
Hemos probado una variedad de configuraciones, tamaños de objetos y recuentos de trabajadores de clientes para maximizar el rendimiento de un clúster de Ceph de siete nodos para cargas de trabajo de objetos grandes y pequeñas. Como se detalla en la primera publicación, el clúster de Ceph se creó con un solo OSD (Dispositivo de almacenamiento de objetos) configurado por disco duro, con un total de 112 OSD por clúster de Ceph. En esta publicación, entenderemos el rendimiento de primera línea para diferentes tamaños de objetos y cargas de trabajo.
Nota: Los términos «leer» y HTTP GET se usan indistintamente a lo largo de este post, al igual que los términos HTTP PUT y «escribir.»
Carga de trabajo de objetos grandes
Las cargas de trabajo de entrada/salida secuencial (E/S) de objetos grandes son uno de los casos de uso más comunes para el almacenamiento de objetos Ceph. Estas cargas de trabajo de alto rendimiento incluyen análisis de big data, sistemas de copia de seguridad y archivos, almacenamiento de imágenes y transmisión de audio y vídeo. Para estos tipos de cargas de trabajo, el rendimiento (MB/s o GB/s) es la métrica clave que define el rendimiento del almacenamiento.
Como se muestra en el gráfico 1, La carga de trabajo de objetos grandes 100% HTTP GET y HTTP PUT exhibió escalabilidad sub-lineal al aumentar el número de hosts RGW. Como tal, medimos ~5,5 GBps de ancho de banda agregado para cargas de trabajo HTTP GET y HTTP PUT y, curiosamente, no notamos la saturación de recursos en los nodos del clúster de Ceph.
