
Funkce
Níže je uveden seznam základní funkce MDF:
-
Chemické struktury hledat: Plné, Sub, CHYTROSTI, Podobnost, Vzorec,
-
Chemická struktura vyhledávání lze kombinovat s vlastností hledání
-
Chemická struktura vyhledávání jsou stránkované a mezipaměti
-
Podpora pro multi-jednotlivých sloučenin (směsí)
-
3 chemická struktura vyhledávat subjekty: ChemicalCompound, Ovládnutelné a ChemicalCompoundContainer
-
Import a Export na SD-Soubory pro výše 3 subjekty,
-
Transakční přístup k databázi
-
Volitelné zabezpečení (autorizace)
design a funkčnost MDF je možné vytvořit mnoho různých typů systému, jako jsou registrační systémy, skladové systémy, nebo jen jednoduchá sloučenina databáze. I když si můžete také vytvořit svůj vlastní ELN, existuje také volný Indigo ELN. Tento ELN byl vytvořen společností GGA Software Services a používá se ve společnosti Pfizer .
na rozdíl od MolDB5R a MyMolDB , MDF není plně funkční samostatná webová aplikace s chemickou strukturu hledání. Jak název napovídá, je to rámec pro zjednodušení vytváření takové aplikace. MDF mohou být také použity k vytvoření místní nebo klient-server desktopové aplikace. MDF je zaměřen na vývojáře softwaru a není určen pro použití samotnými vědci. Nicméně MDF funkce jsou velmi robustní. Hledání chemické struktury se provádí v databázi, nikoli v kódu aplikace. Proto můžete vyhledávat podle chemické struktury a dalších vlastností současně, výsledky mohou být tříděny podle více vlastností a mohou být stránkovány (SQL OFFSET a LIMIT klauzule). Všimněte si, že pokud budete dělat chemická struktura vyhledávání v kódu aplikace, jakýkoliv dotaz, bude vyžadovat alespoň dva výlety do databáze, a to konstrukce vyhledávání a následně filtrování podle dalších vlastností, třídění a/nebo omezení. Oba se musí stát ve stejné transakci. Nebylo určeno, zda to MolDB5R a MyMolDB skutečně dělají ve stejné transakci.
v MDF mohou být chemické sloučeniny spojeny s kontejnerem, který by v registračních systémech byl dávkou nebo v inventárním systému hodně. Specifický fyzicky dostupný vzorek v čárově kódované láhvi pak může být spojen s nádobou. Tyto kontejnery lze také vyhledávat podle chemické struktury. To je základ pro vytvoření inventárního systému. Vývojáři mohou ke každé entitě přidat tolik dalších vlastností, kolik chtějí, a všechny z nich lze prohledávat společně s chemickou strukturou.
veškerý přístup k datům v MDF je transakční, aby se zabránilo nekonzistencím dat. MDF lze nakonfigurovat tak, aby používal fond připojení k databázi. Při dotazování na RDBMS vytvoření připojení často trvá déle než samotný dotaz, a proto, pokud již máte otevřené připojení, lze zkrátit dobu odezvy.
pro vyhledávání podobnosti MDF odhalil algoritmy poskytované Bingo kazety, které jsou Tanimoto, Tversky a euklidovská metrika pro substruktury.
MDF je připraven k použití s pružinovým zabezpečením. Bezpečnost je volitelná. MDF nabízí úroveň zabezpečení metody (autorizace). Nenabízí žádné ověřovací funkce.
manipulace se směsí
MDF podporuje vícesložkové chemické sloučeniny. Vyhledávání podle spodní struktury vrátí všechny sloučeniny, které mají alespoň jednu složku (chemickou strukturu) odpovídající struktuře dotazu. To je důležité, protože reakční produkty, které mohou být zapsány do systému chemické registrace, jsou téměř vždy směsi, pokud není provedeno rozsáhlé čištění.
