
testovali Jsme různé konfigurace, velikosti objektů, klient a pracovník se počítá s cílem maximalizovat propustnost sedm uzel Ceph clusteru pro malé a velké pracovní vytížení objektu. Jak je uvedeno v prvním příspěvku Ceph clusteru byl postaven za použití jednoho OSD (Object Storage Device) nakonfigurován na HDD, má celkem 112 OSDs za Ceph clusteru. V tomto příspěvku pochopíme špičkový výkon pro různé velikosti objektů a pracovní zatížení.
Poznámka: Termíny „číst“ a HTTP GET se v tomto příspěvku používají zaměnitelně, stejně jako termíny HTTP PUT a “ write.“
velké zatížení objektů
velké zatížení sekvenčních vstupů/výstupů (I/O) je jedním z nejčastějších případů použití pro ukládání objektů Ceph. Tato vysoce výkonná pracovní zatížení zahrnují analýzu velkých dat, zálohování a archivní systémy, ukládání obrázků a streamování zvuku a videa. Pro tyto typy zatížení propustnost (MB / s nebo GB / s) je klíčová metrika, která definuje výkon úložiště.
Jak je znázorněno v Grafu 1 Velký-objekt 100% HTTP GET a HTTP DÁT zátěž vystavoval sub-lineární škálovatelnost při zvyšování počtu RGW hostí. Jako takový jsme měřili ~5.5 GBps agregovanou šířku pásma pro HTTP GET a HTTP PUT pracovní zatížení a zajímavě jsme si nevšimli saturace zdrojů v uzlech clusteru Ceph.