Este clúster puede producir más si podemos dirigirle más carga. Así que identificamos dos formas de hacerlo. 1) Añadir más nodos cliente 2) Añadir más nodos RGW. No pudimos ir con la opción 1, ya que estábamos limitados por los nodos de cliente físicos disponibles en este laboratorio. Así que optamos por la opción 2 y realizamos otra ronda de pruebas, pero esta vez con 14 RGWs.
Como se muestra en el gráfico 2, en comparación con la prueba de 7 RGW, la prueba de 14 RGW produjo un rendimiento de escritura un 14% más alto, superando ~6,3 GBps, de manera similar, la carga de trabajo HTTP GET mostró un rendimiento de lectura un 16% más alto, superando ~6,5 GBps. Este fue el rendimiento agregado máximo observado en este clúster, después del cual se observó saturación de medios (HDD), como se muestra en la Figura 1. En base a los resultados, creemos que si hemos agregado más nodos Ceph OSD a este clúster, el rendimiento podría haberse escalado aún más, hasta que se viera limitado por la saturación de recursos.
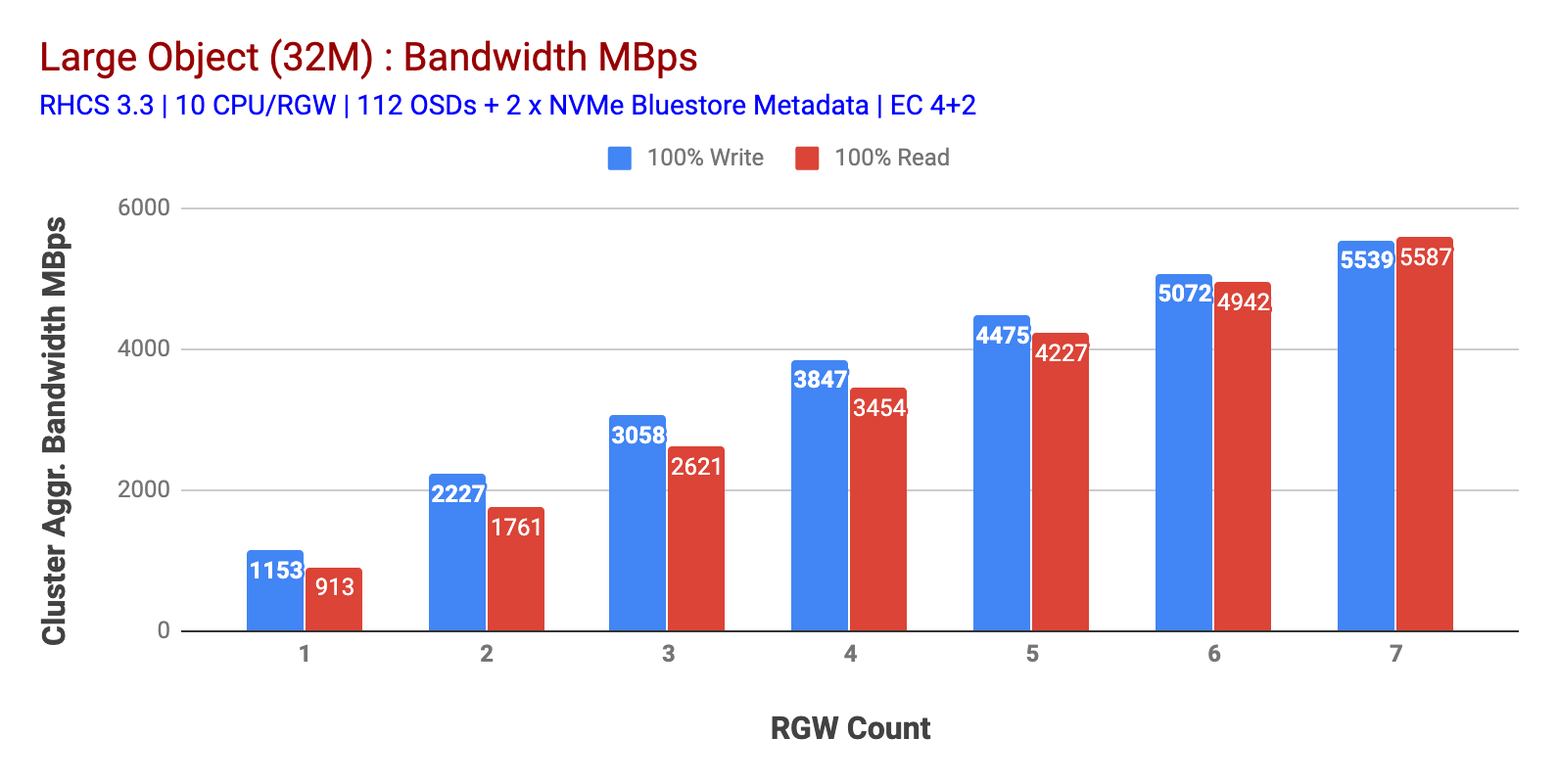
Gráfico 1: Prueba de objetos grandes
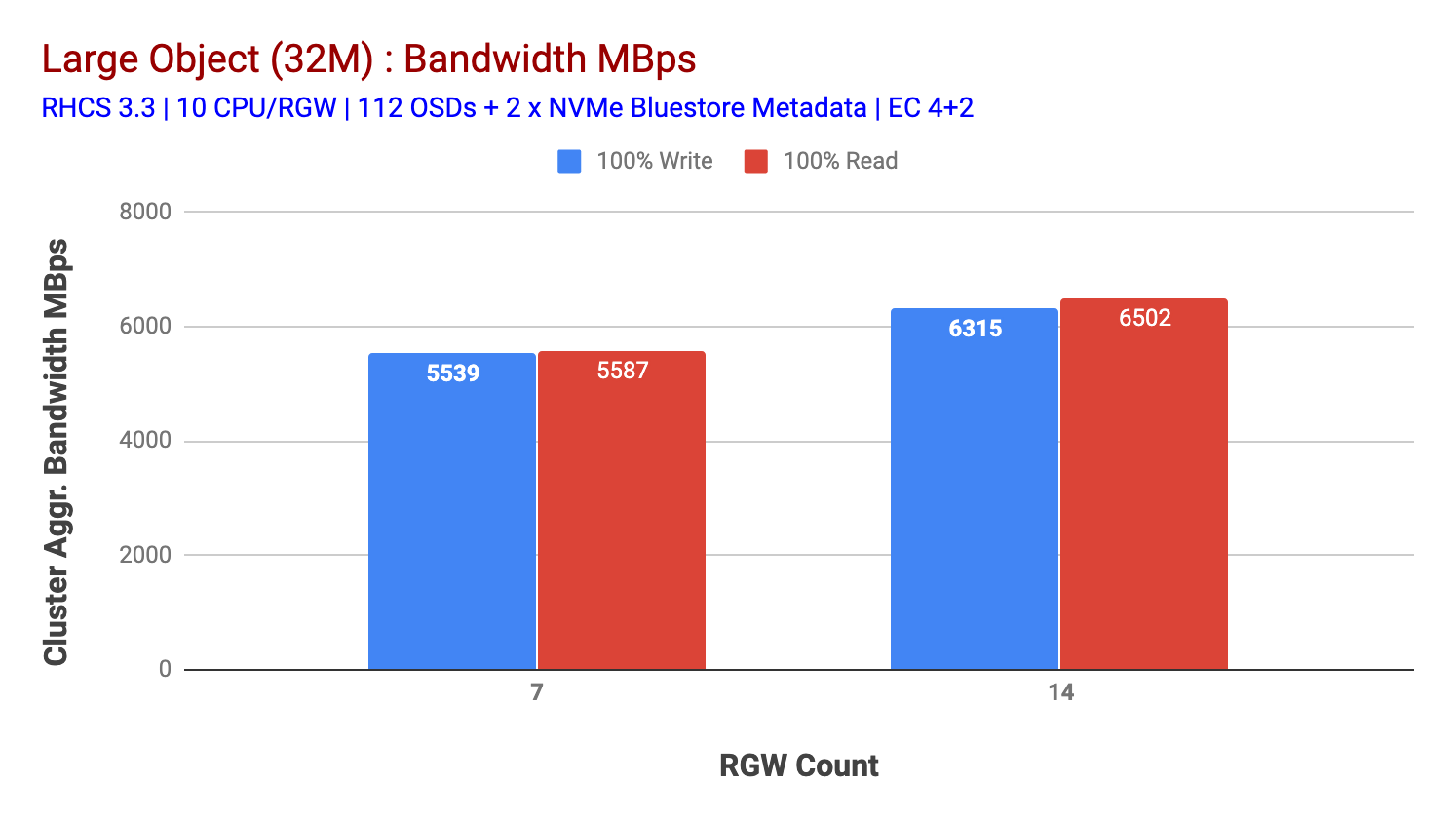
Gráfico 2: Prueba de objetos grandes con 14 RGWs
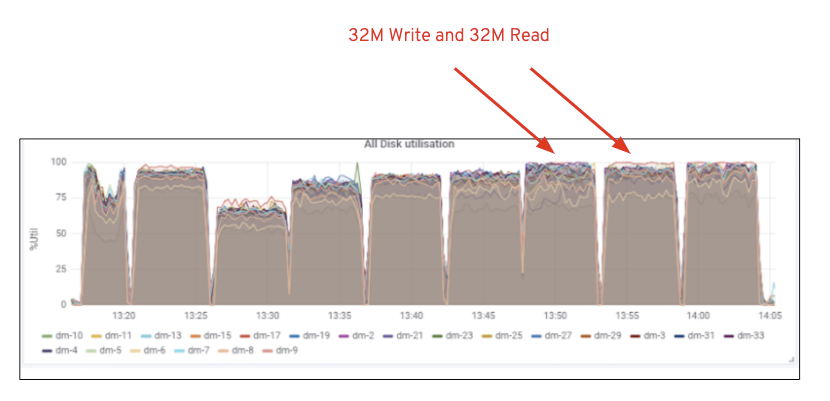
Figura 1: Utilización de medios de Ceph OSD (HDD)
Carga de trabajo de objetos pequeños
Como se muestra en el gráfico 3 las cargas de trabajo de objetos pequeños 100% HTTP GET y HTTP PUT exhibieron escalabilidad sub-lineal al aumentar el número de hosts RGW. Como tal, medimos ~6.2 K de rendimiento Ops para HTTP PUT a 9 ms de latencia de escritura de aplicaciones y ~3.2 K Ops para cargas de trabajo HTTP GET con 7 instancias RGW.
