
Funcionalidad
A continuación se muestra una lista de las funciones principales de MDF:
-
Búsqueda de estructura química: Las búsquedas de estructura química completas, secundarias, INTELIGENTES, Similares, de fórmula
-
se pueden combinar con búsquedas de propiedades
-
Las búsquedas de estructura química se paginan y almacenan en caché
-
Soporte para compuestos de varios componentes (mezclas)
-
3 entidades de búsqueda de estructura química: Importación y Exportación de archivos SD para las 3 entidades anteriores
-
Acceso transaccional a bases de datos
-
Seguridad opcional (autorización)
Con el diseño y la funcionalidad de MDF es posible construir muchos tipos diferentes de sistemas, como sistemas de registro, sistemas de inventario o simplemente una base de datos compuesta simple. Si bien también puedes crear tu propio ELN, también existe el ELN Índigo gratuito. Este ELN fue creado por GGA Software Services y se utiliza en Pfizer .
A diferencia de MolDB5R y MyMolDB, MDF no es una aplicación web independiente totalmente funcional con búsqueda de estructura química. Como su nombre indica, es un marco para simplificar la creación de dicha aplicación. MDF también se puede utilizar para crear aplicaciones de escritorio locales o cliente-servidor. El MDF está dirigido a desarrolladores de software y no está destinado a ser utilizado por los propios científicos. Sin embargo, las características de MDF son muy robustas. La búsqueda de estructuras químicas se realiza en la base de datos y no en el código de aplicación. Por lo tanto, puede buscar por estructura química y otras propiedades al mismo tiempo, los resultados se pueden ordenar por múltiples propiedades y se pueden paginar (cláusulas de desplazamiento y límite SQL). Tenga en cuenta que si realiza la búsqueda de estructura química en el código de aplicación, cualquier consulta requerirá al menos dos viajes a la base de datos, a saber, la búsqueda de estructura y, posteriormente, el filtrado por otras propiedades, la clasificación y/o la limitación. Ambos deben ocurrir en la misma transacción. No se determinó si MolDB5R y MyMolDB realmente hacen esto en la misma transacción.
En MDF, los compuestos químicos pueden asociarse con un contenedor, que en los sistemas de registro sería un lote o en un sistema de inventario un lote. Una muestra específica físicamente disponible en una botella con código de barras se puede asociar a un recipiente. Estos contenedores también se pueden buscar por estructura química. Esta es la base para crear un sistema de inventario. Los desarrolladores pueden agregar tantas propiedades adicionales como deseen a cada una de las entidades y todas ellas se pueden buscar junto con la estructura química.
Todo el acceso a datos en MDF es transaccional para evitar inconsistencias de datos. MDF se puede configurar para usar un grupo de conexiones de base de datos. Al consultar un RDBMS, la creación de una conexión a menudo toma más tiempo que la consulta en sí y, por lo tanto, si ya tiene conexiones abiertas, los tiempos de respuesta se pueden reducir.
Para la búsqueda de similitud, MDF expuso los algoritmos proporcionados por el cartucho de Bingo, que son las métricas de Tanimoto, Tversky y Euclidiana para subestructuras.
MDF está listo para ser utilizado con seguridad de resorte. La seguridad es opcional. MDF ofrece seguridad a nivel de método (autorización). No ofrece ninguna función de autenticación.
Manejo de mezclas
El MDF admite compuestos químicos multicomponentes. La búsqueda por subestructura devolverá todos los compuestos que tengan al menos un componente (estructura química) que coincida con la estructura de consulta. Esto es importante porque los productos de reacción que se pueden introducir en un sistema de registro químico son casi siempre mezclas a menos que se realice una purificación extensa.
Si una entrada en un archivo SD importado consta de varias estructuras desconectadas, se asume que esta entrada es una mezcla y cada estructura se almacena como una estructura química separada.
Normalización de la estructura
De forma predeterminada, el MDF almacena las estructuras químicas a medida que se envían. El MDF no hace ninguna estandarización/normalización de estructuras químicas. Depende del desarrollador que utiliza MDF asegurarse de que las estructuras químicas se normalicen correctamente antes de guardarlas en la base de datos. Actualmente se sugiere que los desarrolladores implementen tal característica anulando el método preSave () de ChemicalCompoundServiceImpl. Este método se llama antes de que se cree o actualice cualquier compuesto químico. Dentro de este método, el compuesto químico y todas las estructuras químicas en las que se compone pueden manipularse libremente según se desee. Tenga en cuenta que cada compuesto que se guarda se procesará con este método.
