
Vi har testet en række konfigurationer, objektstørrelser og klient arbejdstager tæller for at maksimere gennemstrømningen af en syv node Ceph klynge for små og store objekt arbejdsbyrder. Som beskrevet i det første indlæg blev Ceph-klyngen bygget ved hjælp af en enkelt OSD (Object Storage Device) konfigureret pr. I dette indlæg vil vi forstå toplinjens ydeevne for forskellige objektstørrelser og arbejdsbelastninger.
Bemærk: Udtrykkene ” Læs “og HTTP GET bruges ombytteligt i hele dette indlæg, ligesom udtrykkene HTTP PUT og” skriv.”
arbejdsbyrde med stort objekt
arbejdsbelastninger med stort objekt sekventiel input/output (I / O) er en af de mest almindelige brugssager til Ceph-objektlagring. Disse arbejdsbelastninger med høj kapacitet inkluderer big data analytics, backup og arkivsystemer, billedlagring og streaming af lyd og video. For disse typer arbejdsbelastninger er gennemstrømning (MB/s eller GB / s) den nøglemetrik, der definerer lagringsydelse.
som vist i Figur 1 storobjekt 100% HTTP GET og HTTP PUT arbejdsbyrde udviste sub-lineær skalerbarhed, når antallet af RGV-værter øges. Som sådan målte vi ~5.5 GBps aggregeret båndbredde til HTTP GET og HTTP satte arbejdsbyrder, og interessant nok bemærkede vi ikke ressourcemætning i Ceph-klyngenoder.