Pokud je položka v importovaném SD-Soubor se skládá z více odpojené struktury, předpokládá se, že tato položka je směs a každá struktura je uložen jako samostatný chemické struktury.
normalizace struktury
ve výchozím nastavení MDF ukládá chemické struktury tak, jak jsou předloženy. MDF NEPROVÁDÍ žádnou standardizaci / normalizaci chemických struktur. Je na vývojáři, který používá MDF, aby zajistil, že chemické struktury jsou správně normalizovány před jejich uložením do databáze. V současné době se navrhuje, aby vývojáři implementovali takovou funkci přepsáním metody preSave () ChemicalCompoundServiceImpl. Tato metoda se nazývá před vytvořením nebo aktualizací jakékoli chemické sloučeniny. V rámci této metody lze chemickou sloučeninu a všechny chemické struktury, z nichž se skládá, volně manipulovat podle potřeby. Všimněte si, že každá uložená sloučenina bude zpracována touto metodou.
soli, solváty a roztoky
MDF aktuální verze 1.0.1 nemá žádné zvláštní zacházení pro soli, solváty nebo roztoky. MDF uloží samostatné komponenty do souboru chemické struktury jako samostatnou chemickou strukturu. Proto šetří sůl jako 1 = CC = CC = C1. bude reprezentován jako směs dvou iontů bez nastavených procent. Přesné hledání struktury obou iontů by tuto sůl vrátilo. Pokud má sůl náboj větší než 1 a více iontů s ní spojených jako 1 = CC = C = C1.. sůl bude skladována jako směs 1 = CC = C = C1 a bez nastavení procent. Pokud je chemická struktura jediným iontem, bude uložena a prohledávatelná jako každá jiná chemická struktura. Pokud je toto chování v konkrétním případě nevhodné, mohou vývojáři implementovat funkci salt and solvate handling v metodě preSave ().
zdá se, že některé komerční systémy také nemají způsob řešení. Doporučuje se vytvořit sloučeninu, jako by byla čistá, a přidat informace o roztoku jako samostatná pole na úrovni sloučeniny.
příklad webové aplikace
byla vytvořena jednoduchá webová aplikace využívající MDF. Webová aplikace využívá pružinové MVC. Aplikace nevyužívá integraci zabezpečení a nepoužívá entity Containable a ChemicalCompoundContainer. Používá pouze chemickou sloučeninu. Aplikace je složená databáze pro vícesložkové sloučeniny. Má stránku pro import chemických struktur v SD souboru do složené databáze. Databázi lze vyhledávat podle spodní struktury a vlastností. Používá JSME pro kreslení chemických struktur (obrázek 3). Stránka s výsledky vyhledávání zobrazuje vyhledávací hity v tabulkovém a stránkovaném módu. Když je provedeno vyhledávání spodní konstrukce, spodní konstrukce bude zvýrazněna ve výsledcích vyhledávání (obrázek 4). Hity vyhledávání lze exportovat jako SD-soubor. Výsledky vyhledávání obsahují odkaz na jeden složený pohled. Vlastnosti sloučeniny lze upravovat a kompozice lze přidávat, upravovat a mazat (obrázky 5, 6). Při úpravě sloučeniny nebo kompozice aplikace se zabývá souběžné změny transparentně a řešení konfliktů, zobrazí se dialog, na kterém uživatel může vybrat, které hodnoty chcete použít pro každou vlastnost a pak uložit, že nová verze.