Sales, solvatos y soluciones
MDF versión actual 1.0.1 no tiene manipulación especial para sales, solvatos o soluciones. MDF almacenará componentes separados en un archivo de estructura química como una estructura química separada. Por lo tanto, ahorrando una sal como 1 = CC = CC = C1. se representará como una mezcla de los dos iones sin ningún porcentaje establecido. Una búsqueda exacta de la estructura de cualquiera de los iones devolvería esta sal. Si la sal tiene una carga mayor que 1 y múltiples iones asociados a ella como 1 = CC = C = C1.. la sal se almacenará como una mezcla de 1 = CC = C = C1 y sin ningún porcentaje establecido. Si la estructura química es de un solo ion, se almacenará y se podrá buscar como cualquier otra estructura química. Si este comportamiento no es adecuado en un caso específico, los desarrolladores pueden implementar la funcionalidad de manejo de sal y solvato en el método preSave ().
Algunos sistemas comerciales también parecen no tener forma de manejar soluciones. Se recomienda crear el compuesto como si fuera puro y agregar la información de la solución como campos separados en el nivel del compuesto.
Ejemplo de aplicación web
Se creó una aplicación web sencilla que utiliza MDF. La aplicación web hace uso de Spring MVC. La aplicación no hace uso de la integración de seguridad y no utiliza las entidades Containable y ChemicalCompoundContainer. Solo utiliza la entidad de composición química. La aplicación es una base de datos de compuestos para compuestos multicomponentes. Tiene una página para importar las estructuras químicas en un archivo SD en la base de datos compuesta. La base de datos se puede buscar por subestructura y propiedades. Utiliza JSME para dibujar las estructuras químicas (Figura 3). La página de resultados de búsqueda muestra los resultados de búsqueda de forma tabular y paginada. Cuando se realiza una búsqueda de subestructura, la subestructura se resaltará en los resultados de la búsqueda (Figura 4). Los resultados de una búsqueda se pueden exportar como un archivo SD. Los resultados de búsqueda contienen un enlace a una vista compuesta única. Las propiedades del compuesto se pueden editar y las composiciones se pueden agregar, editar y eliminar (Figuras 5, 6). Al editar un compuesto o una composición, la aplicación se ocupa de las modificaciones simultáneas de forma transparente y se muestra un diálogo de resolución de conflictos en el que el usuario puede seleccionar qué valores usar para cada propiedad y luego guardar esa nueva versión.
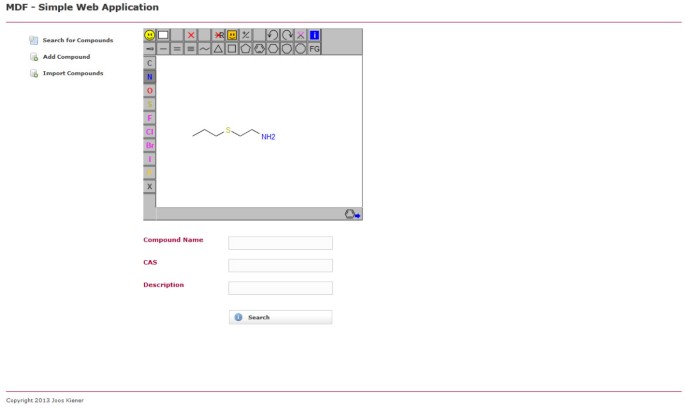
Página de búsqueda de la aplicación web de ejemplo utilizando MDF. Un usuario puede buscar en la base de datos de compuestos por subestructura química y / o propiedades como el nombre del compuesto o el número CAS.

la página de resultados de una búsqueda de la subestructura. Los resultados se muestran en una tabla paginada generada por las tablas de datos del complemento jQuery . Las imágenes de la estructura química tienen la subestructura correspondiente resaltada en rojo. Al hacer clic en la imagen de la estructura química, se mostrarán las SONRISAS.
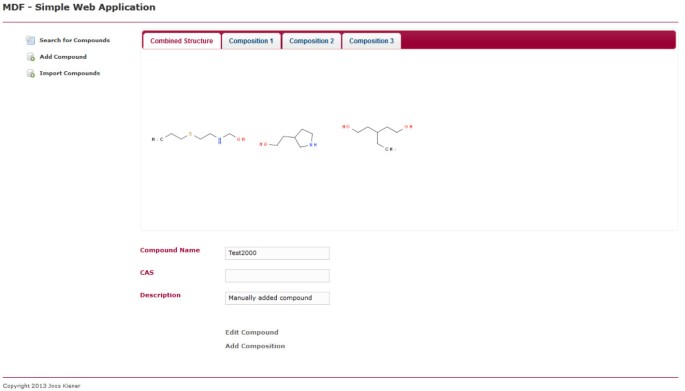
Individuo compuesto de vista. Esta página web muestra un solo compuesto. El compuesto se puede editar o eliminar haciendo clic en el enlace correspondiente dentro de la página. Hay una pestaña que muestra todas las estructuras químicas contenidas y una pestaña para cada composición individual en la que se compone el compuesto.