denne klynge kan churn ud mere, hvis vi kan lede mere belastning til det. Så vi identificerede to måder at gøre det på. 1) Tilføj flere klientnoder 2) Tilføj flere knudepunkter. Vi kunne ikke gå med mulighed 1, da vi var begrænset af de fysiske klientnoder, der var tilgængelige i dette laboratorium. Så vi valgte mulighed 2 og kørte endnu en testrunde, men denne gang med 14 kg.
som vist i figur 2, sammenlignet med 7-testen, gav 14-testen en 14% højere skriveydelse, topping ved ~6,3 GBps, på samme måde viste HTTP GET-arbejdsbyrden 16% højere læseydelse, topping ~6,5 GBps. Dette var den maksimale aggregerede gennemstrømning, der blev observeret på denne klynge, hvorefter mediemætning (HDD) blev bemærket som afbildet i Figur 1. Baseret på resultaterne mener vi, at har vi tilføjet flere Ceph OSD-noder til denne klynge, kunne ydeevnen have været skaleret endnu længere, indtil den var begrænset af ressourcemætning.
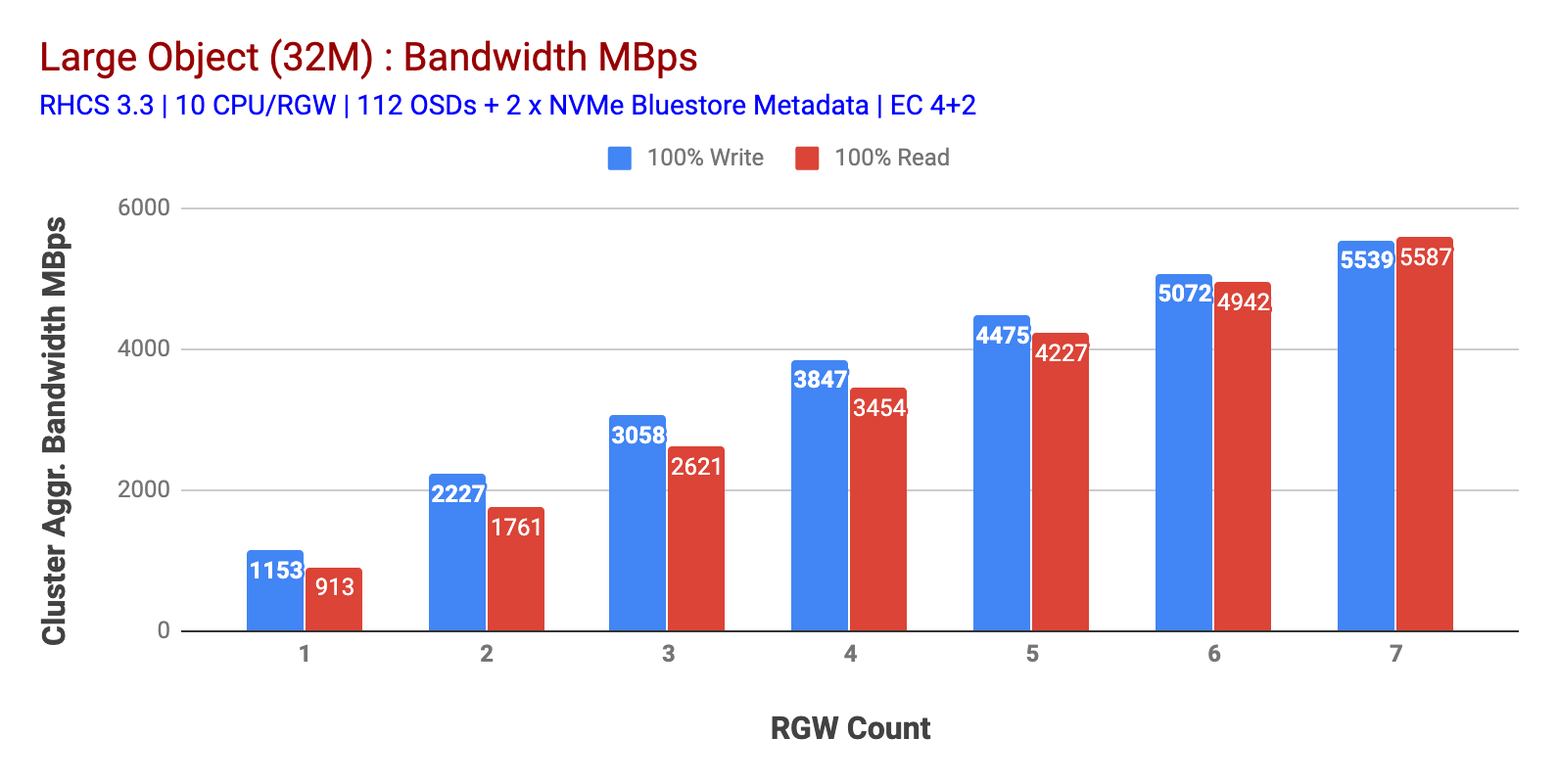
diagram 1: stor Objekttest
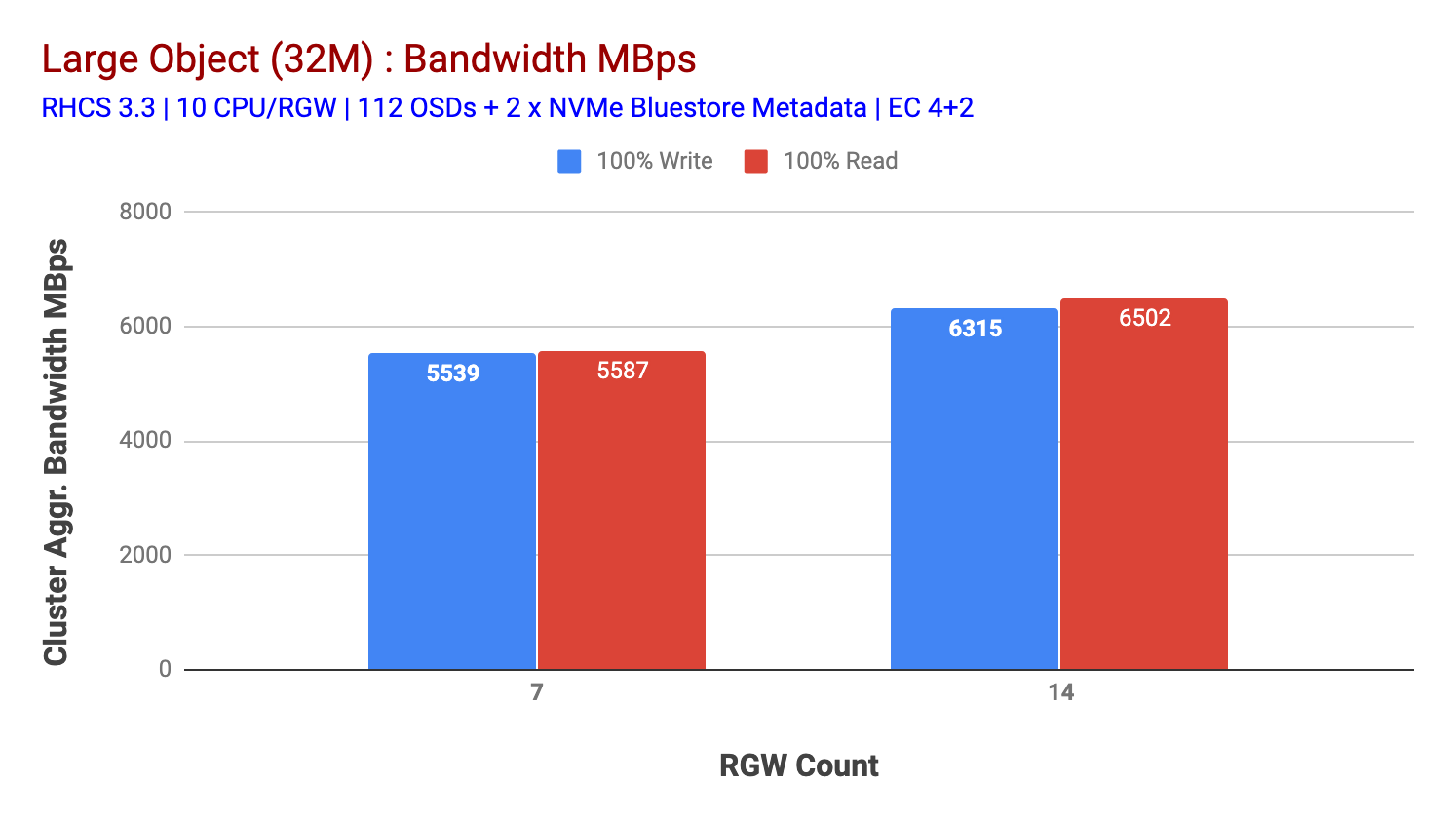
diagram 2: stor Objekttest med 14 omdrejninger
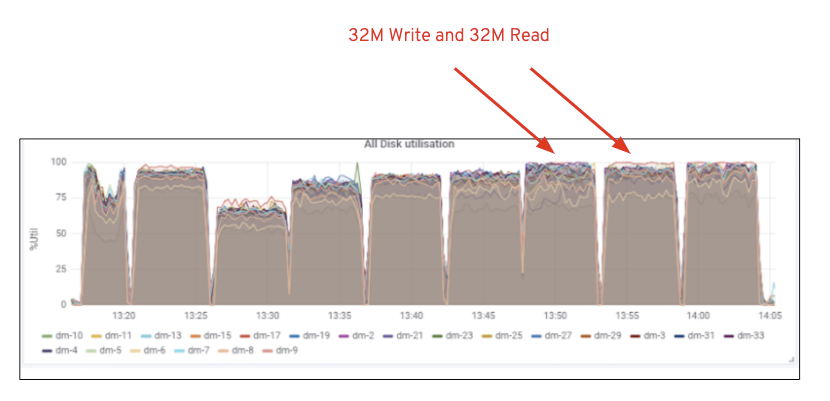 figur 1: Ceph OSD (HDD) medieudnyttelse
figur 1: Ceph OSD (HDD) medieudnyttelsefigur 1: Ceph OSD (HDD) medieudnyttelse
lille objekt arbejdsbyrde
som vist i figur 3 lille objekt 100% HTTP GET og HTTP PUT arbejdsbyrder udviste sub-lineær skalerbarhed, når antallet af RGV-værter øges. Som sådan målte vi ~6.2 K Ops gennemstrømning for HTTP sat på 9MS ansøgning skrive latenstid og ~3.2 K Ops for HTTP få arbejdsbyrder med 7 RGV forekomster.
