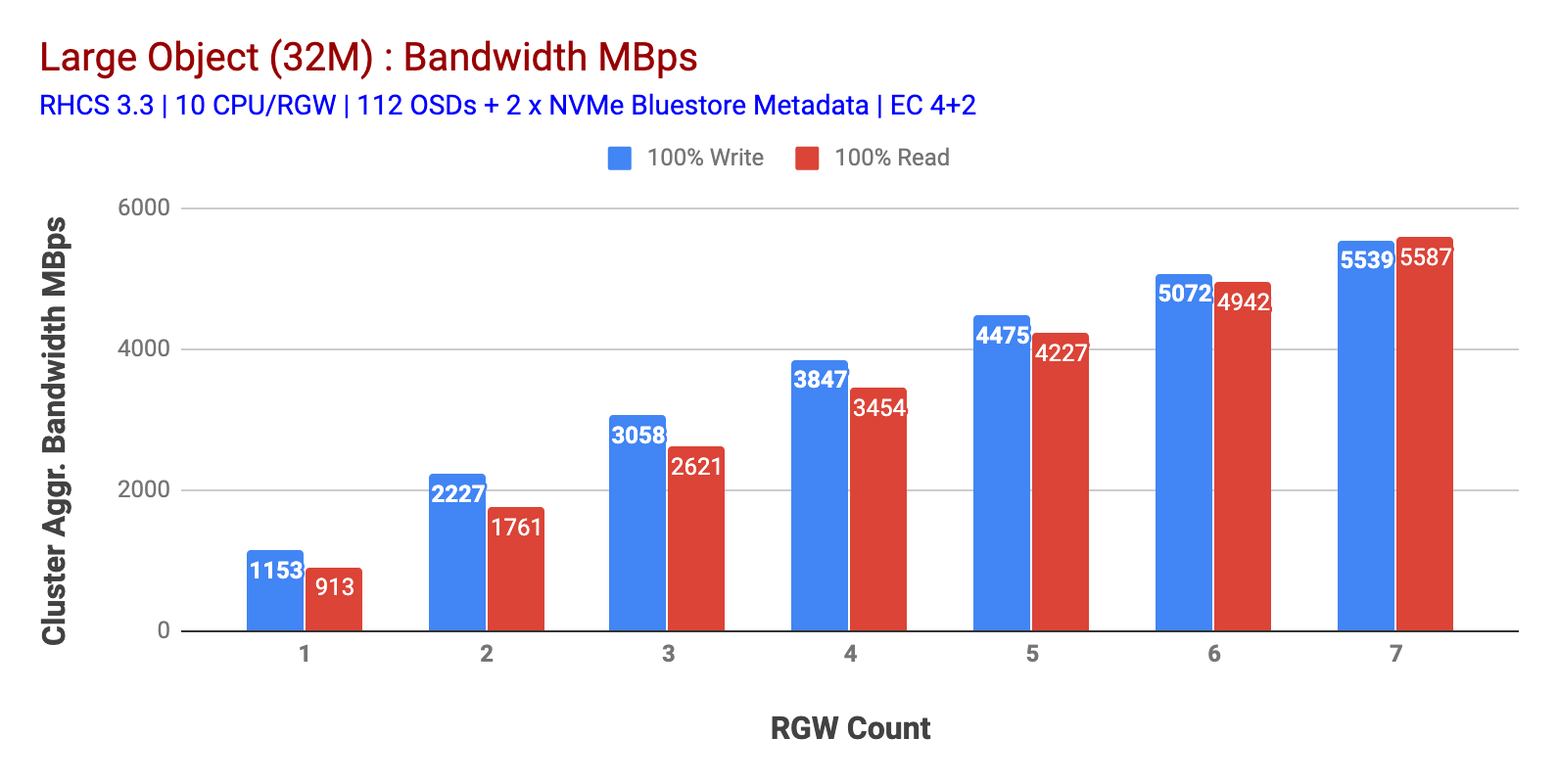
Kaavio 1: Large Object test
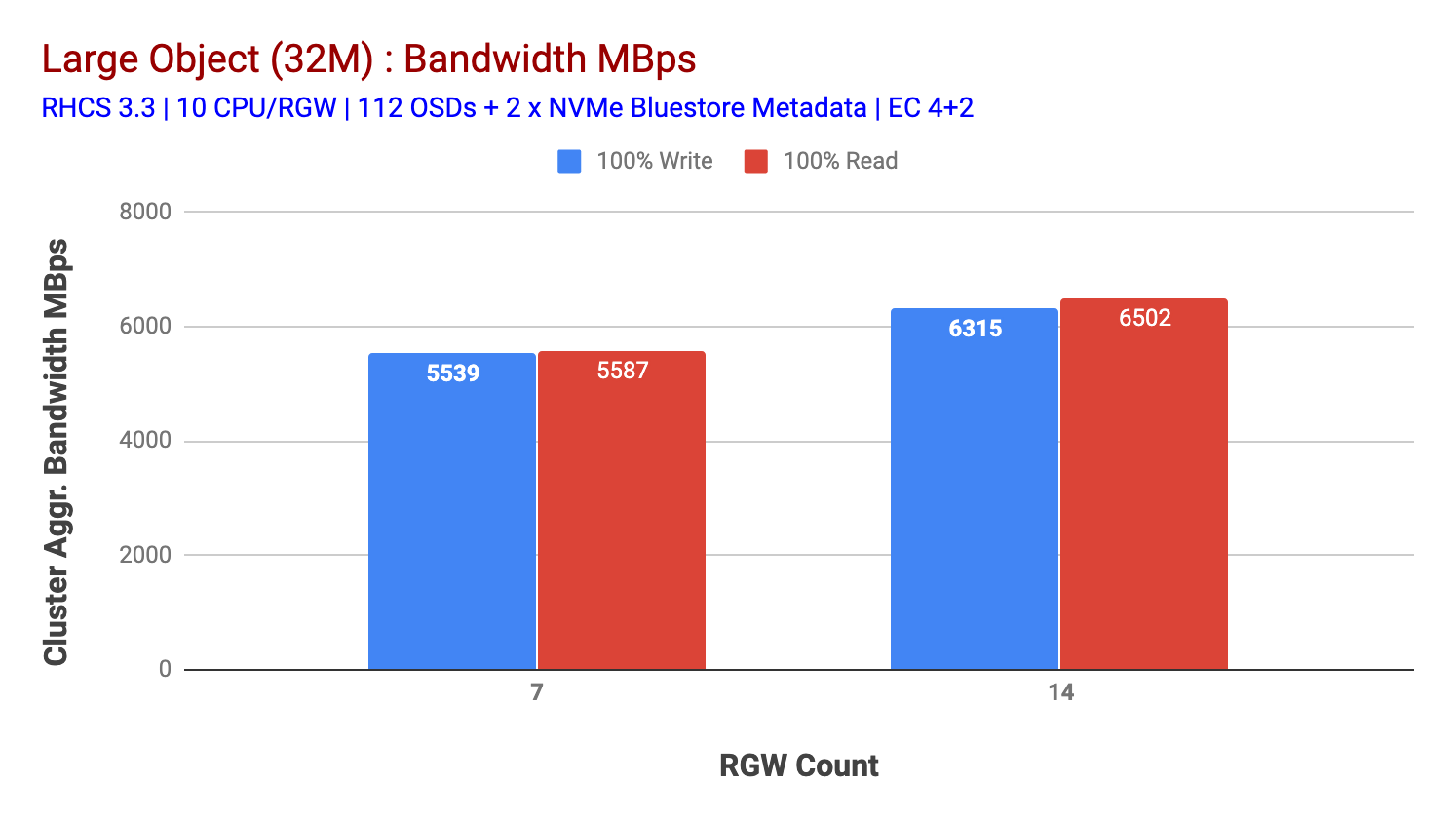
Kaavio 2: Large Object test with 14 RGWs
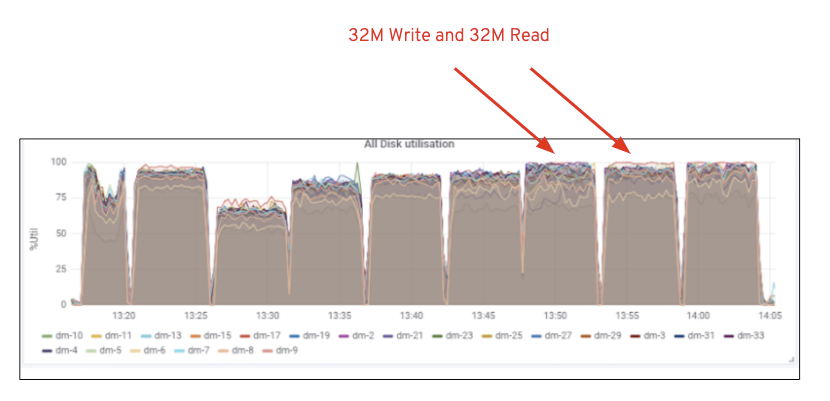
kuva 1: Ceph OSD (HDD) median käyttö
pieni objekti työmäärä
kuten kaaviossa 3 pieni objekti 100% HTTP GET ja HTTP PUT työkuormia näytteillä sub-lineaarinen skaalautuvuus, kun lisätään RGW-isäntien määrää. Sellaisenaan mittasimme ~6.2 K Ops läpimeno HTTP laittaa 9MS sovellus kirjoittaa latenssi ja ~3.2 K Ops HTTP saada työkuormia 7 RGW tapauksissa.
ennen 7 RGW-esiintymää emme huomanneet resurssien kylläisyyttä, joten kaksinkertaistimme RGW-esiintymät