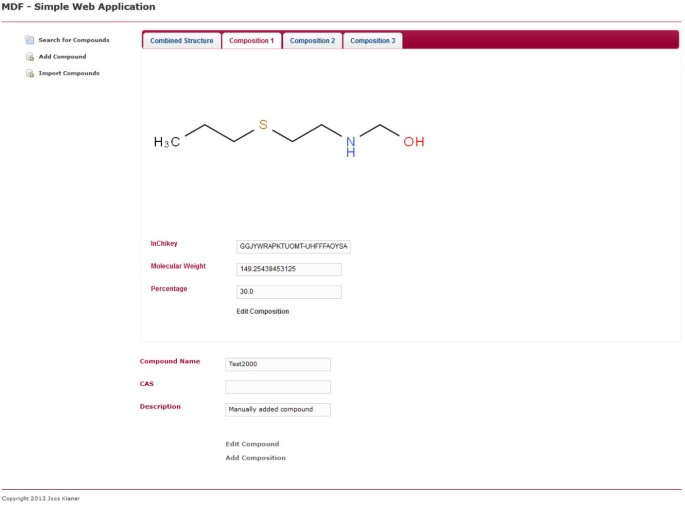
composición Única. Muestra la misma página que la Figura 5, pero en lugar de la pestaña Estructura combinada, se selecciona la pestaña de la primera composición. La composición se puede editar haciendo clic en el enlace correspondiente dentro de la página.
Rendimiento
El MDF tiene un problema de rendimiento principal al manipular mezclas. Si una aplicación utiliza mezclas, es decir, compuestos con varios componentes, una consulta de estructura química devolverá una fila por cada componente de un compuesto que coincida con la consulta. Esto no es deseable porque los usuarios finales desean ver cada compuesto que coincida con la consulta solo una vez. La solución al problema es usar una consulta distinta y aquí es donde ocurre el problema de rendimiento. Si realiza una consulta distinta, se debe buscar en toda la base de datos independientemente de la cláusula límite, lo que aumenta en gran medida el tiempo de ejecución. Tenga en cuenta que la ordenación tiene el mismo efecto. Por lo tanto, la clasificación también puede tener una gran penalización de rendimiento y, al hacer paginación, siempre debe ordenar para obtener un resultado predecible. Para hacer esto aún peor, el cartucho de Bingo para PostgreSQL aún no tiene una implementación adecuada para la estimación de costos y el costo para usar el índice de estructura química está codificado y subestimado. Esto induce a error al planificador de consultas PostgreSQL a usar siempre un análisis de índice completo en el índice de búsqueda de estructura, incluso cuando la consulta tiene una cláusula where adicional que limita en gran medida la cantidad de resultados. En estos casos, por ejemplo, sería más rápido usar el índice para el número CAS y usar la función Bingo matchsub para filtrar. La función matchsub hace coincidir subestructuras sin índice. Esto es, por supuesto, más lento que con un índice, pero si solo se tiene que hacer para un pequeño número de estructuras, es mucho más rápido que el escaneo de índice completo. Para solucionar el problema de estimación de costes, MDF realiza algunos cálculos internos para decidir explícitamente si se utiliza el índice de estructura o la función matchsub. Esto puede mejorar el rendimiento en un orden de magnitud. Tenga en cuenta que el proveedor del cartucho de Bingo es consciente de este problema y el plazo para la corrección era a finales de 2013. Sin embargo, el problema principal de las distintas consultas y la clasificación es inherente a cómo funcionan las bases de datos relacionales y no se puede resolver excepto con un mejor índice de búsqueda de subestructuras o un mejor hardware. MDF también ofrece una configuración para deshabilitar consultas distintas en toda la aplicación para bases de datos compuestas de un solo componente.
Para comparar MDF se utilizó la aplicación web descrita anteriormente. La base de datos contiene 525573 compuestos únicos. Los compuestos son del subconjunto de zinc 13 a pH de referencia 7 los archivos SD 13_p0. 0.sdf, 13_p0. 1.sdf, 13_p0. 10.sdf y 13_p0. 11.sdf. Las estructuras se almacenan en la base de datos como SMILES. Importar cada uno de los archivos SD, que contienen aproximadamente 131.000 estructuras químicas, tomó 12 minutos con el índice de búsqueda de estructuras químicas desactivado. La reconstrucción del índice después de importar todos los archivos SD tomó 22 minutos en un portátil con 4 GB de RAM, CPU Core i5-3220M y un SSD Samsung 830 de 512 GB. Eso equivale a 1 hora y 10 minutos para configurar una base de datos totalmente indexada con medio millón de compuestos. Como referencia adicional, la misma importación se realizó en un PC de escritorio con 12 GB de RAM, i7-875K a 3,4 GHz y la base de datos ejecutándose en una unidad Verde Western Digital (5400 RPM). Aquí la importación tomó 8 minutos y la conclusión es que la importación está limitada a la CPU en lugar de estar limitada por la velocidad de almacenamiento. La generación del índice tomó aproximadamente 22 minutos en el portátil y 20 minutos en el escritorio. La conclusión aquí es que está limitada más por la CPU, pero la velocidad de la unidad también importa. El rendimiento de importación y generación de índices al almacenar las estructuras como archivos molfiles no se comparó.