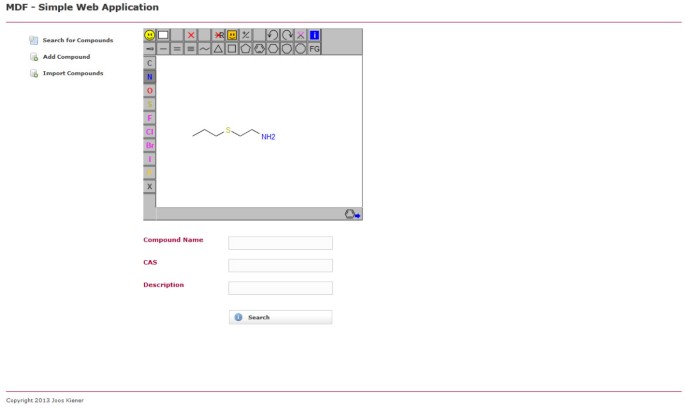
stránka Vyhledávání pro příklad webové aplikace pomocí MDF. Uživatel může prohledávat databázi sloučenin podle chemické spodní struktury a / nebo vlastností, jako je název sloučeniny nebo číslo CAS.

Výsledek stránku spodku vyhledávání. Výsledky jsou zobrazeny v stránkované tabulce generované jQuery plugin datatables . Obrázky chemické struktury mají odpovídající spodní konstrukci zvýrazněnou červeně. Kliknutím na obrázek chemické struktury se zobrazí úsměvy.
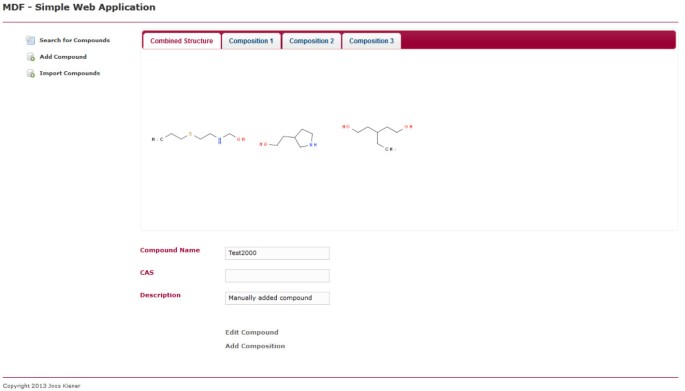
Individuální složené zobrazení. Tato webová stránka zobrazuje jednu sloučeninu. Sloučenina může být upravena nebo odstraněna kliknutím na odkaz podle stránky. K dispozici je karta zobrazující všechny obsažené chemické struktury a karta pro každou jednotlivou kompozici, ze které se sloučenina skládá.
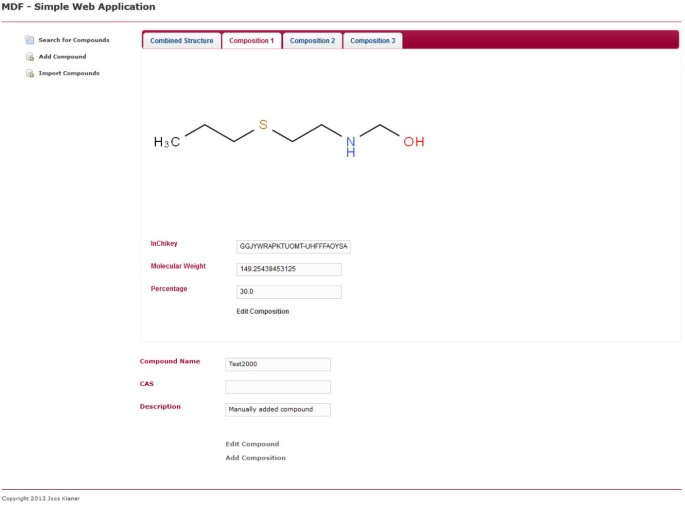
jednom složení. Zobrazuje stejnou stránku jako obrázek 5, ale místo karty kombinovaná struktura je vybrána karta první kompozice. Kompozici lze upravit kliknutím na odkaz podle stránky.