tento cluster může chrlit více, pokud na něj můžeme nasměrovat více zatížení. Takže jsme identifikovali dva způsoby, jak to udělat. 1) Přidat další klientské Uzly 2) Přidat další RGW uzly. Nemohli jsme jít s možností 1, protože jsme byli omezeni fyzickými klientskými uzly dostupnými v této laboratoři. Rozhodli jsme se tedy pro možnost 2 a provedli další kolo testů, ale tentokrát se 14 RGWs.
Jak je znázorněno v Grafu 2, oproti 7 RGW test, 14 RGW test přineslo 14% vyšší napsat výkonu, doplnění na ~6.3 GBps, podobně, HTTP GET vytížení ukázal o 16% vyšší výkon čtení, doplňování ~6.5 GBps. Jednalo se o maximální agregovanou propustnost pozorovanou na tomto clusteru, po které byla zaznamenána saturace médií (HDD), jak je znázorněno na obrázku 1. Na základě výsledků se domníváme, že jsme do tohoto clusteru přidali více uzlů Ceph OSD, výkon mohl být zmenšen ještě dále, dokud nebyl omezen saturací zdrojů.
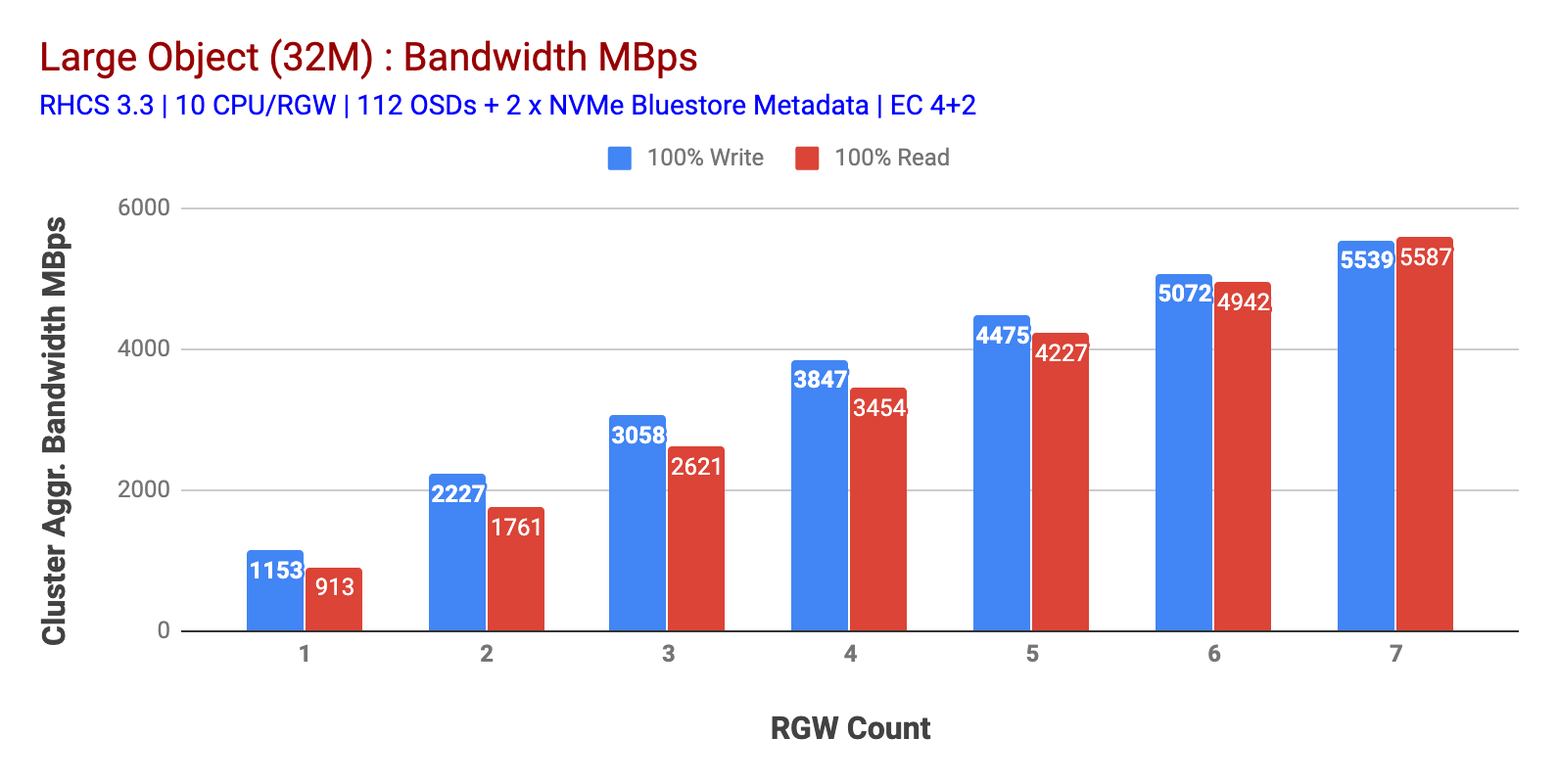
Graf 1: Large Object test,
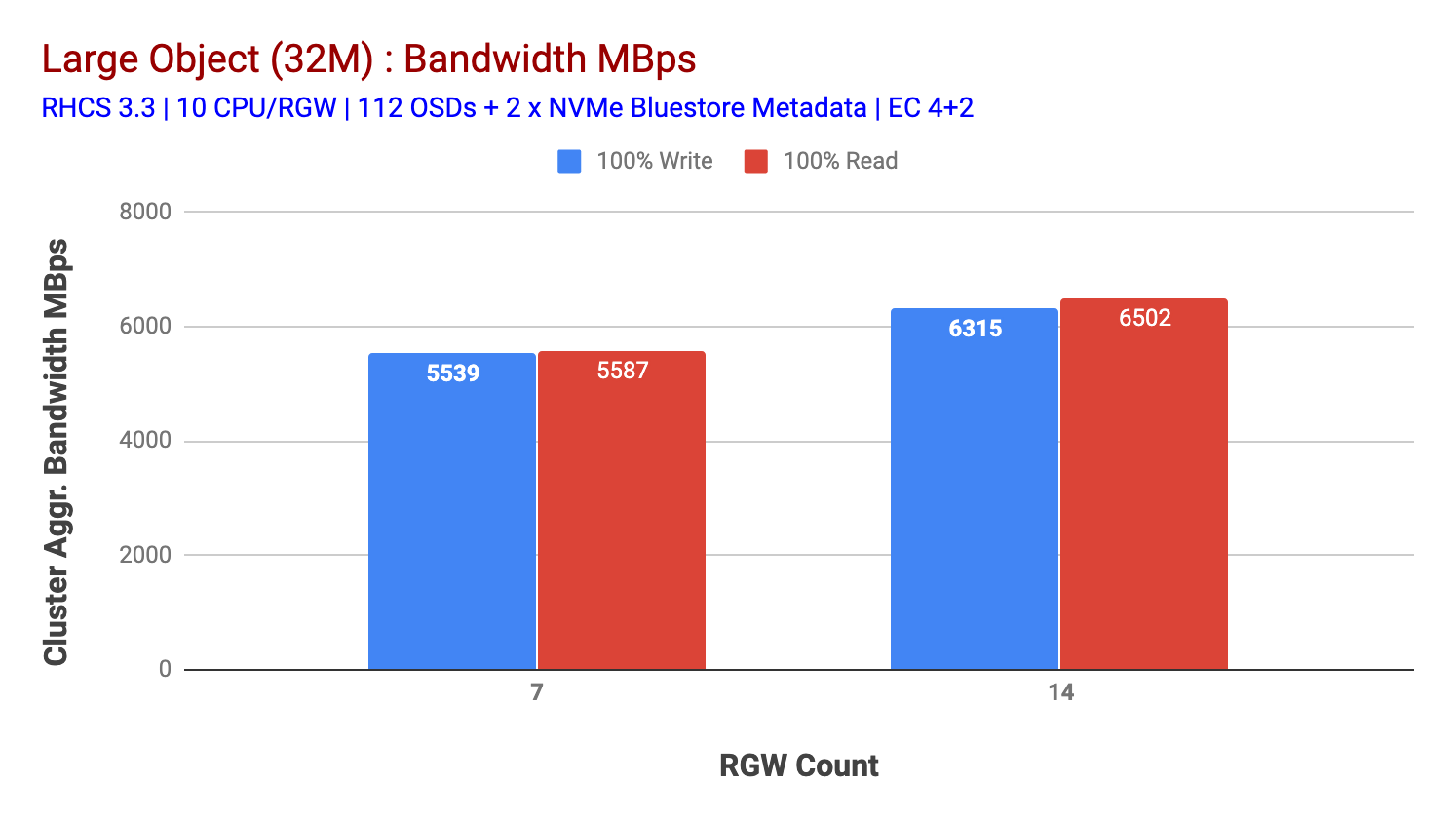
Graf 2: Large Object test s 14 RGWs
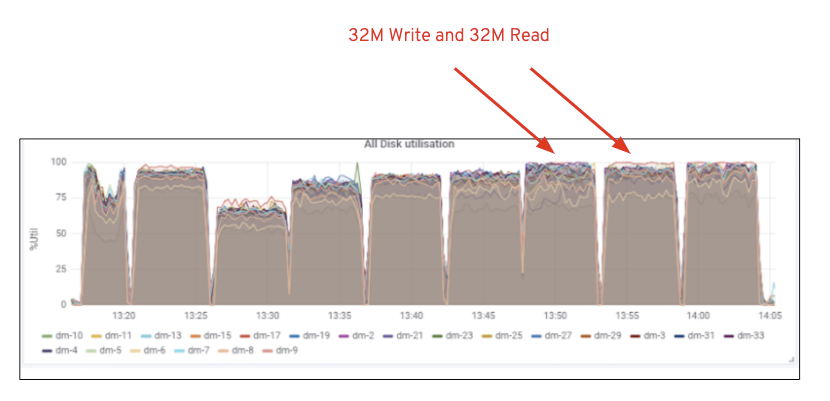
Obrázek 1: Ceph OSD (HDD) mediální využití
Malý Objekt vytížení
Jak je znázorněno v Grafu 3 malý objekt 100% HTTP GET a HTTP PUT pracovní vytížení vystavoval sub-lineární škálovatelnost při zvyšování počtu RGW hostí. Jako takový jsme měřili ~6.2 K Ops propustnost pro HTTP dát na 9MS aplikace zápisu latence a ~3.2 K Ops pro HTTP získat pracovní zatížení s 7 RGW instancí.