El rendimiento de búsqueda de subestructuras se comparó con diferentes configuraciones de configuración. La búsqueda de subestructuras es realizada por Bingo PostgreSQL cartridge y, por lo tanto, este punto de referencia refleja su rendimiento más cualquier sobrecarga causada por MDF. Con la excepción de c1ccccc1, el autor dibujó estructuras químicas sin significado específico y probó la velocidad de búsqueda. La velocidad de búsqueda fue determinada por la implementación de logbacks de org.slf4j. perfilador.Perfilador.
El primer punto de referencia es una referencia. Este punto de referencia utilizó la opción para deshabilitar todas las consultas distintas y no se realizó ninguna ordenación. MDF realiza un recuento de las visitas totales en la primera aparición de una búsqueda de estructura química y el recuento se almacena en caché, lo que hace que la primera página se cargue más lento que las páginas posteriores. Cada página contiene 4 registros. Los resultados se muestran en la Tabla 2 ordenados en orden ascendente por número de visitas.
El punto de referencia se repitió, pero esta vez con distintas consultas habilitadas. El tiempo de carga de la primera página se duplica porque se ejecuta la consulta de recuento y luego se ejecuta la consulta real, que tarda aproximadamente la misma cantidad de tiempo que la consulta de recuento debido a la cláusula distinct. La segunda página siempre tarda la mitad del tiempo en cargarse en comparación con la primera página por la misma razón (Tabla 3). El número de visitas es idéntico al de la Tabla 2 porque todos los compuestos de la base de datos consisten en un solo componente.
Los resultados muestran que Bingo no optimiza una consulta de subestructura común como un anillo de benceno y, por lo tanto, busca c1ccccc1 en una base de datos en la que casi todas las moléculas tienen esta característica es muy lenta. Para mejorar la velocidad de búsqueda en este escenario, se recomienda filtrar por propiedades adicionales. Por lo tanto, el punto de referencia se repitió con un filtro adicional de nombre compuesto que comenzaba con «ZINC34».
La tabla 4 muestra el beneficio de la optimización de MDF como solución alternativa al problema de estimación de costos en el cartucho Bingo PostgreSQL. Sin esta optimización, el índice de referencia tendría los mismos resultados que se muestran en el cuadro 3.
MDF también utiliza la funcionalidad de búsqueda de similitud de cartuchos de Bingo. Su rendimiento se probó mediante la búsqueda de compuestos con una puntuación de similitud de 0,9 utilizando la medida de similitud de Tanimoto, también conocida como Índice de Jaccard . Los resultados se muestran en la Tabla 5.
Outlook
Para generar las representaciones de la estructura química se utiliza el kit de herramientas Indigo. El kit de herramientas se puede configurar para generar las estructuras de muchas maneras, incluida la coloración de heteroátomos, la longitud y el ancho de unión y muchas más. Actualmente está codificado y no puede ser ajustado por el usuario. Un siguiente paso sería exponer estas opciones de configuración para que se puedan establecer a través de un archivo de propiedades de Java. También se debe implementar el manejo de sales y solvatos para hacer que el MDF sea utilizable en áreas donde tales compuestos sean importantes.
Para hacer uso de MDF debe ser capaz de programar en Java y necesitará conocimientos básicos sobre Spring framework y cómo configurarlo. Esto limita el público objetivo. Al usar MDF, necesita escribir un código de placa de caldera y, por lo tanto, el siguiente paso sería crear herramientas adicionales para facilitar el uso de MDF, como la generación automática de clases de entidad y sus repositorios y servicios. Estas herramientas tendrían que ser configurables para que un usuario pueda definir las propiedades deseadas para cada una de las entidades y los métodos de búsqueda deseados. Una opción sería un complemento maven. Los complementos Maven pueden generar código como la creación de metamodelos realizada por el complemento QueryDSL-maven. Otra opción serían las anotaciones que generan código en la compilación como lo hace Project Lombok .
El paso final sería crear una plataforma de aplicaciones web que permita a los administradores crear nuevas aplicaciones web con capacidad de búsqueda de estructura química simplemente ingresando las propiedades deseadas para las entidades en un formulario web y haciendo clic en un botón. Es evidente que esto requeriría un importante esfuerzo de desarrollo.