Hasta 7 instancias RGW, no notamos la saturación de recursos, por lo que duplicamos las instancias RGW escalándolas a 14 y observamos un rendimiento degradado para la carga de trabajo HTTP PUT, que se atribuye a la saturación de medios, mientras que el rendimiento HTTP GET se escaló y se superó en ~4.5 K Ops. Como tal, el rendimiento de escritura podría haber aumentado si hubiéramos agregado más nodos Ceph OSD. En lo que respecta al rendimiento de lectura, creemos que agregar más nodos cliente debería haberlo mejorado, pero no teníamos más nodos físicos en el laboratorio para probar esta hipótesis.
Otra observación interesante del gráfico 3 es el tiempo de respuesta promedio reducido para cargas de trabajo HTTP PUT que se midieron a 9 ms, mientras que HTTP GET mostró 17 ms de latencia promedio medida desde la carga de trabajo generadora de la aplicación. Creemos que una de las razones de la latencia de aplicación de un solo dígito para la carga de trabajo de escritura es la combinación de mejoras de rendimiento provenientes del backend OSD de BlueStore, así como del NVMe Intel Optane de alto rendimiento utilizado para respaldar el dispositivo de metadatos de BlueStore. Vale la pena señalar que lograr una latencia promedio de escritura de un solo dígito desde un sistema de almacenamiento de objetos no es trivial. Como se muestra en el gráfico 3, el almacenamiento de objetos Ceph, cuando se implementa con el backend OSD de BlueStore y Intel Optane para metadatos, puede lograr el rendimiento de escritura en un tiempo de respuesta más bajo.