Až 7 RGW případech, jsme si nevšiml, zdroje nasycení, takže jsme se zdvojnásobil na RGW případech tím, že škálování těchto 14 a pozorovat zhoršení výkonu pro HTTP PUT pracovní zátěž, která je připsána na mediální saturace, zatímco HTTP GET výkon zmenšen a přikrýval ven na ~4,5 K Ops. Jako takový by výkon zápisu mohl být vyšší, kdybychom přidali více uzlů Ceph OSD. Pokud jde o výkon čtení, věříme, že přidání více klientských uzlů by to mělo zlepšit, ale v laboratoři jsme neměli žádné další fyzické uzly, které by tuto hypotézu otestovaly.
Další zajímavá pozorování z Grafu 3 je snížená průměrná doba odezvy pro HTTP PUT pracovní vytížení, který se zaměřil na 9ms, zatímco HTTP GET ukázal 17ms průměrná čekací doba měřená od aplikace generování zátěže. Jsme přesvědčeni, že jedním z důvodů pro single-místné aplikace latence pro zápis zátěž je kombinace zvyšování výkonnosti vycházející z BlueStore OSD backend, stejně jako vysoký výkon Intel Optane NVMe používá k zadní BlueStore metadata zařízení. Stojí za zmínku, že dosažení průměrné latence zápisu jedné číslice ze systému ukládání objektů je netriviální. Jak je znázorněno v grafu 3, úložiště objektů Ceph při nasazení s backendem BlueStore OSD a Intel Optane pro metadata může dosáhnout propustnosti zápisu při nižší době odezvy.