skaalaamalla ne 14: ään ja havaitsimme heikentyneen suorituskyvyn HTTP PUT-työmäärälle, joka johtuu median kylläisyydestä, kun taas HTTP GET-suorituskyky skaalattiin ylöspäin ja täydennettiin ~4.5 K Ops: lla. Sellaisenaan, kirjoittaa suorituskyky olisi skaalautunut korkeammalle, jos olisimme lisänneet enemmän Ceph OSD solmut. Mitä tulee lukusuoritukseen, uskomme, että lisäämällä enemmän asiakkaan solmuja olisi pitänyt parantaa sitä, mutta meillä ei ollut enää fyysisiä solmuja laboratoriossa testata tätä hypoteesia.
toinen mielenkiintoinen havainto kaaviosta 3 on HTTP PUT-työkuormien keskimääräinen vasteaika, joka mitattiin 9MS: llä, kun taas HTTP GET osoitti 17ms: n keskimääräisen latenssin mitattuna sovelluksesta, joka tuotti työmäärää. Uskomme, että yksi syy kirjoitustyövoiman yksinumeroiseen sovellusviiveeseen on bluestore OSD-taustaosan sekä bluestore-metatietolaitteen varmuuskopiointiin käytetyn korkean suorituskyvyn Intel Optane NVMe: n suorituskyvyn parantaminen. On syytä huomata, että yhden numeron kirjoitusviiveen saavuttaminen objektin tallennusjärjestelmästä ei ole triviaalia. Kuten kaaviossa 3 on kuvattu, Ceph-objektin tallennustila, kun se on käytössä BlueStore OSD-taustajärjestelmällä ja Intel Optanella metatietoja varten, voi saavuttaa kirjoitustehon pienemmällä vasteajalla.