indtil 7 RGV-forekomster bemærkede vi ikke ressourcemætning, så vi fordoblede RGV-forekomster ved at skalere dem til 14 og observerede forringet ydeevne for HTTP sætte arbejdsbyrde, der tilskrives mediemætning, mens HTTP får ydeevne skaleret op og toppet ved ~4,5 K Ops. Som sådan kunne skrivepræstation have skaleret højere, hvis vi havde tilføjet flere Ceph OSD-noder. Hvad angår læsepræstation, mener vi, at tilføjelse af flere klientnoder burde have forbedret det, men vi havde ikke flere fysiske noder i laboratoriet til at teste denne hypotese.
en anden interessant observation fra Figur 3 er den reducerede gennemsnitlige responstid for HTTP PUT-arbejdsbelastninger, der måles ved 9ms, mens HTTP GET viste 17ms gennemsnitlig latenstid målt fra applikationen, der genererer arbejdsbyrde. Vi mener, at en af grundene til encifret applikationsforsinkelse for skrivebelastning er kombinationen af ydelsesforbedring, der kommer fra BlueStore OSD-backend såvel som den højtydende Intel Optane NVMe, der bruges til at bakke BlueStore-metadataenhed. Det er værd at bemærke, at det ikke er trivielt at opnå encifret skrive gennemsnitlig latenstid fra et Objektlagringssystem. Som afbildet i figur 3 kan Ceph-objektlagring, når den implementeres med BlueStore OSD-backend og Intel Optane for metadata, opnå skrivegennemstrømning ved lavere responstid.