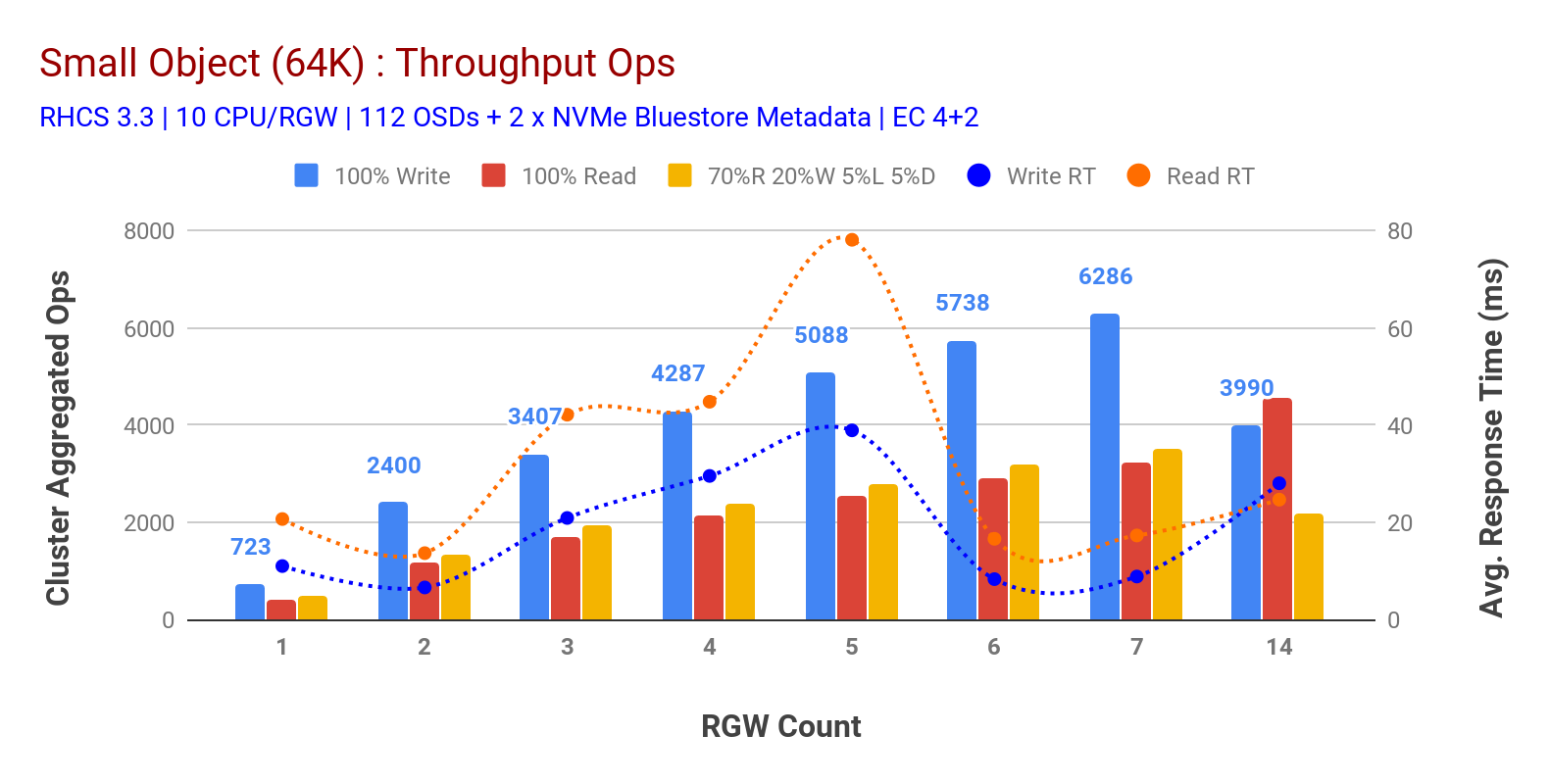
Gráfico 3: Prueba de objetos pequeños
Resumen y siguiente
El clúster de tamaño fijo utilizado en esta prueba ha proporcionado un ancho de banda de objetos de ~6,3 GBps y ~6,5 GBps para cargas de trabajo de escritura y lectura, respectivamente. El mismo clúster para objetos de tamaño pequeño ha entregado ~6,5 K Ops y ~4,5 K Ops para cargas de trabajo de escritura y lectura, respectivamente.
Los resultados también han demostrado que BlueStore OSD en combinación con Intel Optane NVMe ha proporcionado una latencia media de aplicaciones de un solo dígito, que no es trivial para los sistemas de almacenamiento de objetos. En la siguiente publicación, exploraremos el rendimiento asociado con el sharding dinámico de cubo y cómo el cubo pre-sharding puede ayudar en el rendimiento determinista.