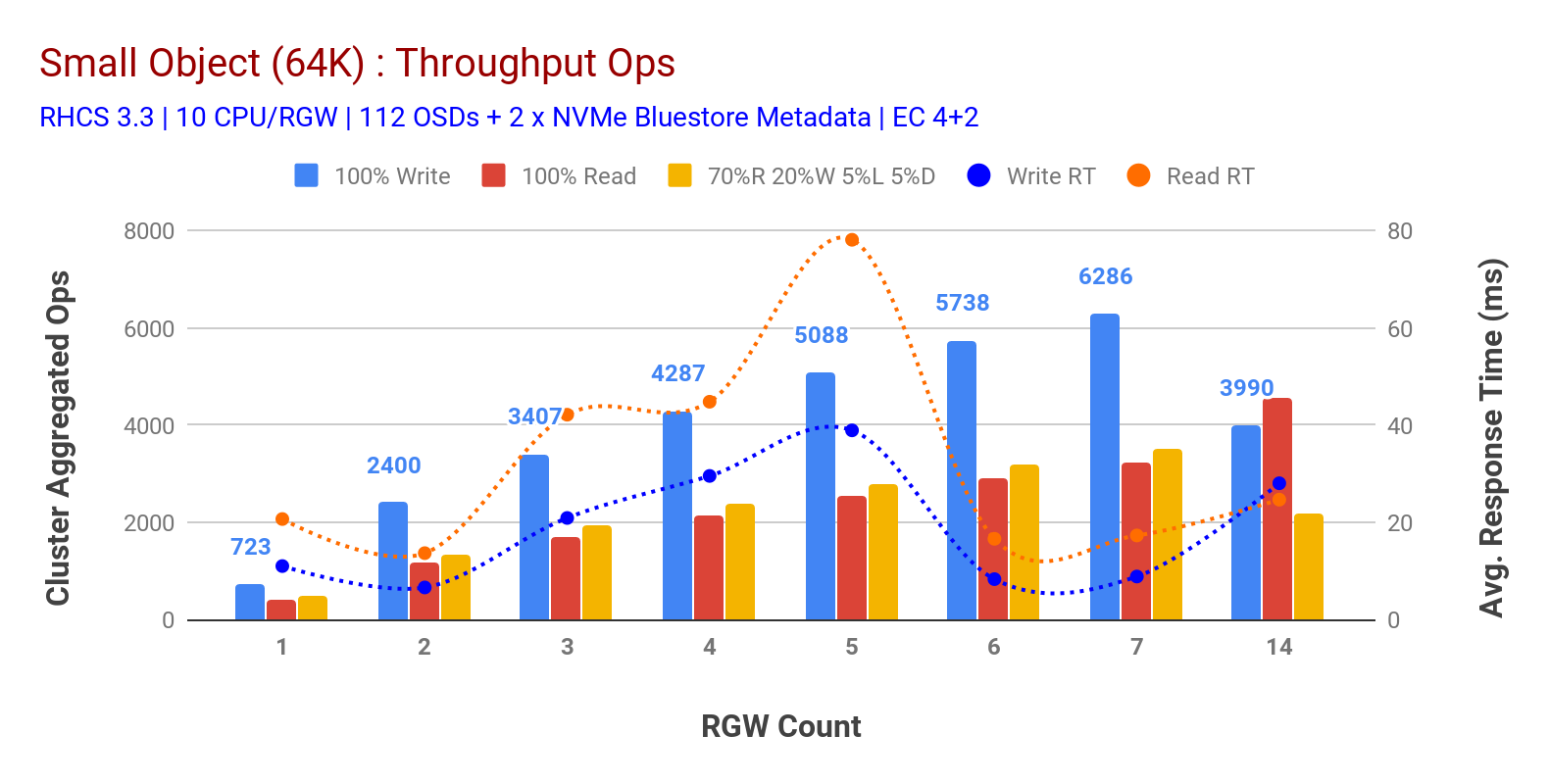
kaavio 3: pienen objektin testi
yhteenveto ja ylös seuraava
tässä testauksessa käytetty kiinteän koon klusteri on antanut ~6,3 GBps: n ja ~6,5 GBps: n suuren objektin kaistanleveyden kirjoitus-ja lukukuormille. Sama klusteri pienille kohteille on toimittanut ~6.5 K Ops ja ~4.5 K Ops kirjoitus-ja lukumäärälle.
tulokset ovat myös osoittaneet, että BlueStore OSD yhdessä Intel Optane NVMe: n kanssa on toimittanut yksinumeroisen keskimääräisen sovellusviiveen, joka ei ole olioiden tallennusjärjestelmille triviaali. Seuraavassa viestissä tutkimme bucket dynamic shardingiin liittyvää suorituskykyä ja sitä, miten Pre-sharding bucket voi auttaa deterministisessä suorituskyvyssä.