výkon
MDF má jeden hlavní problém s výkonem při manipulaci se směsmi. Pokud aplikace používá směsi, tj. sloučeniny s více složkami, dotaz na chemickou strukturu vrátí jeden řádek pro každou složku ve sloučenině odpovídající dotazu. To je nežádoucí, protože koncoví uživatelé chtějí vidět každou sloučeninu, která odpovídá dotazu pouze jednou. Řešením problému je použití odlišného dotazu a zde dochází k problému s výkonem. Pokud provedete odlišný dotaz, je třeba prohledat celou databázi bez ohledu na klauzuli limit, což výrazně prodlužuje dobu provádění. Všimněte si, že třídění má stejný účinek. Takže třídění může mít také obrovský výkonnostní trest a při stránkování byste měli vždy třídit, abyste získali předvídatelný výsledek. Aby to bylo ještě horší, bingo Cartridge pro PostgreSQL ještě nemá správnou implementaci pro odhad nákladů a náklady na použití indexu chemické struktury jsou pevně kódovány a podceňovány. To uvádí v omyl PostgreSQL dotaz planer vždy použít Úplné skenování indexu na struktuře vyhledávací index, i když má dotaz další klauzuli where, která výrazně omezuje množství výsledků. V těchto případech by bylo například rychlejší použít index pro číslo CAS a použít funkci Bingo matchsub pro filtrování. Funkce matchsub provádí shodu podstruktury bez indexu. To je samozřejmě pomalejší než u indexu, ale pokud to musí být provedeno pouze pro malý počet struktur, je to mnohem rychlejší než úplné skenování indexu. Chcete-li vyřešit problém s odhadem nákladů, MDF provádí některé interní výpočty, aby výslovně rozhodl, zda je použit index struktury nebo funkce matchsub. To může zlepšit výkon řádově. Všimněte si, že dodavatel Bingo kazety je si vědom tohoto problému a časová osa pro opravu byl konec 2013. Hlavní problém odlišných dotazů a třídění je však neodmyslitelný v tom, jak relační databáze fungují, a nelze je vyřešit s výjimkou lepšího indexu vyhledávání podstruktury nebo lepšího hardwaru. MDF také nabízí nastavení pro zakázání různých dotazů v celé aplikaci pro jednosložkové složené databáze.
pro benchmark MDF byla použita dříve popsaná webová aplikace. Databáze obsahuje 525573 unikátních sloučenin. Sloučeniny jsou z podmnožiny zinku 13 Při referenčním pH 7 SD-files 13_p0. 0.sdf, 13_p0.1.sdf, 13_p0.10.sdf a 13_p0.11.sdf. Struktury jsou uloženy v databázi jako úsměvy. Import každé z SD-soubory, které obsahují přibližně 131’000 chemických struktur, trvalo 12 min s chemickou strukturu index vyhledávání zakázáno. Přestavba indexu po importu všech SD souborů trvala 22 minut na notebooku s 4 GB RAM, Core i5-3220M CPU a 512GB Samsung 830 SSD. To činí 1 h 10 min pro nastavení plně indexované databáze s půl milionem sloučenin. Jako další odkaz byl stejný import proveden na stolním počítači s 12 GB RAM, i7-875K @ 3.4 GHz a databází běžící na Zelené jednotce Western Digital (5400 ot / min). Zde import trval 8 min a závěr je, že import je CPU omezen spíše než omezen rychlostí úložiště. Generování indexu trvalo přibližně 22 minut na notebooku a 20 minut na ploše. Závěr je, že je omezen více CPU, ale záleží také na rychlosti pohonu. Výkon importu a generování indexů při ukládání struktur jako molfiles nebyl srovnáván.
výkon vyhledávání spodní konstrukce byl porovnán s různými konfiguračními nastaveními. Hledání substruktury se provádí pomocí Bingo PostgreSQL cartridge a tento benchmark proto odráží jeho výkon plus veškeré režijní náklady způsobené MDF. S výjimkou c1ccccc1 autor kreslil chemické struktury bez specifického významu a testoval rychlost vyhledávání. Rychlost vyhledávání byla určena implementací logbacků org.slf4j.profiler.Profilování.