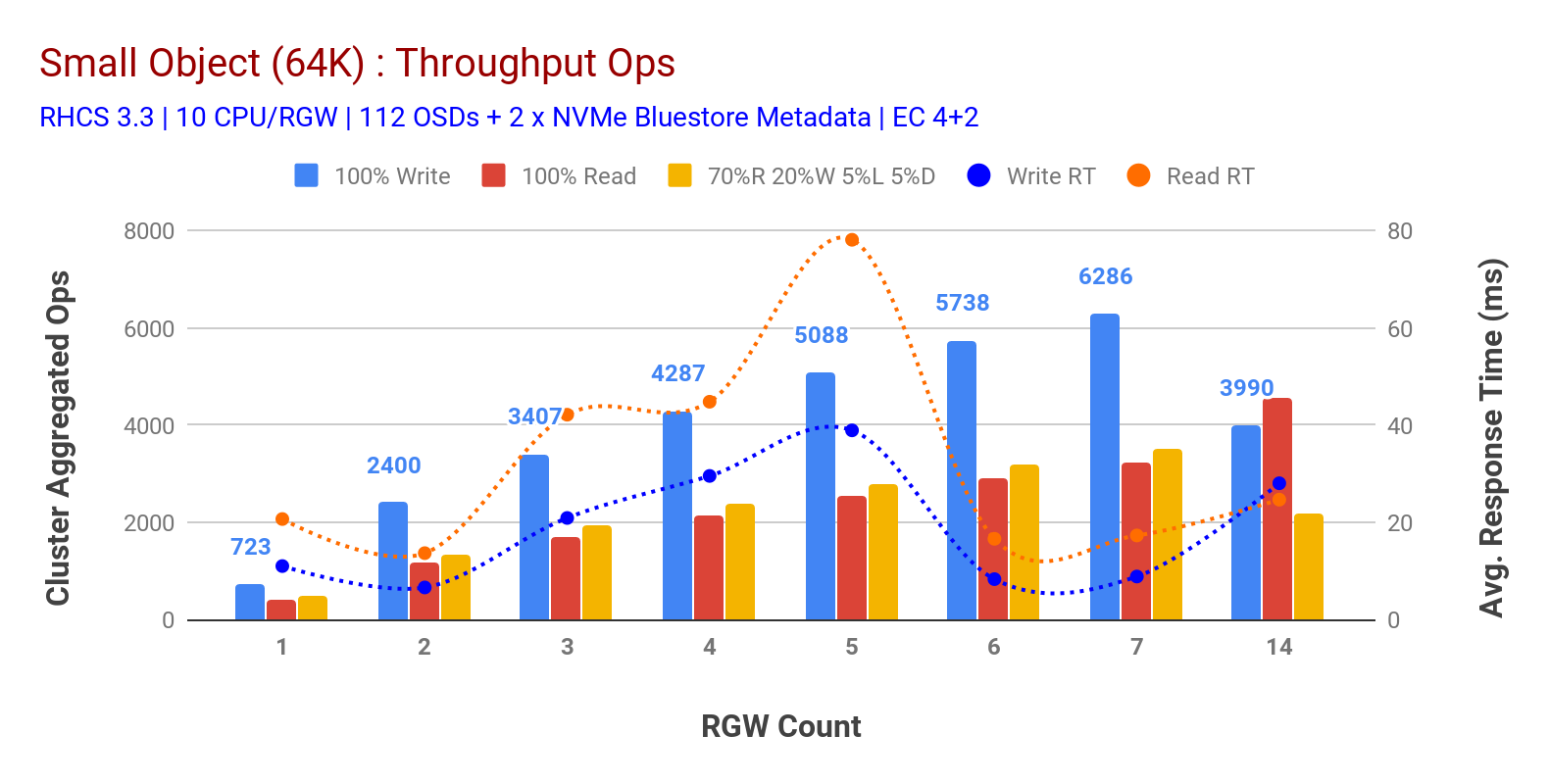
Graf 3: Malý Předmět Test
Shrnutí a další
pevné velikosti clusteru používá v tomto testování byla doručena ~6.3 Gb / s a ~6.5 GBps velký objekt šířky pásma pro zápis a čtení pracovní vytížení, resp. Stejný cluster pro malé velikosti objektu dodala ~6.5 K Ops a ~4.5 K Ops pro zápis a čtení zátěže, resp.
výsledky také ukázaly, že BlueStore OSD v kombinaci s Intel Optane NVMe dodala jednocifernou průměrnou latenci aplikace, což je pro systémy ukládání objektů netriviální. V dalším příspěvku, prozkoumáme výkon spojený s dynamickým štěpením kbelíku a jak může kbelík před střepem pomoci při deterministickém výkonu.