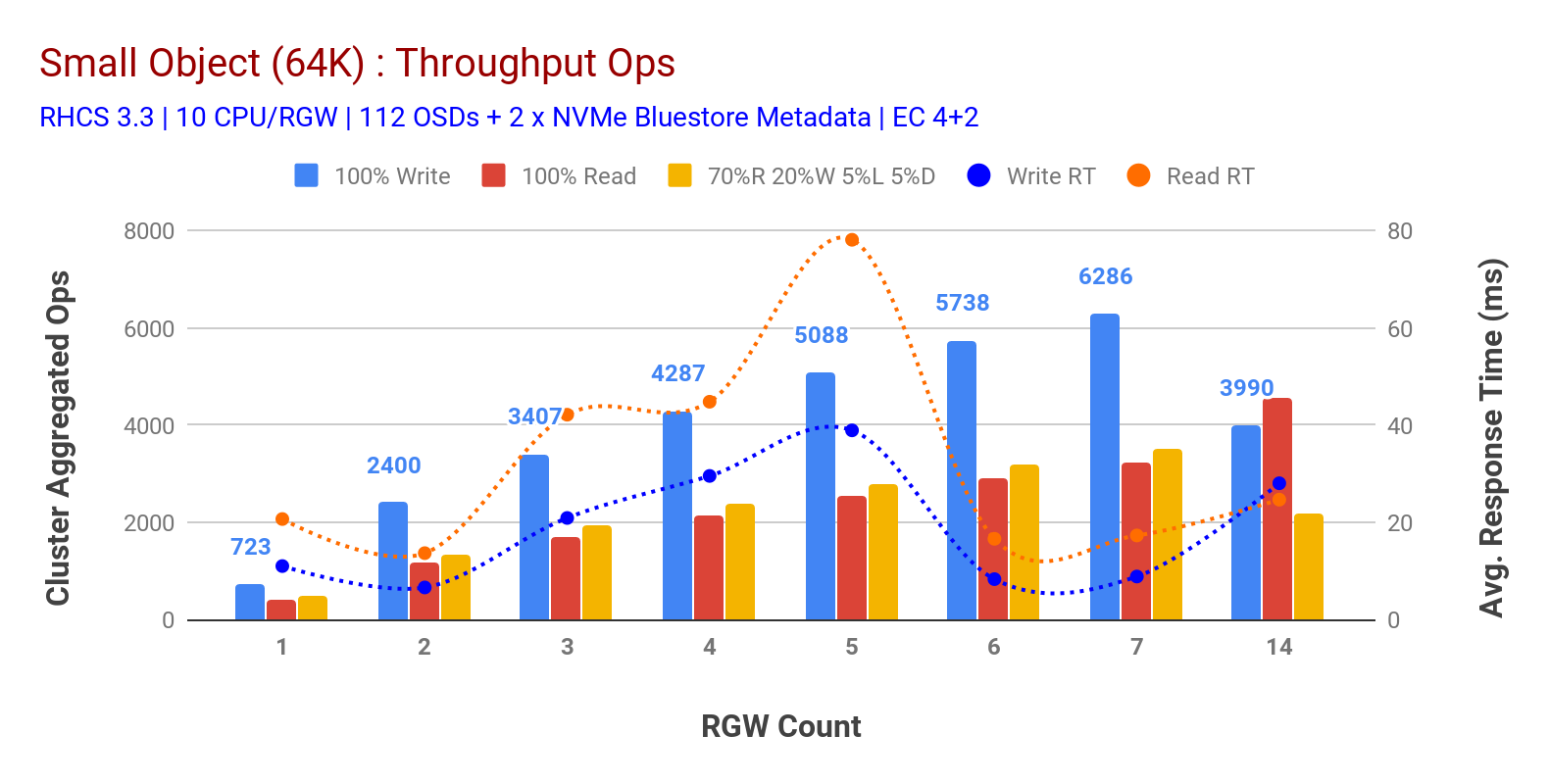
diagram 3: Lille Objekttest
Oversigt og op næste
den faste størrelse klynge, der anvendes i denne test, har leveret ~6,3 GBps og ~6,5 GBps stor objektbåndbredde til henholdsvis skrive og læse arbejdsbelastninger. Den samme klynge for lille objektstørrelse har leveret ~6,5 K Ops og ~4,5 K Ops til henholdsvis skrive-og læsebelastning.
resultaterne har også vist, at BlueStore OSD i kombination med Intel Optane NVMe har leveret encifret gennemsnitlig applikationslatenstid, hvilket ikke er trivielt for objektlagringssystemer. I det næste indlæg vil vi undersøge præstationen forbundet med bucket dynamic sharding og hvordan pre-sharding bucket kan hjælpe med deterministisk ydeevne.