první benchmark je reference. Tento benchmark použil možnost zakázat všechny odlišné dotazy a nebylo provedeno žádné třídění. MDF provádí počet celkových zásahů při prvním výskytu vyhledávání chemické struktury a počet je uložen do mezipaměti, což způsobí, že se první stránka načítá pomaleji než následující stránky. Každá stránka obsahuje 4 záznamy. Výsledky jsou uvedeny v tabulce 2 seřazené vzestupně podle počtu zásahů.
benchmark byl opakován, ale tentokrát s odlišnými dotazy povoleno. Doba načítání první stránky se zdvojnásobí, protože je spuštěn dotaz počtu a poté je spuštěn skutečný dotaz, který trvá přibližně stejně dlouho jako dotaz počtu kvůli odlišné klauzuli. Druhá stránka pak vždy trvá polovinu času na načtení ve srovnání s první stránkou ze stejného důvodu (Tabulka 3). Počet zásahů je shodný s počtem zásahů v tabulce 2, protože všechny sloučeniny v databázi sestávají pouze z jedné složky.
výsledky ukazují, že Bingo nemá žádné optimalizace pro společné spodku dotaz jako benzenový kruh, a tudíž vyhledávání pro c1ccccc1 v databázi, ve které téměř všechny molekuly mají tato funkce je velmi pomalá. Pro zlepšení rychlosti vyhledávání v takovém scénáři se doporučuje filtrování podle dalších vlastností. Proto byl benchmark opakován s dalším filtrem složeného názvu začínajícím na „ZINC34“.
Tabulka 4 ukazuje přínos optimalizace MDF jako řešení problému odhadu nákladů v kazetě Bingo PostgreSQL. Bez této optimalizace by referenční hodnota měla stejný výkon, jaký je uveden v tabulce 3.
MDF také používá Bingo Kazety podobnost funkce vyhledávání. Jeho výkonnost byla testována hledáním sloučenin se skóre podobnosti 0,9 pomocí míry podobnosti Tanimoto známé také jako Jaccard Index . Výsledky jsou uvedeny v tabulce 5.
Výhled
Pro generování chemická struktura vyobrazení Indigo toolkit se používá. Toolkit může být nakonfigurován tak, aby vytvářet struktury v mnoha způsoby, včetně barvení heteroatomy, dluhopisů délka a šířka a mnoho dalších. V současné době je to pevně zakódováno a uživatel jej nemůže upravit. Dalším krokem by bylo odhalit tyto možnosti konfigurace, aby mohly být nastaveny pomocí souboru vlastností Java. Rovněž musí být prováděna manipulace se solemi a solváty, aby bylo MDF použitelné v oblastech, kde jsou takové sloučeniny důležité.
Chcete – li využít MDF, musíte být schopni programovat v Javě a budete potřebovat základní znalosti o Spring framework a jak jej konfigurovat. To omezuje cílové publikum. Při použití MDF potřebujete napsat nějaký kotel-plech kód, a proto dalším krokem by bylo vytvořit další nástroje pro usnadnění použití MDF, jako je automatické generování tříd entit a jejich úložišť a služeb. Tyto nástroje by musely být konfigurovatelné, aby uživatel mohl definovat požadované vlastnosti pro každou entitu a požadované metody vyhledávání. Možností by byl plugin maven. Maven pluginy mohou generovat kód, jako je vytvoření metamodel provádí querydsl-maven plugin. Další možností by byly anotace, které generují kód při kompilaci jako projekt Lombok .
posledním krokem by bylo vytvoření webové aplikace, platforma, která umožňuje správci vytvořit nové webové aplikace s chemickou strukturu vyhledávací schopnosti jednoduše zadáním požadované vlastnosti pro entity na webový formulář a kliknutím na tlačítko. Je zřejmé, že by to vyžadovalo značné úsilí o rozvoj.